
Tin tức
Mở rộng quy mô phần cứng và tính toán cho các ứng dụng học sâu thực tế trong chăm sóc sức khỏe
Thực hành y tế đòi hỏi phải phân tích khối lượng lớn dữ liệu trải rộng trên nhiều phương thức. Mặc dù những kết quả này có thể đơn giản như kết quả phòng thí nghiệm bằng số, nhưng ở một thái cực khác là dữ liệu có độ phức tạp cao như chụp ảnh cộng hưởng từ hoặc tài liệu lâm sàng dựa trên văn bản có giá trị hàng thập kỷ có thể có trong hồ sơ y tế. Thông thường, những chi tiết nhỏ ẩn chứa trong đống thông tin lâm sàng là rất quan trọng để có được bức tranh lâm sàng hoàn chỉnh. Nhiều phương pháp học sâu được phát triển trong những năm gần đây đã tập trung vào “độ dài chuỗi” rất ngắn – thuật ngữ dùng để mô tả số lượng từ hoặc pixel mà một mô hình có thể nhập vào – của hình ảnh và văn bản so với những gì gặp phải trong thực hành lâm sàng. Làm cách nào để chúng tôi mở rộng quy mô các công cụ như vậy để mô hình hóa bề rộng dữ liệu lâm sàng này một cách thích hợp và hiệu quả?
Trong blog sau, chúng tôi thảo luận về các cách giải quyết các yêu cầu điện toán khi phát triển các công cụ học sâu dựa trên máy biến áp cho dữ liệu chăm sóc sức khỏe từ góc độ phần cứng, xử lý dữ liệu và mô hình hóa. Để làm như vậy, chúng tôi trình bày một ứng dụng thực tế của Flash Chú ý bằng cách sử dụng một loạt thử nghiệm thực hiện phân tích thử thách Phát hiện ung thư vú bằng chụp nhũ ảnh bằng chụp nhũ ảnh Kaggle RSNA có sẵn công khai, bao gồm 54.706 hình ảnh của 11.913 bệnh nhân. Ung thư vú ảnh hưởng đến 1 trong 8 phụ nữ và là nguyên nhân thứ hai gây tử vong do ung thư. Do đó, chụp nhũ ảnh sàng lọc là một trong những quy trình sàng lọc y tế dựa trên hình ảnh được thực hiện nhiều nhất, cung cấp một nghiên cứu trường hợp tập trung vào dữ liệu và có liên quan đến lâm sàng để xem xét.
Dữ liệu mồi
Để phát hiện sớm ung thư vú khi phương pháp điều trị có hiệu quả nhất, hình ảnh X-quang có độ phân giải cao được chụp từ mô vú để xác định các vùng bất thường cần kiểm tra thêm bằng sinh thiết hoặc hình ảnh chi tiết hơn. Thông thường, có hai lượt xem được thu thập:
- Craniocaudal (CC) – nhìn từ đầu đến chân
- Xiên giữa bên (MLO) – chụp ở một góc
Tập dữ liệu chứa các hình ảnh có định dạng DICOM phải được xử lý trước theo kiểu tiêu chuẩn trước khi đào tạo mô hình. Chúng tôi mô tả chi tiết quy trình chuẩn bị dữ liệu trong hình 1. Các chế độ xem CC và MLO của từng nghiên cứu được xác định, lật theo chiều ngang nếu cần, cắt xén và kết hợp để tạo thành hình ảnh đầu vào của mô hình. Chúng tôi bao bọc lớp Bộ dữ liệu PyTorch tiêu chuẩn để tải hình ảnh và xử lý trước chúng để đào tạo.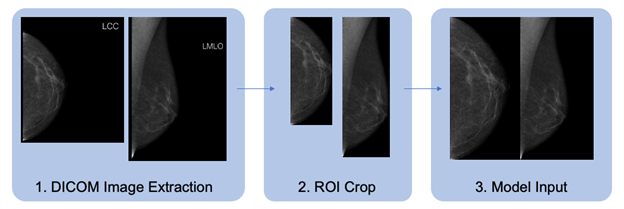 Hình 1. Quy trình tiền xử lý dữ liệu cho hình ảnh có định dạng DICOM
Hình 1. Quy trình tiền xử lý dữ liệu cho hình ảnh có định dạng DICOM
Một cái nhìn sâu hơn về hệ thống tiền xử lý dữ liệu như sau:
- Đối với mỗi vú có nhãn ung thư tương ứng, các chế độ xem CC và MLO sẽ được trích xuất và dữ liệu hình ảnh được chuẩn hóa. Các hình ảnh bên phải được lật theo chiều ngang sao cho mô nằm ở phía bên trái của hình ảnh, như minh họa.
- Hình ảnh được cắt theo vùng quan tâm (ROI), không bao gồm các vùng tạo tác màu đen hoặc không phải mô.
- Hình ảnh được thay đổi kích thước, duy trì tỷ lệ khung hình và được xếp thành hình vuông có kích thước đầu ra quan tâm, với chế độ xem CC chiếm nửa bên trái của đầu ra và chế độ xem MLO chiếm nửa bên phải.
Một điều quan trọng cần cân nhắc là liệu có nên thực hiện quá trình xử lý này trong bộ nạp dữ liệu trong khi đào tạo hay lưu phiên bản tập dữ liệu được xử lý trước. Cách tiếp cận trước đây cho phép lặp lại các chiến lược xử lý khác nhau mà không sửa đổi tập dữ liệu, mang lại sự thử nghiệm dễ dàng hơn. Tuy nhiên, mức xử lý này trong quá trình đào tạo có thể hạn chế tốc độ dữ liệu có thể được cung cấp cho bộ xử lý đồ họa (GPU) để đào tạo, dẫn đến thiếu hiệu quả về thời gian và tiền bạc. Ngược lại, cách tiếp cận thứ hai yêu cầu nhiều phiên bản của tập dữ liệu phải được lưu cục bộ, điều này có khả năng bị cấm khi làm việc với kích thước tập dữ liệu lớn và không gian lưu trữ cũng như/hoặc các giới hạn mạng. Với mục đích của bài đăng blog này, để đánh giá phần cứng GPU và tối ưu hóa đào tạo, chúng tôi sử dụng phương pháp thứ hai, lưu dữ liệu trên các ổ đĩa thể rắn cục bộ được kết nối qua NVMe để đảm bảo độ bão hòa GPU bất chấp sự khác biệt về bộ xử lý. Nói chung, trước khi triển khai tối ưu hóa đào tạo được mô tả bên dưới, điều quan trọng trước tiên là phải đảm bảo rằng việc tải dữ liệu không làm tắc nghẽn quá trình đào tạo tổng thể.
Mở rộng quy mô
Đương nhiên, việc tăng khả năng và số lượng điện toán có sẵn cho việc đào tạo mô hình sẽ mang lại lợi ích trực tiếp. Để chứng minh ảnh hưởng của phần cứng đến thời gian chạy, chúng tôi trình bày một thử nghiệm đào tạo đơn giản kéo dài 20 kỷ sử dụng cùng một tập dữ liệu trên ba máy chủ khác nhau, được hiển thị trong Hình 2:
- Dell XE8545 với 4x GPU NVIDIA A100-SXM4 40GB và AMD EPYC 7763 với 64 lõi
- Dell R750xa với 4x GPU NVIDIA A100 80GB và bộ xử lý Intel Xeon Gold 5320 với 26 lõi
- Máy chủ Dell XE9680 với 8 GPU NVIDIA HGX A100 80GB SXM4 và bộ xử lý Intel Xeon Platinum 8470 với 52 lõi
Dữ liệu đầu vào vào mô hình hiển thị trong hình 2 là 512×512 với kích thước bản vá là 16. Kích thước lô là 24 mỗi GPU trên 40 GB và 64 trên máy chủ 80 GB.
Các thông số vẫn giữ nguyên cho mỗi lần chạy, ngoại trừ kích thước lô đã được tăng lên để tận dụng tối đa bộ nhớ GPU trên R750xa và XE9680 so với XE8545. Tích lũy gradient được thực hiện để duy trì kích thước lô toàn cầu không đổi trên mỗi lần cập nhật trọng lượng mô hình cho mỗi lần chạy. Chúng tôi nhận thấy sự cải thiện rõ ràng về thời gian chạy khi phần cứng được mở rộng quy mô, chứng tỏ khả năng tính toán tăng lên trực tiếp mang lại sự tiết kiệm thời gian cho phép các nhà nghiên cứu lặp lại các thử nghiệm một cách hiệu quả và đào tạo các mô hình hiệu quả.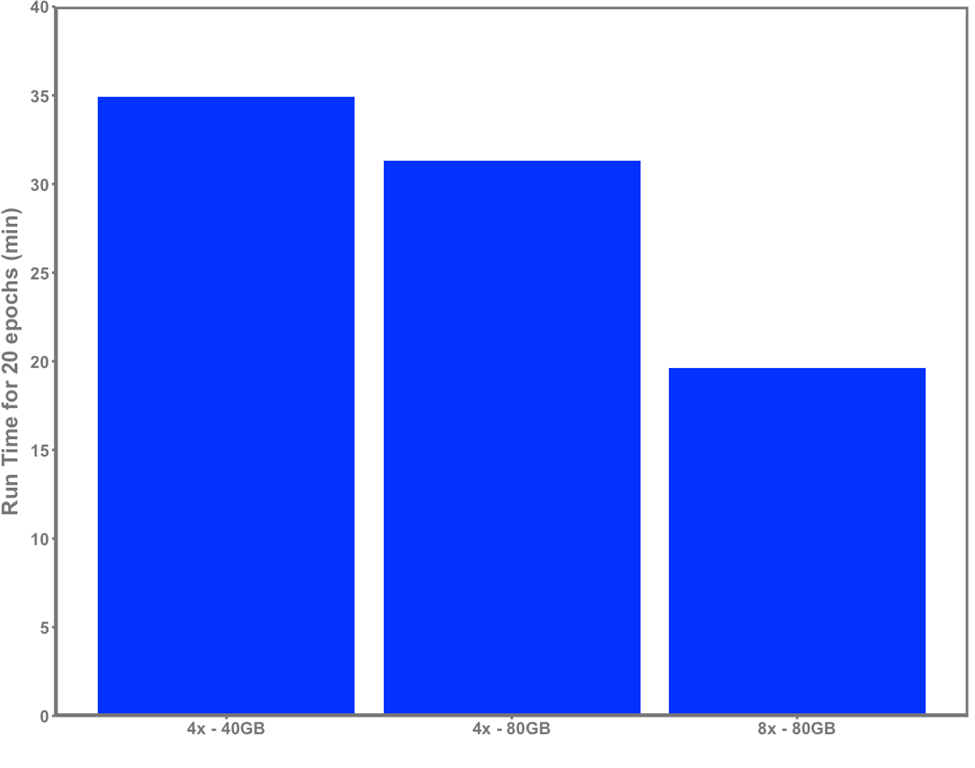 Hình 2. Thời gian đào tạo ViT-base trong 20 kỷ nguyên với máy chủ 4xA100 40GB, 4xA100 80GB và 8xA100 80GB
Hình 2. Thời gian đào tạo ViT-base trong 20 kỷ nguyên với máy chủ 4xA100 40GB, 4xA100 80GB và 8xA100 80GB
Cùng với phần cứng, độ dài chuỗi dữ liệu cần được xem xét cẩn thận dựa trên ứng dụng quan tâm. Sơ đồ mã thông báo đã chọn sẽ tác động trực tiếp đến độ dài chuỗi của dữ liệu đầu vào, chẳng hạn như kích thước bản vá được chọn làm đầu vào cho bộ biến đổi thị giác. Ví dụ: kích thước bản vá là 16 trên hình ảnh 1024×1024 sẽ dẫn đến độ dài chuỗi là 4.096 (Chiều cao*Chiều rộng/Kích thước bản vá 2 ) trong khi kích thước bản vá là 8 sẽ dẫn đến độ dài chuỗi là 16.384. Mặc dù GPU ngày càng có nhiều bộ nhớ hơn nhưng chúng lại đưa ra giới hạn trên về độ dài chuỗi có thể được xem xét trên thực tế. Kích thước miếng vá nhỏ hơn – và do đó, chuỗi dài hơn – sẽ dẫn đến thông lượng chậm hơn thông qua kích thước lô nhỏ hơn và số lượng tính toán lớn hơn, như trong Hình 3. Tuy nhiên, kích thước hình ảnh lớn hơn cùng với kích thước miếng vá nhỏ hơn đặc biệt có liên quan trong phân tích chụp X-quang tuyến vú và các ứng dụng khác trong đó các tính năng độ phân giải tốt được quan tâm.
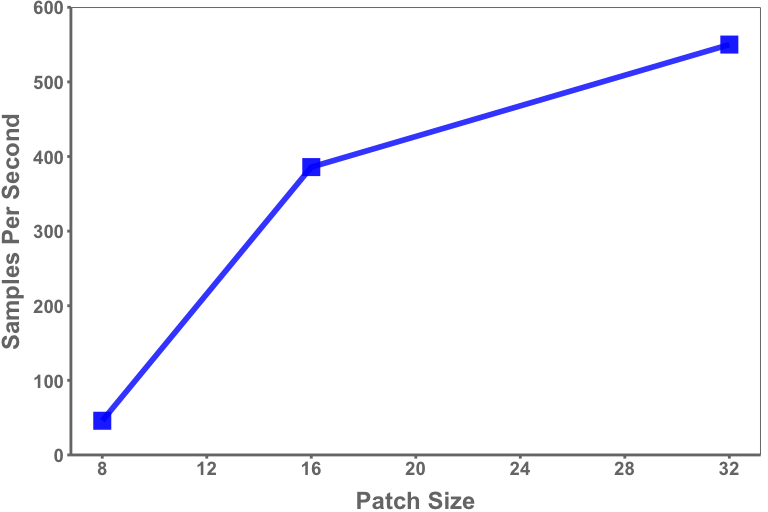 Hình 3. Mẫu đào tạo trung bình mỗi giây (mỗi GPU) cho chụp quang tuyến vú thông qua máy biến áp thị giác theo kích thước miếng vá
Hình 3. Mẫu đào tạo trung bình mỗi giây (mỗi GPU) cho chụp quang tuyến vú thông qua máy biến áp thị giác theo kích thước miếng vá
Dữ liệu minh họa trong hình 3 được lấy từ hai mươi kỷ nguyên sử dụng kích thước hình ảnh 512×512 và được thử nghiệm trên máy chủ 8xA100 (80 GB).
Chú ý chớp nhoáng – Thử nghiệm
Gần đây, Dao et al. đã xuất bản trên Flash Chú ý ( https://arxiv.org/abs/2205.14135 ), một kỹ thuật nhằm hoàn thành hiệu quả hơn các tính toán liên quan đến máy biến áp thông qua việc giảm thiểu bộ nhớ băng thông cao GPU và SRAM trên chip. Những phát hiện được báo cáo của họ rất ấn tượng, mang lại tốc độ tăng gấp 2-3 lần trong quá trình chú ý tiến và lùi trong khi cũng có yêu cầu bộ nhớ nhỏ hơn 3-20 lần.
Sử dụng máy chủ Dell XE9680 với 8 GPU NVIDIA HGX A100 80GB SXM4 và bộ xử lý Intel Xeon Platinum 8470 với 52 lõi , chúng tôi cung cấp một minh chứng thực tế về các ứng dụng tiềm năng cho bộ biến đổi thị giác và Flash Chú ý trong chăm sóc sức khỏe. Cụ thể, chúng tôi đã thực hiện các thử nghiệm để chứng minh độ dài chuỗi (được xác định bằng kích thước bản vá và kích thước hình ảnh) và thời gian đào tạo Chú ý Flash ảnh hưởng như thế nào. Để hạn chế các biến gây nhiễu, tất cả các hình ảnh đều được định cỡ sẵn trên đĩa và được tải trực tiếp vào biến áp thị giác mà không có bất kỳ hoán vị nào. Đối với máy biến áp tầm nhìn, ViT-Base từ Huggingface đã được sử dụng. Đối với Flash Chú ý, Bộ mã hóa từ thư viện x_transformers đã được sử dụng, hiển thị đang được triển khai trong mã sau.
Tất cả các thử nghiệm đều được thực hiện với trình huấn luyện Huggingface sử dụng kích thước lô hiệu quả là 128 trên mỗi GPU, dữ liệu dấu phẩy động “não” 16 và trên 20 kỷ nguyên ở kích thước bản vá 8, 16 và 32 với kích thước hình ảnh là 384, 512, 1024 và 2048.
từ x_transformers nhập ViTransformerWrapper, Bộ mã hóa lớp FlashViT(nn.Module): def __init__(tự, bộ mã hóa = ViTransformerWrapper( image_size = args.img_size, patch_size = args.patch_size, num_classes = 2, kênh=3, attn_layers = Bộ mã hóa( mờ = 768, độ sâu = 12, đầu = 12, attn_flash=Đúng ) ), siêu().__init__() self.encode = bộ mã hóa def Forward(self, pixel_values: torch.tensor, nhãn: torch.tensor): """ pixel_values: [batch,channel,ht,wt] của giá trị pixel nhãn: nhãn cho mỗi hình ảnh """ logits = self.encode(pixel_values) trả về {'loss':F.cross_entropy(logits,labels),'logits':logits} mô hình = FlashViT()
Hình 4 thể hiện lợi ích rõ rệt của việc sử dụng Flash Chú ý trong biến áp tầm nhìn liên quan đến thông lượng mô hình. Ngoại trừ hai kích thước hình ảnh nhỏ nhất và kích thước bản vá lớn nhất (và do đó có độ dài chuỗi ngắn nhất), Flash Chú ý dẫn đến tốc độ tăng lên rõ rệt trên tất cả các nhiễu loạn khác. Phạm vi tăng tốc trên các kích thước bản vá là:
- Kích thước bản vá 8 : 3,0 – 4,2x
- Kích thước bản vá 16 : 2,8 – 4,0x
- Kích thước bản vá 32 : 0 – 2,3x
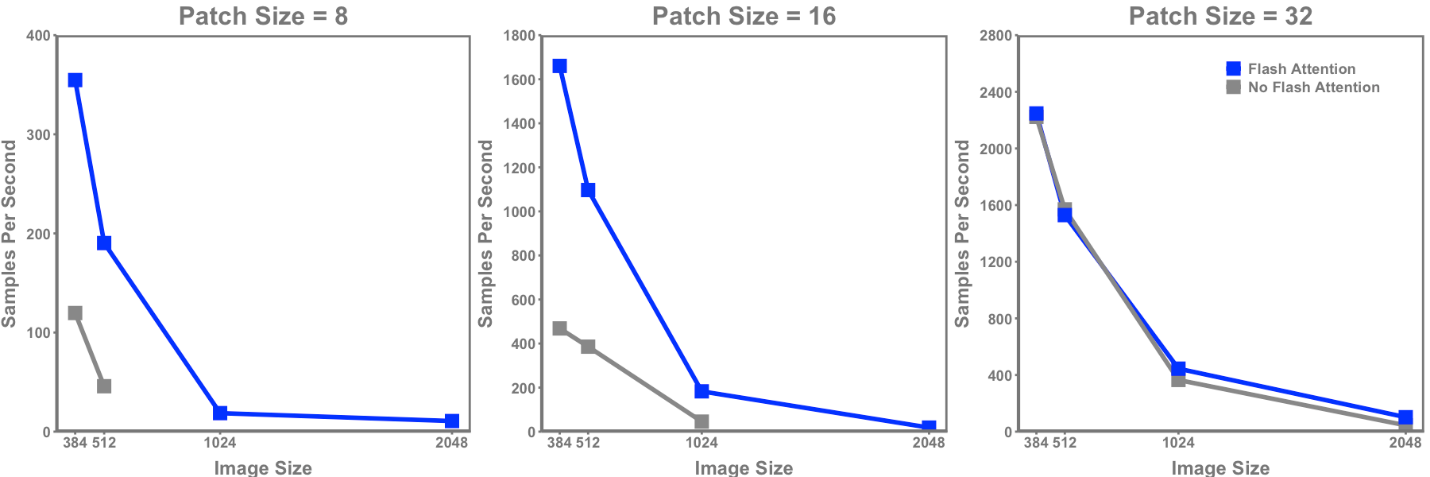 Hình 4. Thông lượng mẫu mỗi giây cho máy biến áp thị giác cơ sở ViT có và không có Flash Chú ý trên các kích thước hình ảnh và kích thước bản vá khác nhau
Hình 4. Thông lượng mẫu mỗi giây cho máy biến áp thị giác cơ sở ViT có và không có Flash Chú ý trên các kích thước hình ảnh và kích thước bản vá khác nhau
Một lợi ích khác được chứng minh trong các thử nghiệm này là sự kết hợp hình ảnh và kích thước bản vá bổ sung chỉ có thể đạt được với Flash Chú ý do yêu cầu bộ nhớ GPU giảm. Các mô hình Chú ý không flash chỉ có thể được sử dụng trên kích thước hình ảnh là 2.048 nếu kích thước bản vá là 32 được sử dụng (độ dài chuỗi là 4.096), trong khi Chú ý Flash có thể chạy trên kích thước bản vá là 8 và 16. Ngay cả ở độ dài chuỗi ngắn hơn ( 576 – 384×384, kích thước bản vá là 16), bộ nhớ được sử dụng cho Flash Chú ý ít hơn 2,3 lần. Việc sử dụng Flash Chú ý cũng sẽ rất quan trọng khi xem xét các mẫu máy biến áp lớn hơn, với ViT-Huge có thông số gấp 7 lần so với ViT-Base. Cùng với hoạt động đào tạo phân tán hỗ trợ phần cứng trên quy mô lớn như Dell XE9680, những tối ưu hóa này sẽ mang lại những phát hiện mới ở quy mô chưa từng có.
Mang về
Chúng tôi đã mô tả các phương pháp mà nhờ đó lợi ích của các mô hình dựa trên máy biến áp có thể được mở rộng theo trình tự dài hơn mà dữ liệu y tế thường yêu cầu. Đáng chú ý, chúng tôi chứng minh lợi ích của việc triển khai Flash Chú ý đến bộ mã hóa thị giác. Flash Chú ý mang lại lợi ích rõ rệt từ góc độ lập mô hình, từ thời gian chạy ngắn hơn (và do đó chi phí thấp hơn) đến mã hóa hình ảnh tốt hơn (độ dài chuỗi dài hơn). Hơn nữa, chúng tôi cho thấy rằng những lợi ích này tăng đáng kể cùng với độ dài chuỗi, khiến chúng không thể thiếu đối với những người thực hành muốn lập mô hình toàn bộ độ phức tạp của dữ liệu bệnh viện. Khi học máy tiếp tục phát triển trong lĩnh vực chăm sóc sức khỏe, do đó, sự hợp tác chặt chẽ giữa bệnh viện và nhà sản xuất công nghệ là điều cần thiết để cho phép các nguồn lực điện toán lớn hơn nhập dữ liệu chất lượng cao hơn vào các mô hình học máy.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...