
Các nhóm phải đối mặt với thách thức cung cấp hình ảnh chất lượng cao, độc đáo một cách nhanh chóng và hiệu quả. Tuy nhiên, việc tạo ra những hình ảnh này thường đòi hỏi nhiều tài nguyên, đặc biệt là khi sử dụng các công cụ truyền thống hoặc các mô hình lớn như Stable Diffusion. Điều này thường có nghĩa là người sáng tạo dựa vào các dịch vụ đám mây để tạo hình ảnh, nhưng điều này lại gây ra những hạn chế như không thể tích hợp thông tin độc quyền, chi phí trả trước cho dịch vụ đám mây và giới hạn về khả năng cá nhân hóa hình ảnh. Ngược lại, việc tạo hình ảnh cục bộ trên máy tính để bàn mang lại sự linh hoạt và kiểm soát chi phí tốt hơn, bao gồm việc tạo hình ảnh không giới hạn mà không làm tăng chi phí.
LoRA (Low-Rank Adaptation) , một phương pháp giúp việc tinh chỉnh các mô hình lớn dễ dàng và dễ tiếp cận hơn, có thể giúp cải thiện quy trình làm việc. LoRA giảm tải tính toán và thời gian cần thiết để điều chỉnh các mô hình cho các tác vụ cụ thể, cho phép bạn huấn luyện các mô hình tùy chỉnh từ thiết lập PC của riêng mình.
Trong blog này, chúng ta sẽ khám phá cách thức hoạt động của LoRA, lý do tại sao nó đặc biệt phù hợp để tạo văn bản thành hình ảnh và cách ghép nối nó với phần cứng phù hợp, như máy trạm Dell Pro Max và GPU NVIDIA RTX PRO, có thể thay đổi cách các doanh nghiệp tiếp cận việc tạo hình ảnh.
LoRA là gì và tại sao nó lại quan trọng đối với việc tạo văn bản thành hình ảnh?
LoRA được thiết kế để tinh chỉnh các mô hình lớn, đã được đào tạo trước một cách hiệu quả hơn bằng cách tối ưu hóa cách điều chỉnh các tham số mô hình. Thay vì tính toán lại tất cả các tham số (vốn tốn kém về mặt tính toán), LoRA chỉ điều chỉnh một tập hợp con các tham số, tập trung vào phân tích ma trận bậc thấp . Nhờ đó, thời gian và tài nguyên cần thiết để đào tạo mô hình được rút ngắn, giúp nó trở nên thiết thực hơn nhiều cho các tác vụ sáng tạo.
Tại sao LoRA hoạt động tốt trong việc tạo văn bản thành hình ảnh:
- Độ chính xác toán học : Đối với các mô hình chuyển đổi văn bản sang hình ảnh như Stable Diffusion , LoRA sử dụng phương pháp phân tích bậc thấp để biểu diễn tổng không gian trọng số thành hai ma trận nhỏ hơn (bậc thấp). Điều này duy trì độ chính xác toán học nhưng cũng giảm gánh nặng tính toán tổng thể của phép tính.
- Lặp lại nhanh hơn : Đối với những ai am hiểu về ký hiệu Big-O, LoRA rút gọn phép tính O(d^2) thành O(dr), trong đó “r” (hạng) nhỏ hơn đáng kể so với “d” (tổng số tham số cần cập nhật). Ví dụ: nếu bạn có một ma trận có kích thước 1000 x 1000, LoRA có thể chia nhỏ 1.000.000 tham số thành các ma trận 1000 x 2 và 2 x 1000, giảm không gian tham số xuống còn 4.000, tức là ít hơn 25 lần, đồng nghĩa với việc bạn có thể lặp lại nhanh hơn.
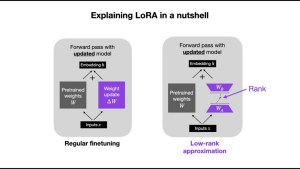
Tùy chỉnh tiết kiệm chi phí : Các quy trình tinh chỉnh truyền thống có thể rất tốn kém, cả về thời gian lẫn tài nguyên tính toán. Hiệu quả của LoRA giúp giảm thiểu những chi phí này, giúp các nhóm nhỏ dễ dàng tận dụng các mô hình AI tiên tiến mà không cần đầu tư vào cơ sở hạ tầng tốn kém.
Ứng dụng thực tế: hợp lý hóa quy trình làm việc với các công cụ như GUI của Kohya
Nhưng nhiều người trong chúng ta đã nghe về các kỹ thuật học máy “giúp học máy trở nên khả dụng”. Tôi nhớ lần đầu tiên nghe về các lớp chú ý chéo trong LLM và nghĩ rằng mình có thể tự xây dựng ChatGPT tại địa phương, nhưng rồi nhận ra rằng quá trình thiết lập và đào tạo tốn nhiều thời gian và nguồn lực hơn tôi nghĩ.
May mắn thay, trong trường hợp LoRA, có những công cụ thiết thực như GUI của Kohya giúp đơn giản hóa quy trình. GUI của Kohya cung cấp giao diện thân thiện với người dùng để tinh chỉnh các mô hình lớn như Stable Diffusion , ngay cả với những người không có chuyên môn kỹ thuật sâu.
Giao diện người dùng đồ họa (GUI) của Kohya cho phép người dùng:
- Tải và sửa đổi mô hình : Tải lên mô hình đã được đào tạo trước, áp dụng LoRA và điều chỉnh các thông số cho các tác vụ cụ thể.
- Chạy tinh chỉnh : Tinh chỉnh mô hình nhanh chóng và hiệu quả chỉ với vài cú nhấp chuột đơn giản.
- Chuyển đổi tác vụ hiệu quả : Giao diện cho phép chuyển đổi tác vụ dễ dàng. Các nhóm có thể tạo hình ảnh sản phẩm, hình ảnh tiếp thị hoặc các tài sản khác mà không cần phải cấu hình lại toàn bộ thiết lập.
Hướng dẫn cài đặt GUI của Kohya (cài đặt windows)
Để biết hướng dẫn chi tiết về cách thiết lập GUI của Kohya, hãy làm theo các bước trên github của họ . Nếu bạn đang sử dụng nền tảng Windows, bạn có thể làm theo các bước sau:
- Cài đặt Dependencies : Tải xuống và cài đặt phiên bản Python mới nhất từ trang web chính thức của Python , cài đặt CUDA Toolkit , cài đặt git .
- Sao chép Kho lưu trữ Kohya : Mở Dấu nhắc lệnh và chạy:

- Cài đặt Dependencies : Điều hướng đến thư mục nơi bạn đã sao chép kho lưu trữ và cài đặt các gói cần thiết:
- Chạy tập lệnh Thiết lập:
- Khởi chạy GUI : Cuối cùng, chạy lệnh sau để mở giao diện đồ họa:

Tại sao phần cứng lại quan trọng đối với quy trình làm việc LoRA
Sau khi đã tìm hiểu về cách thức hoạt động của LoRA và cách thiết lập các công cụ phần mềm như GUI của Kohya , điều quan trọng là phải xem xét điều gì làm cho các quy trình làm việc này hoạt động hiệu quả. Mặc dù LoRA giảm tải tính toán tổng thể so với các phương pháp tinh chỉnh truyền thống, chúng ta vẫn cần thiết lập phần cứng phù hợp để tận dụng tối đa hiệu quả của nó, đặc biệt là khi xử lý các mô hình lớn hơn như Stable Diffusion hoặc làm việc với việc tạo ảnh có độ phân giải cao.
Việc cân nhắc đúng đắn về phần cứng cho LoRA và việc tạo hình ảnh nói chung phụ thuộc vào một số thành phần chính: bộ xử lý đa luồng, sức mạnh GPU và bộ nhớ truy cập nhanh với đủ bộ nhớ để hỗ trợ các tập dữ liệu lớn.
Bộ xử lý đa luồng đóng vai trò quan trọng bằng cách phân bổ tác vụ trên nhiều lõi. Trong hầu hết các nền tảng AI như PyTorch và TensorFlow, tính song song được tích hợp rất nhiều vào mã nguồn. Điều này có nghĩa là nếu bạn có nhiều luồng, khối lượng công việc xử lý lượng dữ liệu khổng lồ sẽ được chia nhỏ thành các tác vụ con để máy tính của bạn chạy trên các lõi riêng biệt. Máy trạm Dell Pro Max có thể được cấu hình với CPU cao cấp cho phép tối ưu hóa.
Trong khi đó, GPU phụ thuộc rất nhiều vào các phép tính ma trận. Những phép tính này có thể mất hàng giờ, thậm chí hàng ngày, chỉ riêng với CPU. Nhưng với GPU NVIDIA RTX PRO Blackwell , chúng được thiết kế để xử lý những loại tải tính toán này, giảm đáng kể thời gian cần thiết để có kết quả từ vài giờ xuống chỉ còn vài phút.
Cuối cùng, bộ nhớ thường là một điểm nghẽn khiến các nhà phát triển e ngại khi thiết lập cục bộ. Việc đào tạo các mô hình lớn thường đòi hỏi phải xử lý các tập dữ liệu lớn, điều này có thể làm chậm hệ thống nếu bạn liên tục chờ dữ liệu tải. Các tùy chọn như NVIDIA RTX 6000 Ada Generation cung cấp 48GB VRAM, và thiết lập GPU kép có thể lên đến 96GB. Bộ nhớ GPU mở rộng này cho phép làm việc với các mô hình lớn hơn và hình ảnh có độ phân giải cao hơn mà không cần chuyển sang bộ nhớ hệ thống chậm hơn.
Lưu trữ nhanh, chẳng hạn như SSD PCIe NVMe , đảm bảo bạn có thể truy cập nhanh chóng vào các tập dữ liệu đó. Hơn nữa, có các tùy chọn để cấu hình bộ nhớ ECC lên đến 1TB, giúp bộ nhớ dễ dàng truy cập hơn khi đặt gần các đơn vị tính toán của bạn.
Với suy nghĩ đó, đây là ba cấu hình cần cân nhắc dựa trên khối lượng công việc cụ thể của bạn:
- Cấp độ cơ bản : Dành cho những người mới bắt đầu hoặc làm việc với các mẫu máy nhỏ hơn, Dell Pro Max Tower T2 cung cấp hiệu suất luồng đơn mạnh mẽ với GPU NVIDIA RTX PRO 6000 Blackwell , mang đến cho bạn nền tảng vững chắc để chạy tinh chỉnh LoRA cục bộ.
- Trung cấp : Khi mô hình của bạn phát triển hoặc nhóm của bạn bắt đầu xử lý các lần lặp thường xuyên hơn, Precision 5860 Tower mang đến hiệu suất có thể mở rộng trong một tháp cỡ trung, với GPU NVIDIA RTX 5000 và 6000 Ada Generation . Thiết lập này nâng cấp khả năng tính toán của CPU và GPU để bạn có thể xử lý các tập dữ liệu lớn hơn và các mô hình phức tạp hơn.
- Nâng cao : Cuối cùng, Precision 7875 Tower với bộ xử lý AMD Ryzen Threadripper PRO và GPU NVIDIA RTX 6000 Ada Generation được thiết kế để xử lý khối lượng công việc nặng. Cấu hình này được thiết kế cho các nhóm chạy mô hình quy mô lớn và các quy trình phức tạp, nhiều lần lặp, cho phép bạn xử lý các tác vụ AI phức tạp nhất mà vẫn tận dụng được sức mạnh của CPU/GPU và bộ nhớ hàng đầu.
Tại sao LoRA là lựa chọn thiết thực cho các nhóm sáng tạo
Trong bối cảnh cạnh tranh ngày nay, khả năng cung cấp hình ảnh nhanh hơn, thông minh hơn và tùy chỉnh hơn mang lại cho doanh nghiệp lợi thế vượt trội. LoRA mang đến sự linh hoạt, hiệu quả và khả năng mở rộng cần thiết để giúp các đội ngũ sáng tạo luôn dẫn đầu, mà không cần đường cong học tập khó khăn hay yêu cầu tài nguyên nặng nề thường đi kèm với tích hợp AI.
Bằng cách tích hợp các công cụ như GUI của Kohya , LoRA có thể dễ dàng tích hợp vào quy trình làm việc hiện có, ngay cả đối với các nhóm không có chuyên môn kỹ thuật sâu. Và khi kết hợp với các giải pháp phần cứng đáng tin cậy như máy trạm Dell Pro Max và GPU NVIDIA RTX PRO , các nhóm sáng tạo có thể tận hưởng hiệu suất được cải thiện mà không cần phải sử dụng quá nhiều tài nguyên.
Bạn đã sẵn sàng tối ưu hóa quy trình chuyển văn bản thành hình ảnh chưa?
Khám phá cách ghép nối LoRA với máy trạm Dell Pro Max và GPU NVIDIA RTX PRO cho phép tạo nội dung nhanh hơn, linh hoạt hơn, từ việc tinh chỉnh các mô hình Stable Diffusion đến việc cung cấp hình ảnh tùy chỉnh theo yêu cầu.



Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...