
Tin tức
Llama 2: Tinh chỉnh hiệu quả bằng cách sử dụng Thích ứng xếp hạng thấp (LoRA) trên GPU đơn
Giới thiệu
Với sự tăng trưởng về kích thước tham số và hiệu suất của các mô hình ngôn ngữ lớn (LLM), nhiều người dùng ngày càng quan tâm đến việc điều chỉnh chúng cho phù hợp với trường hợp sử dụng của riêng họ bằng tập dữ liệu riêng của họ. Những người dùng này có thể tìm kiếm trên thị trường một ứng dụng cấp Doanh nghiệp được đào tạo trên kho dữ liệu công cộng lớn và có thể không áp dụng được cho trường hợp sử dụng nội bộ của họ hoặc xem xét sử dụng các mô hình được đào tạo trước nguồn mở rồi tinh chỉnh chúng trên dữ liệu độc quyền của riêng họ. Đảm bảo sử dụng tài nguyên hiệu quả và tiết kiệm chi phí là rất quan trọng khi chọn chiến lược tinh chỉnh mô hình ngôn ngữ lớn và cách tiếp cận thứ hai cung cấp giải pháp tiết kiệm chi phí và có thể mở rộng hơn do nó được đào tạo với dữ liệu đã biết và có thể kiểm soát kết quả của mô hình.
Blog này nghiên cứu cách Thích ứng Thứ hạng Thấp (LoRA) – một kỹ thuật tinh chỉnh tham số hiệu quả – có thể được sử dụng để tinh chỉnh mô hình Llama 2 7B trên một GPU. Chúng tôi đã có thể tinh chỉnh thành công mẫu Llama 2 7B trên một GPU A100 40GB của Nvidia và sẽ cung cấp thông tin chi tiết về cách định cấu hình môi trường phần mềm để chạy quy trình tinh chỉnh trên Dell PowerEdge R760xa có GPU NVIDIA A100.
Công việc này là sự tiếp nối công việc trước đây của chúng tôi , trong đó chúng tôi đã thực hiện thử nghiệm suy luận trên Llama2 7B và chia sẻ kết quả về hiệu suất GPU trong quá trình này.
Tắc nghẽn bộ nhớ
Khi tinh chỉnh bất kỳ LLM nào, điều quan trọng là phải hiểu cơ sở hạ tầng cần thiết để tải và tinh chỉnh mô hình. Khi chúng tôi xem xét tinh chỉnh tiêu chuẩn, trong đó tất cả các tham số được xem xét, nó đòi hỏi sức mạnh tính toán đáng kể để quản lý trạng thái tối ưu hóa và điểm kiểm tra độ dốc. Các trạng thái và độ dốc của trình tối ưu hóa thường dẫn đến dung lượng bộ nhớ lớn hơn khoảng năm lần so với chính mô hình. Nếu chúng tôi xem xét tải mô hình ở fp16 (2 byte cho mỗi tham số), chúng tôi sẽ cần khoảng 84 GB bộ nhớ GPU, như trong hình 1, điều này không thể thực hiện được trên một thẻ A100-40 GB. Do đó, để khắc phục giới hạn dung lượng bộ nhớ này trên một GPU A100, chúng ta có thể sử dụng kỹ thuật tinh chỉnh hiệu quả tham số (PEFT). Chúng tôi sẽ sử dụng một kỹ thuật như vậy được gọi là Thích ứng cấp thấp (LoRA) cho thử nghiệm này.
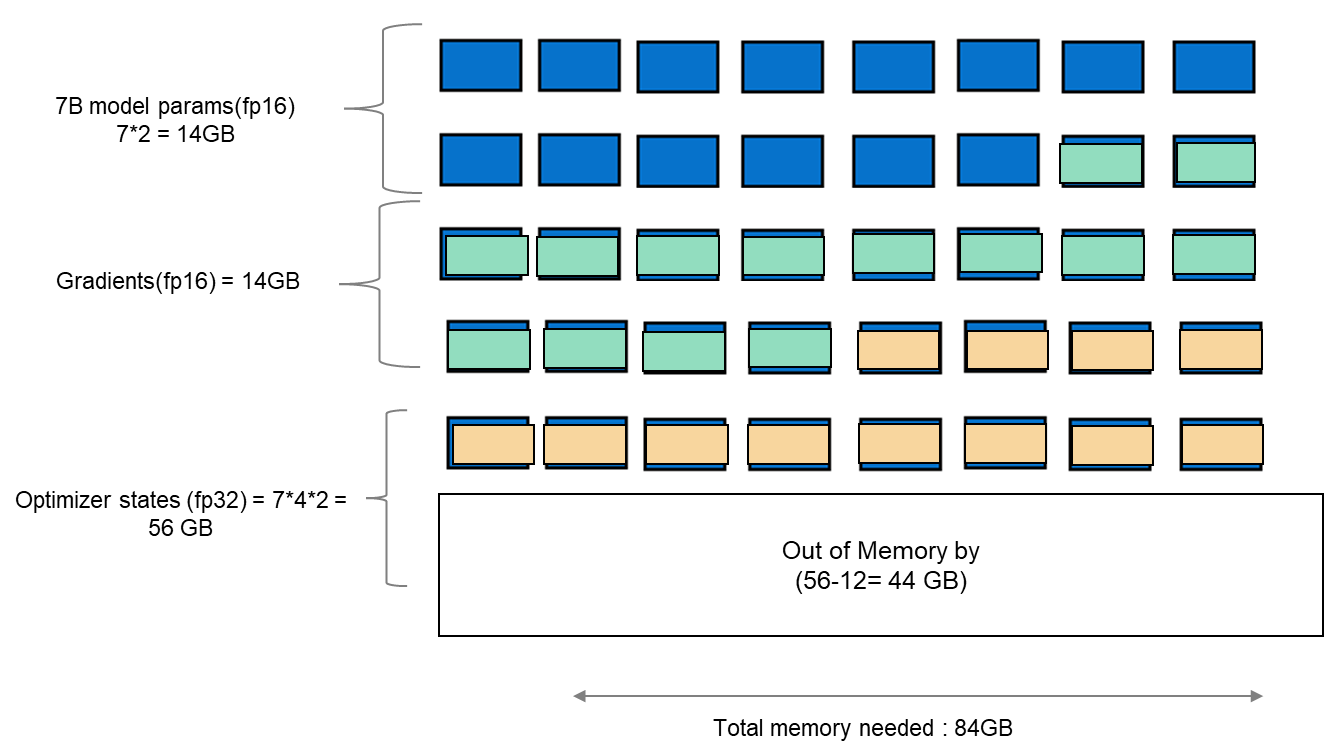
Hình 1. Sơ đồ hiển thị dung lượng bộ nhớ của quá trình tinh chỉnh tiêu chuẩn với mô hình Llama 27B.
Phương pháp tinh chỉnh
LoRA là một phương pháp tinh chỉnh hiệu quả, trong đó thay vì tinh chỉnh tất cả các trọng số cấu thành ma trận trọng số của LLM được huấn luyện trước, nó tối ưu hóa ma trận phân rã thứ hạng của các lớp dày đặc để thay đổi trong quá trình thích ứng. Các ma trận này tạo thành bộ chuyển đổi LoRA. Bộ điều hợp tinh chỉnh này sau đó được hợp nhất với mô hình được đào tạo trước và được sử dụng để suy luận. Số lượng tham số được xác định bởi thứ hạng và hình dạng của các trọng số ban đầu. Trong thực tế, các tham số có thể huấn luyện thay đổi ở mức thấp từ 0,1% đến 1% của tất cả các tham số. Khi số lượng tham số cần tinh chỉnh giảm, kích thước của gradient và trạng thái tối ưu hóa gắn liền với chúng cũng giảm theo. Do đó, kích thước tổng thể của mô hình được tải sẽ giảm. Ví dụ: các tham số mô hình Llama 2 7B có thể được tải bằng int8 (1 byte), với các tham số có thể đào tạo 1 GB được tải trong fp16 (2 byte). Do đó, kích thước của gradient (fp16), trạng thái tối ưu hóa (fp32) và kích hoạt (fp32) tổng hợp thành khoảng 7-9 GB. Điều này giúp tinh chỉnh tổng kích thước của mô hình đã tải lên 15-17 GB, như minh họa trong hình 2.
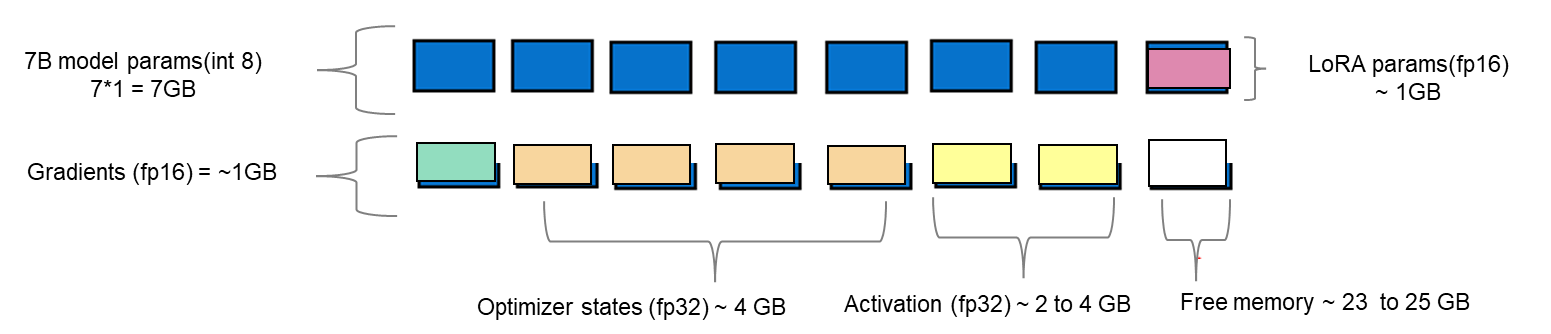
Hình 2. Sơ đồ hiển thị một ví dụ về dung lượng bộ nhớ của tinh chỉnh LoRA với mô hình Llama 2 7B.
Thiết lập thử nghiệm
Đặc tính mô hình cung cấp cho người đọc cái nhìn sâu sắc có giá trị về việc sử dụng bộ nhớ GPU, tổn thất đào tạo và hiệu quả tính toán được đo trong quá trình tinh chỉnh bằng cách thay đổi kích thước lô và quan sát hiện tượng hết bộ nhớ (OOM) cho một tập dữ liệu nhất định. Trong bảng 1, chúng tôi hiển thị hồ sơ tài nguyên khi tinh chỉnh mô hình trò chuyện 7B của Llama 2 bằng kỹ thuật LoRA trên PowerEdge R760xa với 1*A100-40 GB trên tập dữ liệu SAMsum nguồn mở . Để đo các hoạt động dấu phẩy động tera (TFLOP) trên GPU, DeepSpeed Flops Profiler đã được sử dụng. Bảng 1 cung cấp chi tiết về hệ thống được sử dụng cho thí nghiệm này.
Bảng 1. Dung lượng bộ nhớ thực tế của mô hình Llama 27B sử dụng kỹ thuật LoRA trong thử nghiệm của chúng tôi.
| Thông số có thể đào tạo (LoRA) | 0,0042 B (0,06% của mẫu 7B) |
| Thông số mô hình 7B (int8) | 7 GB |
| Bộ chuyển đổi Lora (fp16) | 0,0084 GB |
| Độ dốc (fp32) | 0,0168 GB |
| Trạng thái tối ưu hóa (fp32) | 0,0168 GB |
| Kích hoạt | 2,96GB |
| Tổng bộ nhớ cho kích thước lô 1 | 10 GB = 9,31 GiB |
Cấu hình hệ thông
Trong phần này, chúng tôi liệt kê cấu hình hệ thống phần cứng và phần mềm của máy chủ R760xa PowerEdge được sử dụng trong thử nghiệm này để tinh chỉnh mẫu Llama-2 7B.
Hình 3. Thông số R760XA
Bảng 2. Cấu hình phần cứng và phần mềm của hệ thống
| Thành phần | Chi tiết |
| Phần cứng | |
| Máy chủ tính toán để suy luận | PowerEdge R760xa |
| GPU | GPU Nvidia A100-40GB PCIe CEM |
| Tên mẫu bộ xử lý máy chủ | Intel(R) Xeon(R) Gold 6454S (Sapphire Rapids) |
| Bộ xử lý máy chủ trên mỗi nút | 2 |
| Số lượng lõi của bộ xử lý máy chủ | 32 |
| Tần số bộ xử lý máy chủ | 2,2 GHz |
| Dung lượng bộ nhớ máy chủ | DIMM 512 GB, 16 x 32 GB 4800 MT/s |
| Loại lưu trữ máy chủ | SSD |
| Dung lượng lưu trữ máy chủ | 900GB |
| Phần mềm | |
| Hệ điều hành | Ubuntu 22.04.1 |
| Hồ sơ | DeepSpeed - Trình hồ sơ FLOPs |
| Khung | PyTorch |
| Quản lý gói | Anaconda |
Tập dữ liệu
Bộ dữ liệu SAMsum – kích thước 2,94 MB – bao gồm khoảng 16.000 hàng (Đào tạo, Kiểm tra và Xác thực) các đoạn hội thoại tiếng Anh và bản tóm tắt của chúng. Dữ liệu này được sử dụng để tinh chỉnh mô hình Llama 2 7B. Chúng tôi xử lý trước dữ liệu này ở định dạng lời nhắc được đưa vào mô hình để tinh chỉnh. Ở định dạng JSON, lời nhắc và phản hồi được sử dụng để huấn luyện mô hình. Trong quá trình này, PyTorch sắp xếp dữ liệu theo nhóm (khoảng 10 đến 11 hàng mỗi đợt) và ghép chúng lại. Do đó, tổng cộng 1.555 lô được tạo bằng cách xử lý trước phần phân chia huấn luyện của tập dữ liệu. Các lô này sau đó được chuyển đến mô hình theo từng khối để tinh chỉnh.
Các bước tinh chỉnh
- Tải xuống mô hình Llama 2
- Mô hình này có sẵn từ kho git của Meta hoặc Ôm mặt, tuy nhiên để truy cập mô hình, bạn sẽ cần gửi biểu mẫu đăng ký cần thiết cho thỏa thuận cấp phép Meta AI
- Các chi tiết có thể được tìm thấy trong công việc trước đây của chúng tôi ở đây
- Chuyển đổi mô hình từ kho git của Meta sang loại mô hình Khuôn mặt ôm để sử dụng các thư viện PEFT được sử dụng trong kỹ thuật LoRA
- Sử dụng các lệnh sau để chuyển đổi mô hình
## Cài đặt HuggingFace Transformers từ nguồn pip đóng băng | máy biến áp grep ## xác minh đây là phiên bản 4.31.0 trở lên
git clone git@github.com:huggingface/transformers.gitmáy biến áp cdcài đặt pip protobufpython src/transformers/models/llama/convert_llama_weights_to_hf.py \--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
- Sử dụng các lệnh sau để chuyển đổi mô hình
- Xây dựng môi trường conda và sau đó git sao chép các công thức tinh chỉnh mẫu từ kho git của Meta để bắt đầu
- Chúng tôi đã sửa đổi cơ sở mã để bao gồm trình phân tích hồ sơ Deepspeed flops và nvitop để lập hồ sơ GPU
- Tải tập dữ liệu bằng thư viện bộ nạp dữ liệu của khuôn mặt ôm và nếu cần, hãy thực hiện tiền xử lý
- Nhập các mục nhập tệp cấu hình liên quan đến các phương thức PEFT, tên model, thư mục đầu ra, vị trí lưu mô hình, v.v.
- Sau đây là đoạn mã ví dụ
tàu_config:
model_name: str="path_of_base_hugging_face_llama_model"
run_validation: bool=True
batch_size_training: int=7
num_epoch: int=1
val_batch_size: int=1
tập dữ liệu = "dataset_name"
peft_method: str = "lora"
đầu ra_dir: str = "path_to_save_fine_tuning_model" save_model: bool = True |
6. Chạy lệnh sau để thực hiện tinh chỉnh trên một GPU
python3 llama_finetuning.py --use_peft --peft_method lora --quantization --model_name location_of_hugging_face_model
|
Hình 4 cho thấy tinh chỉnh bằng kỹ thuật LoRA trên 1*A100 (40GiB) với Batch size = 7 trên tập dữ liệu SAMsum, mất 83 phút để hoàn thành.

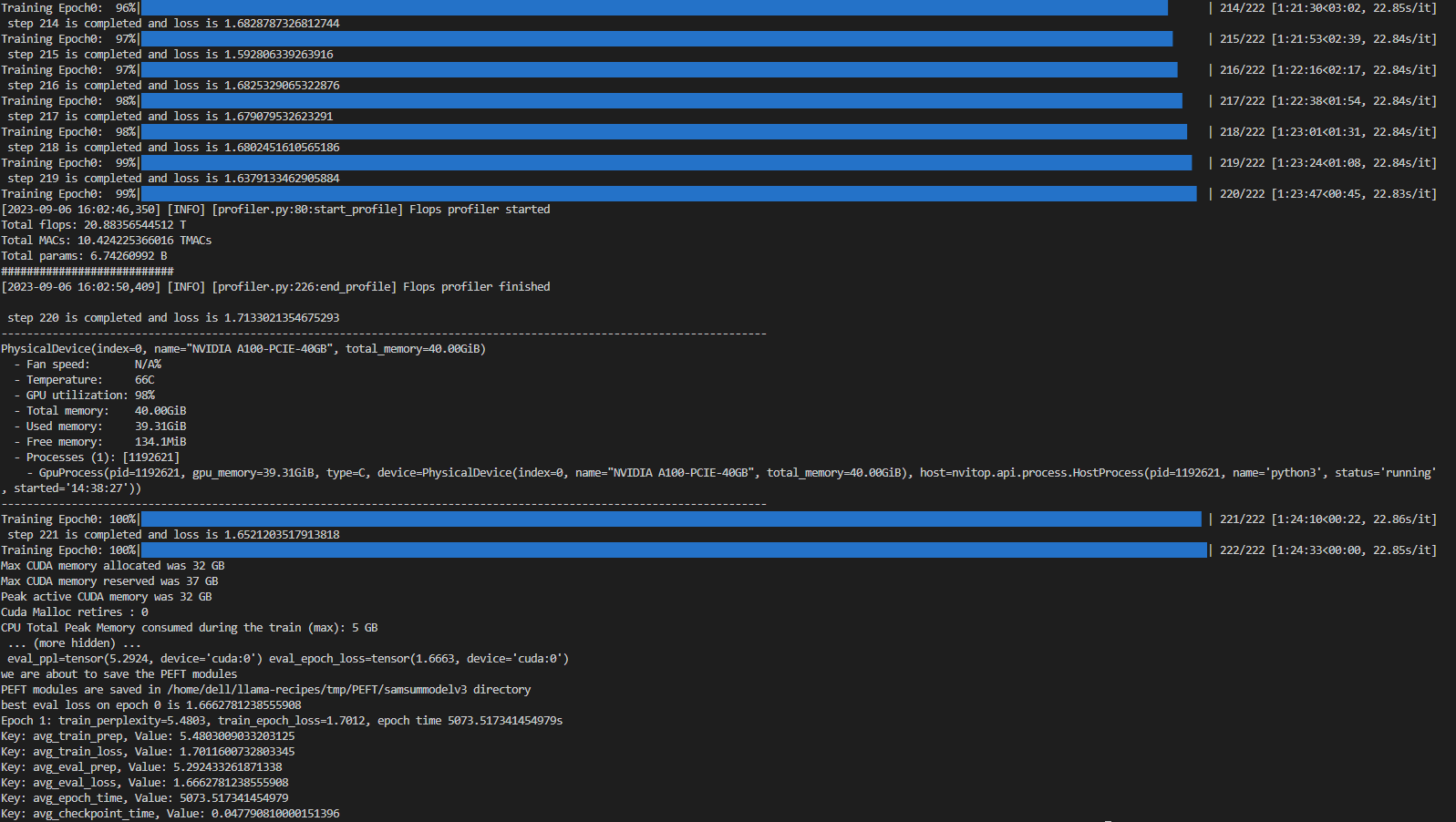
Hình 4. Ảnh chụp màn hình ví dụ về tinh chỉnh LoRA trên tập dữ liệu SAMsum
Kết quả thí nghiệm
Các thử nghiệm tinh chỉnh được chạy ở quy mô lô 4 và 7. Đối với hai tình huống này, chúng tôi đã tính toán tổn thất đào tạo, mức sử dụng GPU và thông lượng GPU. Chúng tôi nhận thấy rằng ở kích thước lô 8, chúng tôi đã gặp phải lỗi hết bộ nhớ (OOM) cho tập dữ liệu đã cho trên 1*A100 với 40 GB.
Khi một đoạn hội thoại được gửi đến mô hình cơ sở 7B, kết quả tóm tắt không chính xác như trong Hình 5. Sau khi tinh chỉnh mô hình cơ sở trên bộ dữ liệu SAMsum, đoạn hội thoại tương tự sẽ đưa ra kết quả tóm tắt phù hợp như trong Hình 6. sự khác biệt trong kết quả cho thấy việc tinh chỉnh đã thành công.
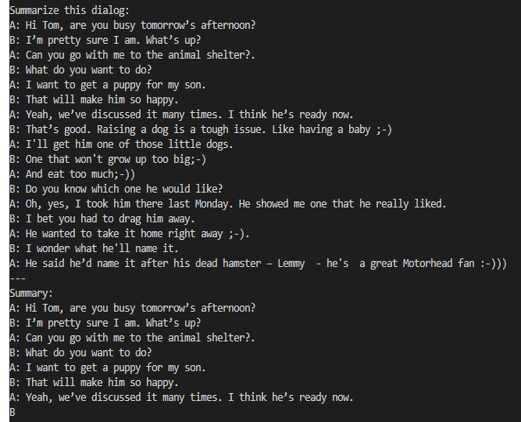
Hình 5. Kết quả tóm tắt từ mô hình cơ sở.
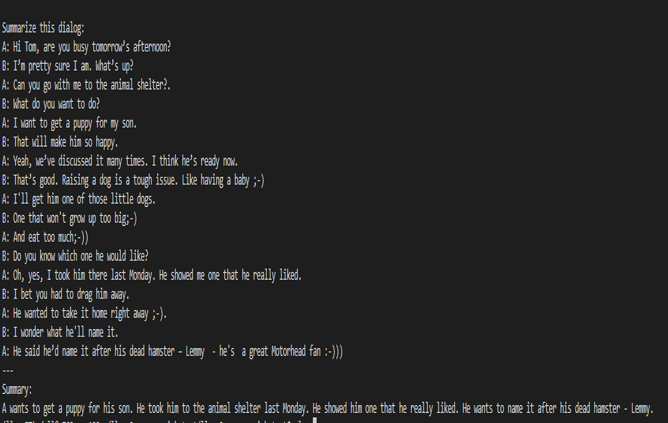
Hình 6. Kết quả tóm tắt từ mô hình tinh chỉnh.
Hình 7 và 8 lần lượt thể hiện tổn thất huấn luyện ở cỡ lô 4 và 7. Chúng tôi nhận thấy rằng ngay cả sau khi tăng quy mô lô lên khoảng 2 lần, hiệu suất huấn luyện mô hình vẫn không giảm.
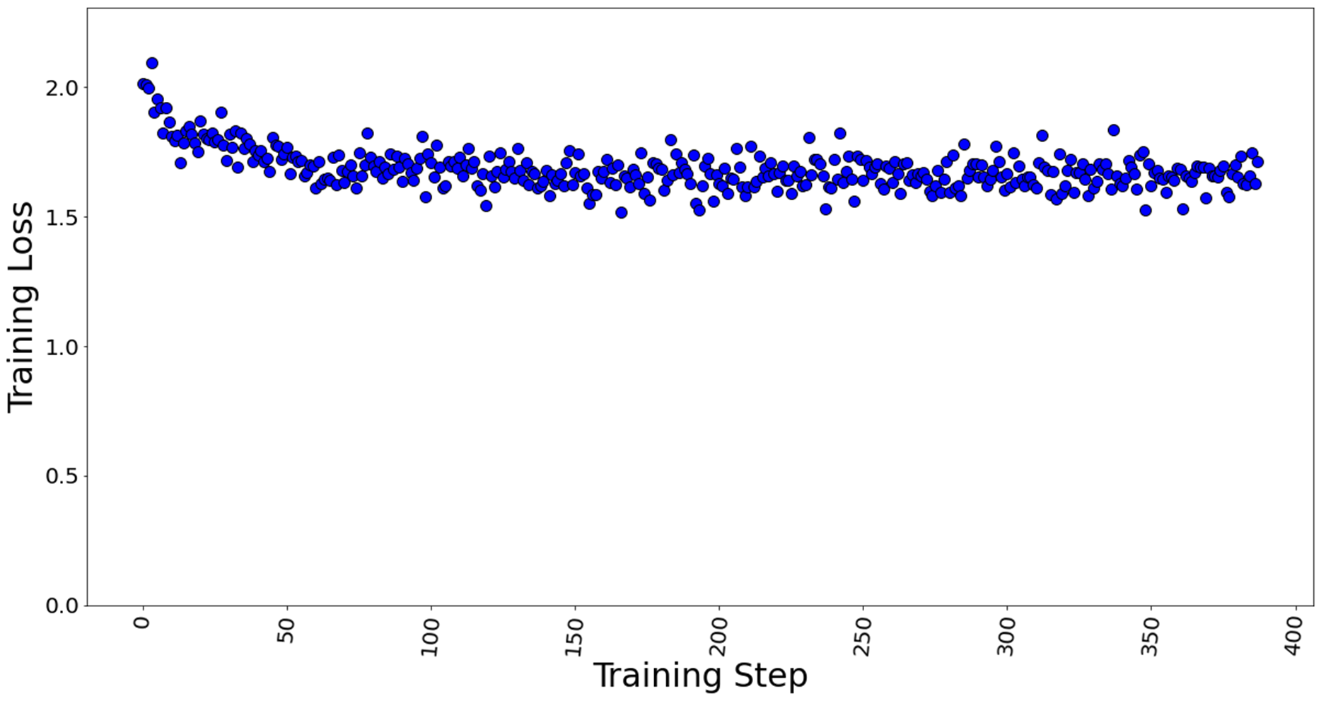
Hình 7. Mất huấn luyện với kích thước lô = 4, tổng cộng 388 bước huấn luyện trong 1 kỷ nguyên.
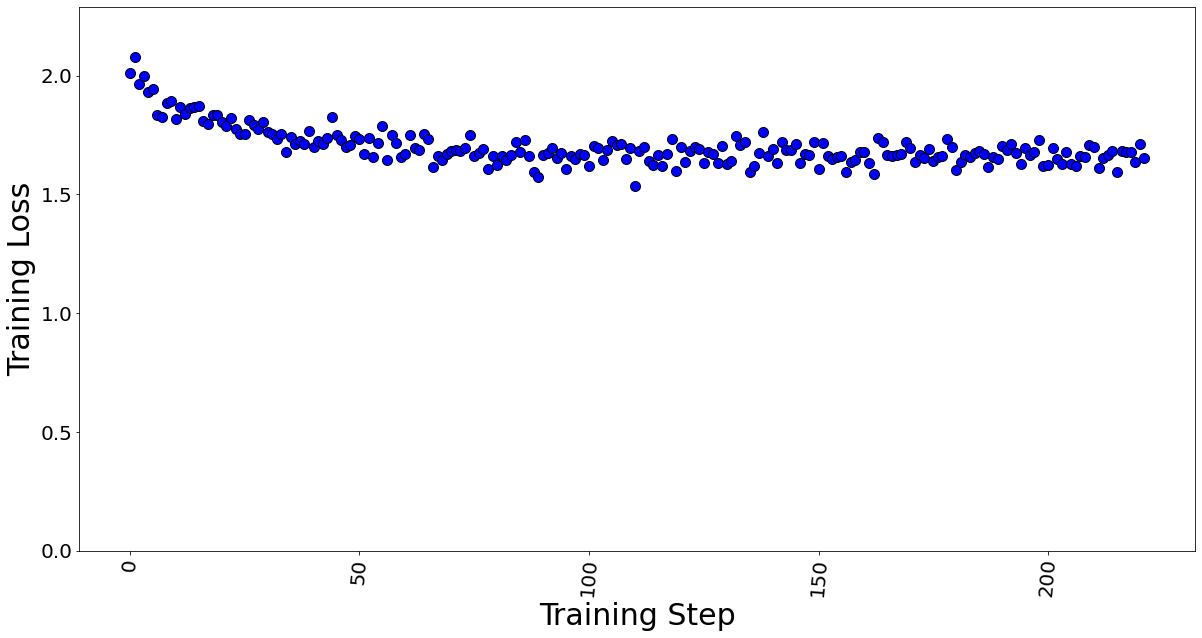
Hình 8. Mất huấn luyện với kích thước lô = 7, tổng cộng 222 bước huấn luyện trong 1 kỷ nguyên.
Việc sử dụng bộ nhớ GPU được ghi lại bằng kỹ thuật LoRA trong Bảng 3. Ở kích thước lô 1, bộ nhớ đã sử dụng là 9,31 GB. Ở kích thước lô 4, bộ nhớ đã sử dụng là 26,21 GB. Ở kích thước lô 7, bộ nhớ được sử dụng là 39,31 GB. Đi xa hơn, chúng tôi thấy OOM ở kích thước lô 8 cho thẻ GPU 40 GB. Việc sử dụng bộ nhớ không đổi trong suốt quá trình tinh chỉnh, như trong Hình 9, và phụ thuộc vào kích thước lô. Chúng tôi đã tính toán bộ nhớ dành riêng cho mỗi lô là 4,302 GB trên 1*A100.
Bảng 3. Việc sử dụng bộ nhớ GPU được ghi lại bằng cách thay đổi mức tối đa. tham số kích thước lô.
| Tối đa. Kích thước lô | Các bước trong 1 kỷ nguyên | Tổng bộ nhớ (GiB) | Bộ nhớ đã sử dụng (GiB) | Bộ nhớ trống (GiB) |
| 1 | 1.555 | 40:00 | 9:31 | 30,69 |
| 4 | 388 | 40:00 | 26,21 | 13,79 |
| 7 | 222 | 40:00 | 39,31 | 0,69 |
| số 8 | Lỗi bộ nhớ | |||
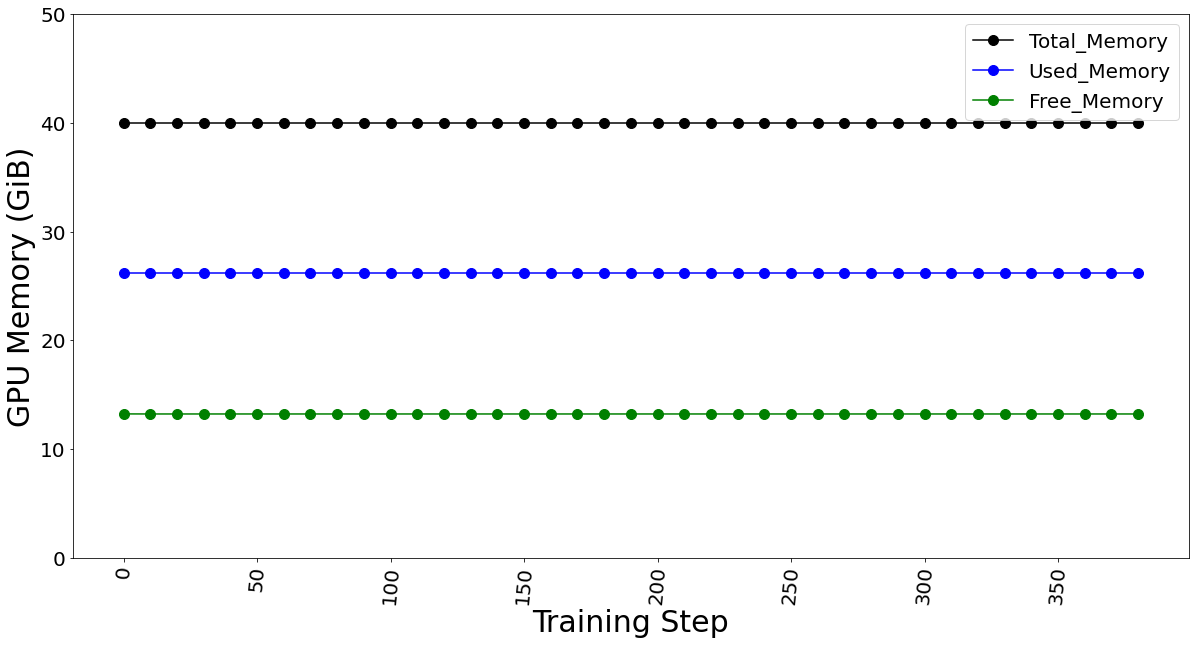
Hình 9. Việc sử dụng bộ nhớ GPU cho kích thước lô 4 (không đổi để tinh chỉnh)
GPU TFLOP được xác định bằng cách sử dụng DeepSpeed Profiler và chúng tôi nhận thấy rằng FLOP thay đổi tuyến tính theo số lượng lô được gửi trong mỗi bước, cho thấy rằng FLOP trên mỗi mã thông báo là không đổi.
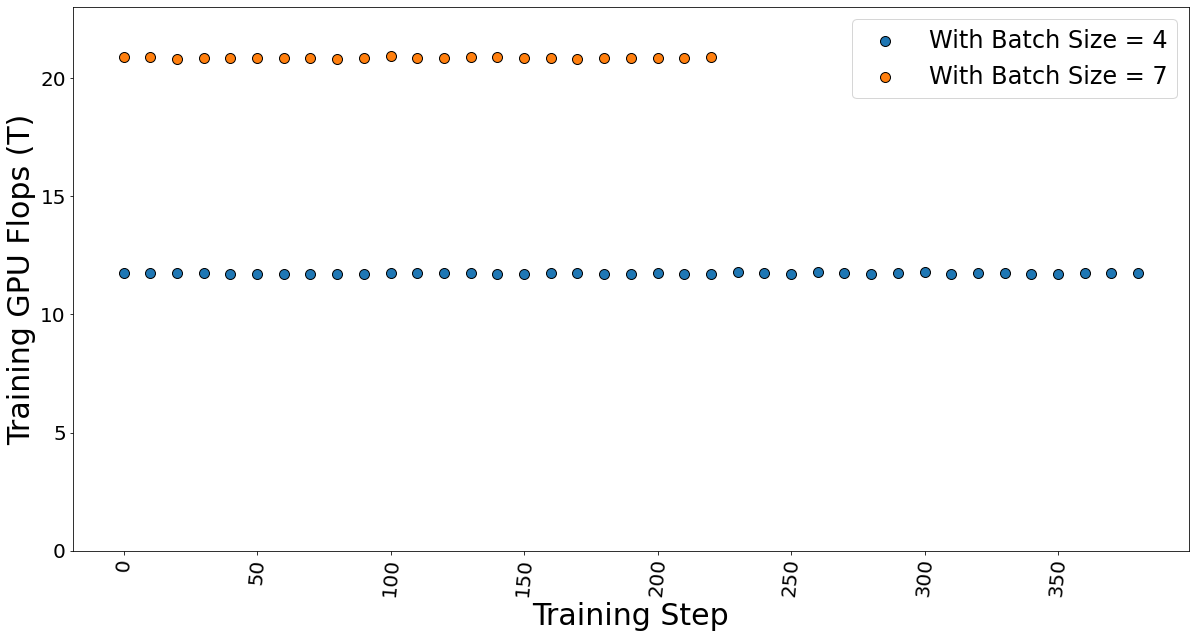
Hình 10. Huấn luyện GPU TFlop cho lô kích thước 4 và 7 trong khi tinh chỉnh mô hình.
Các hoạt động tích lũy đa GPU (MAC), là các hoạt động phổ biến được thực hiện trong các mô hình học sâu, cũng được xác định. Chúng tôi nhận thấy rằng MAC cũng tuân theo sự phụ thuộc tuyến tính vào kích thước lô và do đó không đổi trên mỗi mã thông báo.
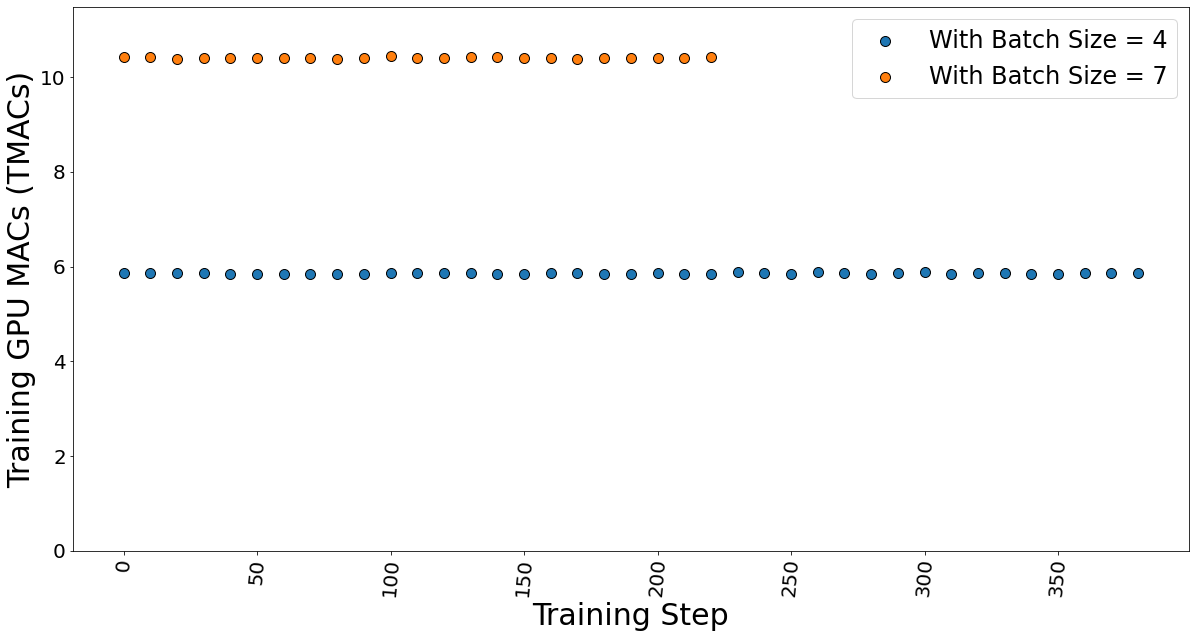
Hình 11. GPU MAC cho lô kích thước 4 và 7 trong khi tinh chỉnh mô hình.
Thời gian cần thiết để tinh chỉnh, còn được gọi là thời gian kỷ nguyên, được đưa ra trong bảng 4. Nó cho thấy thời gian huấn luyện không thay đổi nhiều, điều này củng cố lập luận của chúng tôi rằng FLOP trên mỗi mã thông báo là không đổi. Do đó, tổng thời gian đào tạo không phụ thuộc vào kích thước lô.
Bảng 4. Dữ liệu hiển thị thời gian thực hiện quá trình tinh chỉnh.
| Tối đa. Kích thước lô | Các bước trong 1 kỷ nguyên | Thời gian kỷ nguyên (giây) |
| 4 | 388 | 5.003 |
| 7 | 222 | 5.073 |
Kết luận và kiến nghị
- Chúng tôi cho thấy rằng việc sử dụng kỹ thuật PEFT như LoRA có thể giúp giảm yêu cầu bộ nhớ để tinh chỉnh mô hình ngôn ngữ lớn trên tập dữ liệu độc quyền. Trong trường hợp của chúng tôi, chúng tôi sử dụng Dell PowerEdge R760xa có GPU NVIDIA A100-40GB để tinh chỉnh mẫu Llama 2 7B.
- Chúng tôi khuyên bạn nên sử dụng kích thước lô thấp hơn để giảm thiểu việc phân bổ bộ nhớ tự động, có thể được sử dụng trong trường hợp tập dữ liệu lớn hơn. Chúng tôi đã chỉ ra rằng kích thước lô thấp hơn không ảnh hưởng đến thời gian đào tạo cũng như hiệu suất đào tạo.
- Dung lượng bộ nhớ cần thiết để tinh chỉnh mẫu Llama 2 7B đã giảm từ 84GB xuống mức vừa vặn với thẻ 1*A100 40 GB bằng cách sử dụng kỹ thuật LoRA.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...