
OneFS SmartPools cung cấp phân tầng tinh vi giữa các loại nút lưu trữ. Các quy tắc dựa trên các thuộc tính tệp như thời gian truy cập gần nhất hoặc ngày tạo có thể được cấu hình trong OneFS để thúc đẩy chuyển động trong suốt của dữ liệu giữa các loại nút PowerScale. Phương pháp tiếp cận “đặt và quên” này đối với phân tầng dữ liệu lý tưởng cho một số ngành nhưng không khả thi đối với hầu hết các quy trình tạo nội dung.
Một trường hợp điển hình về cách thức phân tầng này không hiệu quả đối với phương tiện truyền thông là bản chất thời gian thực của phát lại video. Ví dụ cực đoan, hãy lấy một chuỗi hình ảnh 4K chưa nén ( hoặc thậm chí là 8K ), có thể yêu cầu thông lượng >1,5GB/giây để phát đúng cách. Nếu phương tiện truyền thông này đã được phân tầng xuống lưu trữ lưu trữ hiệu suất thấp và cần được sử dụng, các tệp đó phải được di chuyển trở lại trước khi chúng có thể phát. Vấn đề này gây ra sự chậm trễ và nhầm lẫn ở khắp mọi nơi và khiến các quản trị viên lưu trữ phương tiện truyền thông ngần ngại lưu trữ bất cứ thứ gì.
Tin tốt là hệ sinh thái PowerScale OneFS có cách thực hiện tốt hơn!
Cách tiếp cận mà tôi đã thực hiện ở đây là kéo siêu dữ liệu từ nơi khác trong quy trình làm việc và sử dụng nó để thúc đẩy phân tầng theo yêu cầu trong OneFS. Điều đó hoạt động như thế nào? OneFS hỗ trợ các thuộc tính mở rộng tệp, là các cặp <khóa/giá trị> (siêu dữ liệu!) có thể được ghi vào các tệp và thư mục được lưu trữ trong OneFS. Chính sách tệp có thể được cấu hình trong OneFS để di chuyển dữ liệu dựa trên các thuộc tính mở rộng tệp đó. Và tác vụ SmartPoolsTree chỉ có thể chạy trên đường dẫn cần di chuyển. Tất cả những điều tuyệt vời này có thể được kiểm soát bên ngoài bằng cách kết hợp API DataIQ và API OneFS .

Hình 1: Luồng API
Xin lưu ý rằng trong khi tôi tập trung vào việc kết hợp API DataIQ và OneFS trong bài đăng này, các công cụ điều khiển API khác có khả năng hiển thị hệ thống tệp OneFS cũng có thể thay thế cho DataIQ.
Dữ liệuIQ
DataIQ là một công cụ lập chỉ mục và phân tích dữ liệu. Nó chạy như một máy ảo bên ngoài và duy trì một chỉ mục của các hệ thống tệp được gắn kết. Trình thu thập dữ liệu hệ thống tệp của DataIQ hiệu quả, nhanh và nhẹ, nghĩa là nó có thể được cập nhật mà không ảnh hưởng nhiều đến các thiết bị lưu trữ mà nó đang lập chỉ mục.
DataIQ có một khái niệm gọi là “gắn thẻ”. Các thẻ trong DataIQ áp dụng cho các thư mục và cung cấp một cơ chế để báo cáo các tập hợp dữ liệu liên quan. Một thẻ trong DataIQ là một cặp <key>/<value> tùy ý. Các thư mục có thể được gắn thẻ trong DataIQ theo ba cách khác nhau:
- Quy tắc gắn thẻ tự động:
- Thẻ được tự động đặt vào hệ thống tệp dựa trên biểu thức chính quy được xác định trong menu cấu hình Tự động gắn thẻ.
- Sử dụng tệp .cntag:
- Các tệp trống có tên theo định dạng <key>.<value>.cntag được đặt trong các thư mục và sẽ được DataIQ nhận dạng là thẻ.
- Gắn thẻ dựa trên API:
- API DataIQ cho phép gắn thẻ thư mục bên ngoài.
Có thể đặt thẻ trong toàn bộ hệ thống tệp và sau đó báo cáo dưới dạng nhóm. Ví dụ, thư mục render tạm thời có thể chứa tệp render.temp.cntag. Tương tự, một công cụ bên ngoài có thể truy cập API DataIQ và đặt thẻ <Project/Name> vào thư mục cấp cao nhất của mỗi dự án. DataIQ có thể tạo báo cáo về dung lượng lưu trữ mà các thẻ đó đang sử dụng.
Thuộc tính mở rộng của hệ thống tập tin trong OneFS
Như tôi đã đề cập trước đó, OneFS hỗ trợ các thuộc tính mở rộng tệp. Các thuộc tính mở rộng là các thẻ siêu dữ liệu tùy ý dưới dạng cặp <key/value> có thể được áp dụng cho các tệp và thư mục. Các thuộc tính mở rộng không hiển thị trong giao diện đồ họa hoặc khi truy cập các tệp qua chia sẻ hoặc xuất. Tuy nhiên, các thuộc tính có thể được truy cập bằng cách sử dụng OneFS CLI với các lệnh getexattr và setexattr.
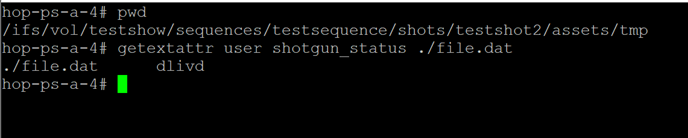
Hình 2: Thuộc tính mở rộng của tệp
Công cụ công việc SmartPools sẽ di chuyển dữ liệu giữa các nhóm nút dựa trên các thuộc tính tệp này. Và chính chức năng SmartPools sử dụng siêu dữ liệu này để thực hiện phân tầng dữ liệu theo yêu cầu.
Quan trọng là OneFS hỗ trợ việc tạo các thuộc tính mở rộng hệ thống tệp từ một tập lệnh bên ngoài bằng cách sử dụng OneFS REST API. OneFS API Reference Guide có thông tin tuyệt vời về việc thiết lập và đọc lại các thuộc tính mở rộng hệ thống tệp.
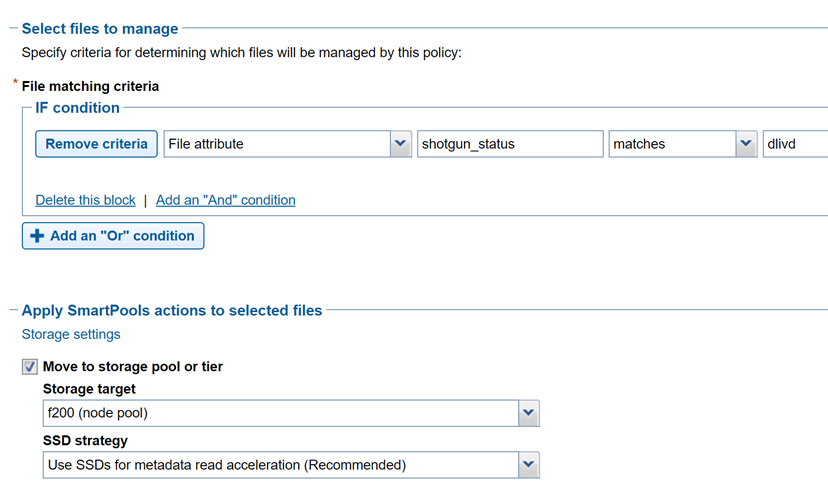
Hình 3: Cấu hình chính sách tập tin
Ví dụ về phân tầng với Autodesk Shotgrid, DataIQ và OneFS
Autodesk ShotGrid (trước đây là Shotgun) là một công cụ quản lý tài nguyên sản xuất phổ biến trong ngành công nghiệp hiệu ứng hình ảnh và hoạt hình. ShotGrid là một công cụ dựa trên đám mây cho phép phối hợp các nhóm sản xuất lớn. Mặc dù không phải là công cụ quản lý lưu trữ, nhưng logic kinh doanh của nó có thể hữu ích trong việc quyết định tầng lưu trữ nào mà một tập hợp tệp cụ thể nên nằm trên đó. Ví dụ, nếu một cảnh quay được theo dõi trong ShotGrid đã hoàn tất và được chuyển giao, các tệp liên quan đến cảnh quay đó có thể được chuyển đến kho lưu trữ.
Tiện ích bổ sung DataIQ cho Autodesk ShotGrid
Plug-in DataIQ mã nguồn mở dành cho ShotGrid có sẵn trên GitHub tại đây:
Tiện ích bổ sung Dell DataIQ Autodesk ShotGrid
Plug-in này là mã chứng minh khái niệm để cho thấy cách API ShotGrid và DataIQ có thể được kết hợp để gắn thẻ dữ liệu trong DataIQ dựa trên trạng thái cú đánh trong ShotGrid. Các thẻ DataIQ được cập nhật động với trạng thái cú đánh hiện tại trong ShotGrid.
Dưới đây là một “cảnh quay” trong ShotGrid được cấu hình với nhiều trạng thái có thể có:
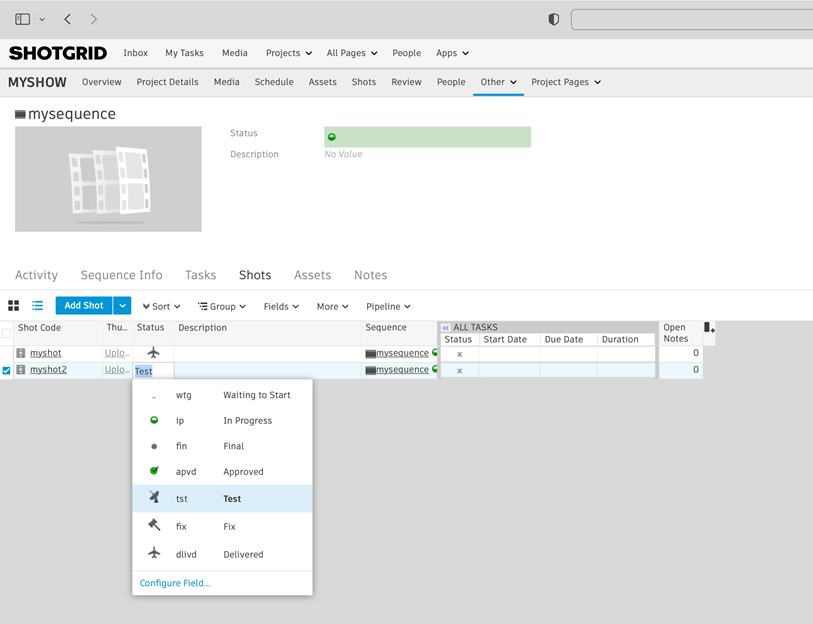
Hình 4: Trạng thái ShotGrid
Hình ảnh sau đây của DataIQ cho thấy trường trạng thái cú đánh từ ShotGrid đã được tự động áp dụng làm thẻ trong DataIQ.
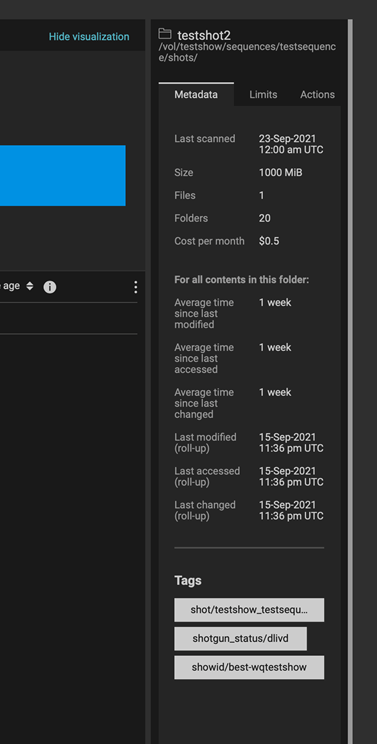
Hình 5: Thẻ DataIQ
Sau khi siêu dữ liệu từ ShotGrid được đưa vào DataIQ, thông tin đó có thể được sử dụng để thúc đẩy phân tầng OneFS SmartPools:
- Người dùng (hoặc hệ thống) chuyển thẻ DataIQ <key/values> đến DataIQ API. DataIQ API trả về danh sách các thư mục được liên kết với thẻ đó.
- Thư mục được chọn từ Bước 1 ở trên có thể được chuyển trở lại API DataIQ để lấy danh sách tất cả nội dung thông qua chỉ mục tệp DataIQ.
- Các mục đó được truyền theo chương trình đến OneFS API. Cặp <key/value> của thẻ DataIQ gốc được viết dưới dạng thuộc tính mở rộng trực tiếp đến các tệp và thư mục mục tiêu.
- Và cuối cùng, tác vụ SmartPoolsTree có thể được chạy trên đường dẫn cha đã chọn ở Bước 2 ở trên để bắt đầu phân tầng dữ liệu ngay lập tức.
Sử dụng logic kinh doanh để thúc đẩy phân tầng lưu trữ
DataIQ và OneFS cung cấp các API cần thiết để thúc đẩy phân tầng lưu trữ dựa trên logic kinh doanh. Có thể đạt được hiệu quả đáng kinh ngạc bằng cách tận dụng siêu dữ liệu có trong nhiều công cụ quy trình làm việc. Đó là vấn đề “kết nối các điểm”.
Ví dụ trong blog này sử dụng ShotGrid và DataIQ, tuy nhiên, có thể dễ dàng hình dung rằng các kỹ thuật dựa trên siêu dữ liệu tương tự có thể được phát triển bằng các công cụ chỉ mục hệ thống tệp khác. Trong hệ sinh thái phương tiện truyền thông và giải trí, hệ thống quản lý tài sản phương tiện truyền thông và hệ thống quản lý tài sản sản xuất ngay lập tức được nghĩ đến như là ứng cử viên cho loại tích hợp cấp API này.
Khi khối lượng dữ liệu tăng theo cấp số nhân, việc giữ tất cả các tệp trên các tầng lưu trữ có chi phí cao nhất là không thực tế. Nhiều phương pháp phân tầng lưu trữ tự động đã có từ nhiều năm, nhưng đối với nhiều trường hợp sử dụng, phương pháp phân tầng tự động này không hiệu quả. Việc kết hợp siêu dữ liệu phong phú và quy trình làm việc do API điều khiển sẽ thu hẹp khoảng cách.
Để xem Python cần thiết để thực hiện quy trình này, hãy tham khảo sách trắng của tôi PowerScale OneFS: A Metadata Driven Approach to On Demand Tiering .
Tác giả : Gregory Shiff, Kiến trúc sư giải pháp chính, Truyền thông & Giải trí
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...