
Tin tức
Mở rộng khối lượng công việc Deep Learning trong môi trường ảo hóa tăng tốc GPU
Giới thiệu
Nhu cầu đào tạo tính toán, song song và phân tán ngày càng tăng trong lĩnh vực học sâu (DL). Việc giới thiệu các mô hình ngôn ngữ quy mô lớn như Megatron-Turing NLG (530 tỷ tham số; xem Tài liệu tham khảo 1 bên dưới) nêu bật sự cần thiết của các kỹ thuật mới hơn để xử lý tính song song trong đào tạo mô hình quy mô lớn. Kết quả ấn tượng từ mô hình máy biến áp bằng ngôn ngữ tự nhiên đã mở đường cho các nhà nghiên cứu áp dụng mô hình máy biến áp trong thị giác máy tính. Mô hình ViT-Huge (632 triệu tham số; xem Tài liệu tham khảo 2 bên dưới) , sử dụng một biến áp thuần túy áp dụng cho các bản vá hình ảnh, đạt được kết quả đáng kinh ngạc trong các nhiệm vụ phân loại hình ảnh so với các mạng thần kinh tích chập hiện đại.
Các mô hình DL lớn hơn đòi hỏi nhiều thời gian huấn luyện hơn để đạt được sự hội tụ. Ngay cả các mô hình nhỏ hơn như EffientNet (43 triệu tham số; xem Tài liệu tham khảo 3 bên dưới) và EfficiencyNetV2 (24 triệu tham số; xem Tài liệu tham khảo 3 bên dưới) cũng có thể mất vài ngày để đào tạo tùy thuộc vào kích thước dữ liệu và tính toán được sử dụng. Những kết quả này cho thấy rõ sự cần thiết phải đào tạo các mô hình trên nhiều nút điện toán bằng GPU để giảm thời gian đào tạo. Các nhà khoa học dữ liệu và kỹ sư máy học có thể hưởng lợi bằng cách phân phối việc đào tạo mô hình DL trên nhiều nút. Thiết kế được xác thực của Dell cho AI cho thấy cơ sở hạ tầng được xác định bằng phần mềm với GPU ảo hóa có hiệu suất cao như thế nào và phù hợp với khối lượng công việc AI (Trí tuệ nhân tạo). Các khối lượng công việc AI khác nhau yêu cầu kích thước tài nguyên khác nhau, cách ly tài nguyên, sử dụng GPU và cách tốt hơn để mở rộng quy mô trên nhiều nút để xử lý khối lượng công việc DL chuyên sâu về điện toán.
Blog này trình bày cách sử dụng và hiệu suất trên nhiều cài đặt khác nhau, chẳng hạn như khối lượng công việc đa nút và đa GPU trên máy chủ Dell PowerEdge với GPU NVIDIA và VMware vSphere.
Chi tiết hệ thống
Bảng sau đây cung cấp thông tin chi tiết về hệ thống:
Bảng 1: Chi tiết hệ thống
| Thành phần | Chi tiết |
| Máy chủ | Dell PowerEdge R750xa (Hệ thống được NVIDIA chứng nhận) |
| Bộ xử lý | 2 x CPU Intel Xeon Gold 6338 @ 2,00 GHz |
| GPU | 4 x NVIDIA A100 PCIe |
| Bộ điều hợp mạng | Mellanox ConnectX-6 Cổng kép 100 GbE |
| Kho | Dell PowerScale |
| Phiên bản ESXi | 7.0.3 |
| Phiên bản sinh học | 1.1.3 |
| Phiên bản trình điều khiển GPU | 470.82.01 |
| Phiên bản CUDA | 11.4 |
Thiết lập cho các thử nghiệm đa nút
Để đạt được hiệu suất tốt nhất cho hoạt động đào tạo phân tán, chúng ta cần thực hiện các bước cấp cao sau khi máy chủ ESXi và máy ảo (VM) được tạo:
- Kích hoạt Dịch vụ dịch địa chỉ (ATS) trên VMware ESXi và VM để cho phép truyền ngang hàng (P2P) với hiệu suất cao.
- Kích hoạt ATS trên NIC ConnectX-6.
- Sử dụng tiện ích ibdev2netdev để hiển thị thẻ Mellanox ConnectX-6 đã cài đặt và ánh xạ giữa các cổng logic và vật lý, đồng thời kích hoạt các cổng được yêu cầu.
- Tạo vùng chứa Docker với trình điều khiển Mellanox OFED, Thư viện MPI mở và TensorFlow được tối ưu hóa NVIDIA (khung DL được sử dụng trong các thử nghiệm hiệu suất sau).
- Thiết lập đăng nhập SSH không cần chìa khóa giữa các máy ảo.
- Khi định cấu hình nhiều GPU trong VM, hãy kết nối các GPU với NVLINK.
Đánh giá hiệu suất
Để đánh giá, chúng tôi đã sử dụng máy ảo có 32 CPU, bộ nhớ 64 GB và GPU (tùy thuộc vào thử nghiệm). Việc đánh giá hiệu suất đào tạo (thông lượng) dựa trên các tình huống sau:
- Kịch bản 1—Một nút có nhiều máy ảo và đào tạo mô hình đa GPU
- Kịch bản 2—Đào tạo mô hình đa nút (đào tạo phân tán)
cảnh 1
Hãy tưởng tượng trường hợp có nhiều nhà khoa học dữ liệu làm việc để xây dựng và đào tạo các mô hình khác nhau. Điều quan trọng là phải cách ly nghiêm ngặt các tài nguyên được chia sẻ giữa các nhà khoa học dữ liệu để chạy các thử nghiệm tương ứng của họ. Các nhà khoa học dữ liệu có thể sử dụng các tài nguyên sẵn có hiệu quả như thế nào?
Hình sau đây hiển thị một số thử nghiệm trên một nút có bốn GPU và kết quả hiệu suất. Đối với mỗi thử nghiệm này, chúng tôi chạy tf_cnn_benchmarks với mô hình ResNet50 với kích thước lô 1024 bằng cách sử dụng dữ liệu tổng hợp.
Lưu ý : GPU NVIDIA A100 hỗ trợ kết nối cầu NVLink với GPU NVIDIA A100 liền kề. Do đó, số lượng GPU tối đa được thêm vào một VM cho các thử nghiệm đa GPU trên máy chủ Dell PowerEdge R750xa là hai.
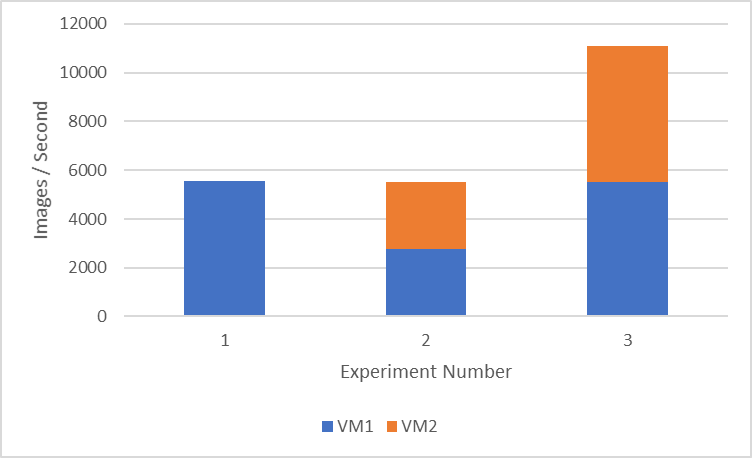
Hình 1: So sánh hiệu suất của nhiều VM và nhiều GPU trên một nút
Hình 1 cho thấy thông lượng (trung bình trên ba lần chạy) của ba thiết lập thử nghiệm khác nhau:
- Thiết lập 1 bao gồm một VM duy nhất có hai GPU. Thiết lập này có thể hữu ích khi chạy khối lượng công việc máy học vốn cần nhiều GPU hơn để đào tạo nhanh hơn (5500 hình ảnh/giây) nhưng vẫn cho phép các tài nguyên còn lại trong nút có sẵn để các nhà khoa học dữ liệu khác sử dụng.
- Thiết lập 2 bao gồm hai máy ảo với một GPU. Chúng tôi nhận được khoảng 2700 hình ảnh/giây trên mỗi VM, điều này có thể hữu ích khi chạy nhiều thử nghiệm tìm kiếm siêu tham số nhằm tinh chỉnh mô hình.
- Thiết lập 3 bao gồm hai máy ảo với hai GPU mỗi máy. Chúng tôi sử dụng tất cả các GPU có sẵn trong nút và hiển thị thông lượng tích lũy tối đa khoảng 11000 hình ảnh/giây giữa hai máy ảo.
Kịch bản 2
Việc đào tạo các mô hình DL lớn đòi hỏi lượng tính toán lớn. Chúng tôi cũng cần đảm bảo rằng khóa đào tạo được hoàn thành trong một khoảng thời gian có thể chấp nhận được. Việc song song hóa hiệu quả các mạng lưới thần kinh sâu trên nhiều máy chủ là rất quan trọng để đạt được yêu cầu này. Có hai thuật toán chính khi chúng tôi giải quyết vấn đề đào tạo phân tán, song song dữ liệu và song song mô hình. Tính song song của dữ liệu cho phép sao chép cùng một mô hình trong tất cả các nút và chúng tôi cung cấp các lô dữ liệu đầu vào khác nhau cho mỗi nút. Trong mô hình song song, chúng tôi chia trọng số mô hình cho từng nút và cùng một dữ liệu lô nhỏ được huấn luyện trên các nút.
Trong kịch bản này, chúng tôi xem xét hiệu suất của tính song song dữ liệu trong khi đào tạo mô hình bằng nhiều nút. Mỗi nút nhận được dữ liệu minibatch khác nhau. Trong các thử nghiệm của mình, chúng tôi mở rộng quy mô thành bốn nút, mỗi nút có một VM và một GPU.
Để trợ giúp mở rộng mô hình thành nhiều nút, chúng tôi sử dụng Horovod (xem Tài liệu tham khảo 6 bên dưới ), đây là khung đào tạo DL phân tán. Horovod sử dụng Giao diện truyền tin nhắn (MPI) để giao tiếp hiệu quả giữa các quy trình.
Các khái niệm của MPI bao gồm:
- Kích thước cho biết tổng số quy trình. Trong trường hợp của chúng tôi, kích thước là bốn quy trình.
- Xếp hạng là ID duy nhất cho mỗi quy trình.
- Xếp hạng cục bộ cho biết ID tiến trình duy nhất trong một nút. Trong trường hợp của chúng tôi, chỉ có một GPU trong mỗi nút.
- Hoạt động Allreduce tổng hợp dữ liệu giữa nhiều quy trình và phân phối lại chúng trở lại quy trình.
- Hoạt động Allgather được sử dụng để thu thập dữ liệu từ tất cả các quy trình.
- Hoạt động Broadcast được sử dụng để phát dữ liệu từ một tiến trình được xác định bởi root tới các tiến trình khác.
Bảng sau đây cung cấp kết quả thử nghiệm mở rộng quy mô:
Bảng 2: Kết quả thí nghiệm mở rộng quy mô
| Số nút | Thông lượng VM (hình ảnh/giây) |
| 1 | 2757,21 |
| 2 | 5391.751667 |
| 4 | 10675.0925 |
Để có kết quả thử nghiệm chia tỷ lệ trong bảng, chúng tôi chạy tf_cnn_benchmarks với mô hình ResNet50 với kích thước lô là 1024 bằng cách sử dụng dữ liệu tổng hợp. Thử nghiệm này là một thử nghiệm dựa trên tỷ lệ yếu; do đó, cùng một kích thước lô cục bộ là 1024 được sử dụng khi chúng tôi mở rộng quy mô trên các nút.
Hình dưới đây cho thấy sơ đồ phân tích tăng tốc của thí nghiệm chia tỷ lệ:
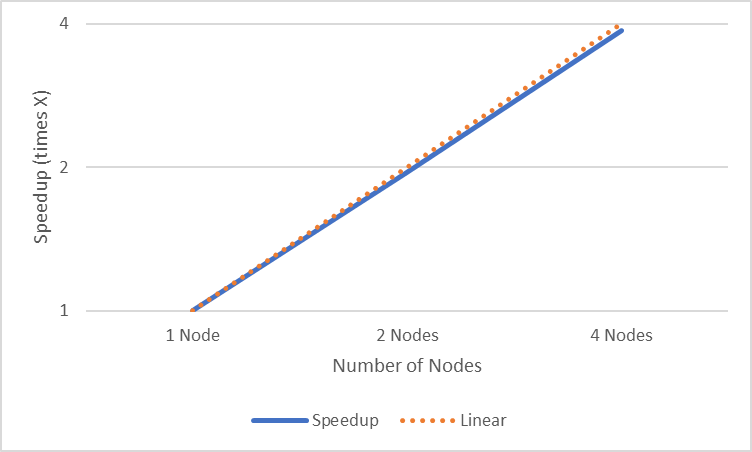
Hình 2: Phân tích tăng tốc thí nghiệm chia tỷ lệ
Phân tích tăng tốc trong Hình 2 cho thấy mức tăng tốc (lần X) khi mở rộng quy mô lên tới bốn nút. Chúng ta có thể thấy rõ rằng nó gần như có tỷ lệ tuyến tính khi chúng ta tăng số lượng nút.
Hình dưới đây cho thấy cách đào tạo phân tán đa nút trên máy ảo so với việc chạy các thử nghiệm tương tự trên máy chủ kim loại trần (BM):
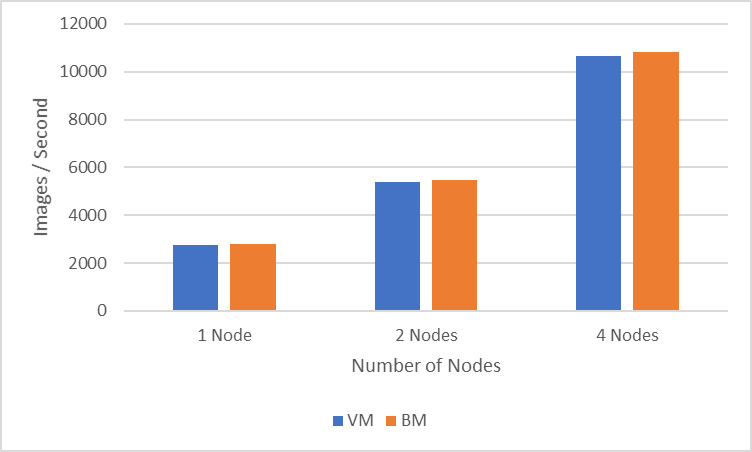
Hình 3: So sánh hiệu năng giữa máy ảo và máy chủ BM
Thử nghiệm bốn nút (một GPU trên mỗi nút) đạt được thông lượng 10675 hình ảnh/giây trong môi trường VM trong khi lần chạy BM được cấu hình tương tự đạt được thông lượng 10818 hình ảnh/giây. Các thử nghiệm một, hai và bốn nút cho thấy mức chênh lệch phần trăm dưới 2 phần trăm giữa thử nghiệm BM và thử nghiệm VM.
Phần kết luận
Trong blog này, chúng tôi đã mô tả cách thiết lập máy chủ ESXi và máy ảo để có thể chạy thử nghiệm đa nút. Chúng tôi đã kiểm tra nhiều tình huống khác nhau trong đó các nhà khoa học dữ liệu có thể hưởng lợi từ các thử nghiệm đa GPU và hiệu suất tương ứng của chúng. Các thử nghiệm chia tỷ lệ đa nút cho thấy tốc độ tăng tốc gần với tỷ lệ tuyến tính hơn. Chúng tôi cũng đã kiểm tra xem đào tạo phân tán dựa trên VM so với đào tạo phân tán dựa trên máy chủ BM như thế nào. Trong các blog sắp tới, chúng ta sẽ xem xét các phương pháp hay nhất để đào tạo vGPU đa nút cũng như cách sử dụng và hiệu suất của GPU đa phiên bản NVIDIA (MIG) cho các khối lượng công việc deep learning khác nhau.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...