
Bộ nhớ đệm xảy ra trong OneFS ở nhiều cấp độ và cho nhiều loại dữ liệu khác nhau. Trong phần thảo luận này, chúng ta sẽ tập trung vào bộ nhớ đệm của các cấu trúc hệ thống tệp trong bộ nhớ chính và trên SSD.
Thiết kế cơ sở hạ tầng bộ nhớ đệm của OneFS dựa trên việc tổng hợp bộ nhớ đệm của từng nút riêng lẻ thành một nhóm bộ nhớ có thể truy cập toàn cầu trên toàn cụm. Điều này được thực hiện bằng cách sử dụng một hệ thống nhắn tin hiệu quả, cho phép tất cả bộ nhớ đệm của các nút có sẵn cho từng nút trong cụm.
Đối với truy cập bộ nhớ từ xa, OneFS sử dụng Giao thức Sockets Direct (SDP) qua kết nối phụ trợ Ethernet hoặc Infiniband (IB) trên cụm. SDP cung cấp giao diện hiệu quả, giống như ổ cắm giữa các nút, bằng cách sử dụng cấu trúc sao chuyển mạch, đảm bảo rằng các địa chỉ bộ nhớ từ xa chỉ cách một bước nhảy. Mặc dù không nhanh bằng bộ nhớ cục bộ, nhưng truy cập bộ nhớ từ xa vẫn rất nhanh do độ trễ thấp của mạng phụ trợ.
OneFS sử dụng tối đa ba cấp độ bộ đệm đọc, cộng với bộ đệm ghi được hỗ trợ bởi NVRAM hoặc bộ hợp nhất ghi. Hai loại bộ đệm đọc đầu tiên, cấp độ 1 (L1) và cấp độ 2 (L2), dựa trên bộ nhớ (RAM) và tương tự như bộ đệm được sử dụng trong CPU. Hai lớp bộ đệm này có trong tất cả các nút lưu trữ PowerScale. Một cấp độ thứ ba tùy chọn của bộ đệm đọc, được gọi là SmartFlash hoặc bộ đệm Cấp độ 3 (L3), cũng có thể định cấu hình trên các nút chứa ổ đĩa thể rắn (SSD). Bộ đệm L3 là bộ đệm loại bỏ được lấp đầy bởi các khối bộ đệm L2 khi chúng bị lỗi thời khỏi bộ nhớ.
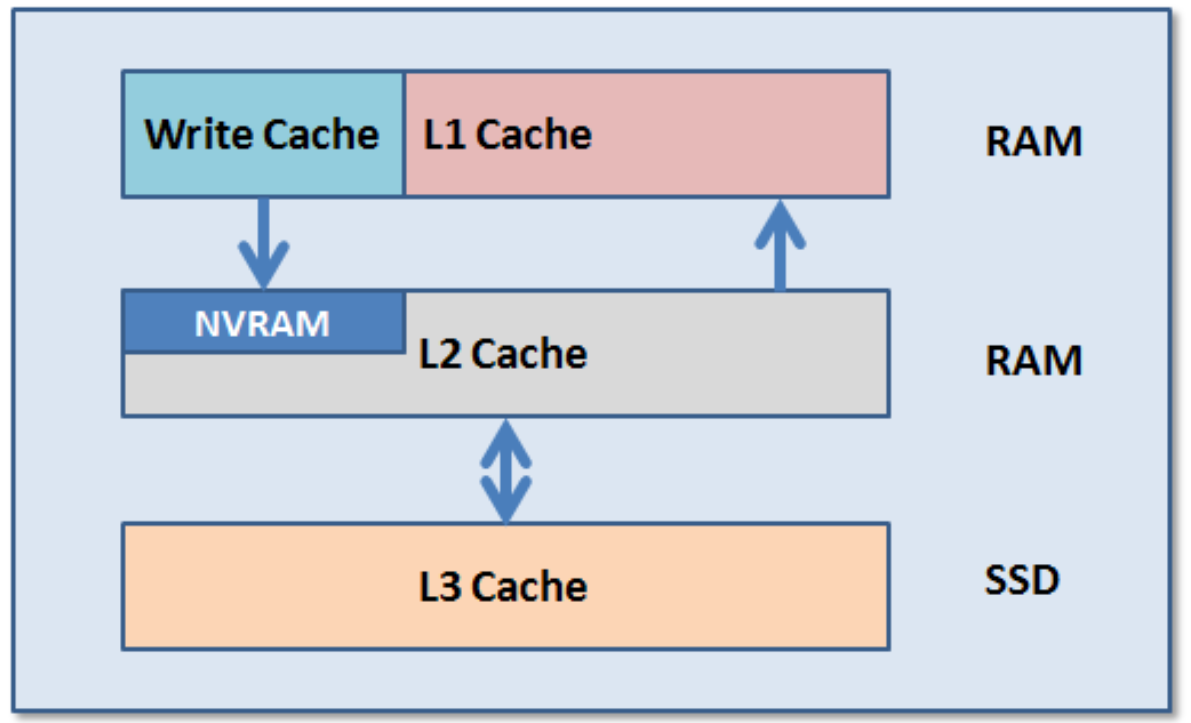
Hệ thống lưu trữ đệm OneFS có tính nhất quán trên toàn cụm. Điều này có nghĩa là nếu cùng một nội dung tồn tại trong bộ nhớ đệm riêng của nhiều nút, dữ liệu được lưu trữ đệm này sẽ nhất quán trên tất cả các phiên bản. Ví dụ, hãy xem xét kịch bản sau:
- Nút 2 và Nút 4 đều có một bản sao dữ liệu nằm tại một địa chỉ trong bộ nhớ đệm được chia sẻ.
- Nút 4, để đáp ứng yêu cầu ghi, sẽ vô hiệu hóa bản sao của nút 2.
- Sau đó, nút 4 cập nhật giá trị.
- Nút 2 phải đọc lại dữ liệu từ bộ nhớ đệm được chia sẻ để lấy giá trị cập nhật.
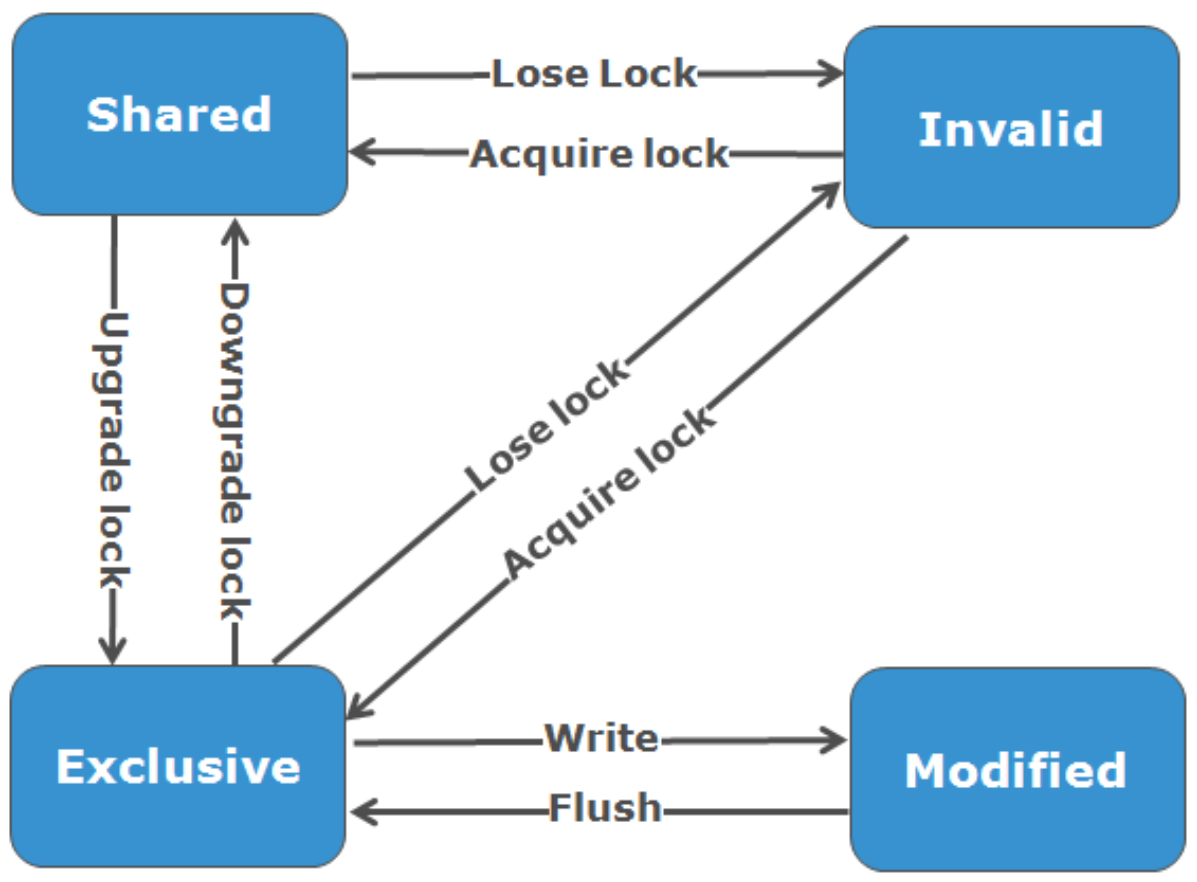
OneFS sử dụng Giao thức MESI để duy trì tính nhất quán của bộ đệm, triển khai chính sách “xác thực khi ghi” để đảm bảo rằng tất cả dữ liệu đều nhất quán trên toàn bộ bộ đệm được chia sẻ. Các trạng thái khác nhau mà dữ liệu trong bộ đệm có thể có là:
M – Đã sửa đổi : Dữ liệu chỉ tồn tại trong bộ nhớ đệm cục bộ và đã được thay đổi so với giá trị trong bộ nhớ đệm chia sẻ. Dữ liệu đã sửa đổi được gọi là ‘bẩn’.
E – Độc quyền : Dữ liệu chỉ tồn tại trong bộ nhớ đệm cục bộ, nhưng khớp với dữ liệu trong bộ nhớ đệm chia sẻ. Dữ liệu này được gọi là ‘sạch’.
S – Chia sẻ : Dữ liệu trong bộ đệm cục bộ cũng có thể nằm trong các bộ đệm cục bộ khác trong cụm.
I – Không hợp lệ : Khóa (độc quyền hoặc chia sẻ) đã bị mất trên dữ liệu.
Bộ nhớ đệm L1, hay bộ nhớ đệm front-end, là bộ nhớ gần nhất với các lớp giao thức (như NFS, SMB, v.v.) được sử dụng bởi các máy khách hoặc người khởi tạo, được kết nối với nút đó. Nhiệm vụ chính của L1 là lấy trước dữ liệu từ các nút từ xa. Dữ liệu được lấy trước theo từng tệp và điều này được tối ưu hóa để giảm độ trễ liên quan đến mạng back-end IB của các nút. Vì độ trễ kết nối IB tương đối nhỏ nên kích thước của bộ nhớ đệm L1 và lượng dữ liệu điển hình được lưu trữ cho mỗi yêu cầu sẽ nhỏ hơn bộ nhớ đệm L2.
L1 cũng được gọi là bộ đệm từ xa vì nó chứa dữ liệu được truy xuất từ các nút khác trong cụm. Nó có tính nhất quán trên toàn cụm, nhưng chỉ được sử dụng bởi nút mà nó nằm trên đó và không thể truy cập được bởi các nút khác. Dữ liệu trong bộ đệm L1 trên các nút lưu trữ bị loại bỏ mạnh mẽ sau khi được sử dụng. Bộ đệm L1 sử dụng địa chỉ dựa trên tệp, trong đó dữ liệu được truy cập bằng cách sử dụng độ lệch vào đối tượng tệp. Bộ đệm L1 tham chiếu đến bộ nhớ trên cùng một nút với bộ khởi tạo. Chỉ có nút cục bộ có thể truy cập được bộ đệm và thông thường bộ đệm không phải là bản sao chính của dữ liệu. Điều này tương tự như bộ đệm L1 trên lõi CPU, có thể bị vô hiệu hóa khi các lõi khác ghi vào bộ nhớ chính. Tính nhất quán của bộ đệm L1 được quản lý bằng giao thức giống MESI sử dụng khóa phân tán, như mô tả ở trên.
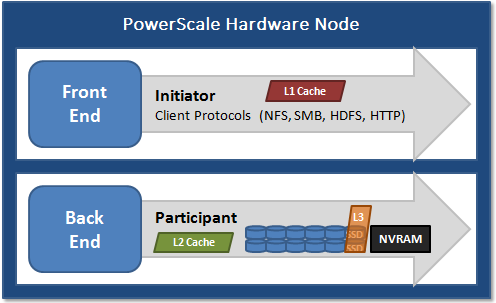
L2, hay bộ nhớ đệm back-end, đề cập đến bộ nhớ cục bộ trên nút mà một khối dữ liệu cụ thể được lưu trữ. L2 làm giảm độ trễ của hoạt động đọc bằng cách không yêu cầu tìm kiếm trực tiếp từ ổ đĩa. Do đó, lượng dữ liệu được tải trước vào bộ nhớ đệm L2 để các nút từ xa sử dụng lớn hơn nhiều so với lượng dữ liệu trong bộ nhớ đệm L1.
L2 cũng được gọi là bộ đệm cục bộ vì nó chứa dữ liệu được truy xuất từ các ổ đĩa nằm trên nút đó và sau đó được cung cấp cho các yêu cầu từ các nút từ xa. Dữ liệu trong bộ đệm L2 được loại bỏ theo thuật toán Ít được sử dụng gần đây nhất (LRU). Dữ liệu trong bộ đệm L2 được nút cục bộ xử lý bằng cách sử dụng một offset vào ổ đĩa cục bộ của nút đó. Vì nút biết dữ liệu được các nút từ xa yêu cầu nằm ở đâu trên đĩa, nên đây là cách rất nhanh để truy xuất dữ liệu dành cho các nút từ xa. Một nút từ xa truy cập bộ đệm L2 bằng cách tra cứu địa chỉ khối cho một đối tượng tệp cụ thể. Như đã mô tả ở trên, không cần phải vô hiệu hóa MESI ở đây và bộ đệm được tự động cập nhật trong quá trình ghi và được hệ thống giao dịch và NVRAM duy trì tính nhất quán.
Bộ đệm L3 là một hệ thống con lưu trữ đệm các khối L2 bị xóa trên một nút. Không giống như L1 và L2, không phải tất cả các nút hoặc cụm đều có bộ đệm L3, vì nó yêu cầu ổ đĩa trạng thái rắn (SSD) phải có và được dành riêng và cấu hình để sử dụng bộ đệm. L3 đóng vai trò là một cách lớn, tiết kiệm chi phí để mở rộng bộ đệm đọc của nút từ gigabyte lên terabyte. Điều này cho phép máy khách lưu giữ một tập dữ liệu làm việc lớn hơn trong bộ đệm, trước khi buộc phải truy xuất dữ liệu từ đĩa quay có độ trễ cao hơn. Bộ đệm L3 được lấp đầy bằng các khối L2 “thú vị” bị xóa khỏi bộ nhớ bởi thuật toán xóa bộ đệm ít được sử dụng nhất của L2. Không giống như bộ đệm dựa trên RAM, vì L3 dựa trên bộ nhớ flash liên tục, nên sau khi bộ đệm được lấp đầy hoặc làm ấm, nó có độ bền cao và tồn tại trong suốt quá trình khởi động lại nút, v.v. L3 sử dụng hệ thống tệp dựa trên nhật ký tùy chỉnh với chỉ mục các khối được lưu trong bộ đệm. SSD cung cấp các đặc điểm truy cập đọc ngẫu nhiên rất tốt, sao cho một lần truy cập trong bộ đệm L3 không chậm hơn nhiều so với một lần truy cập trong L2.
Để sử dụng nhiều SSD cho bộ nhớ đệm một cách hiệu quả và tự động, L3 sử dụng phương pháp băm nhất quán để liên kết một địa chỉ khối L2 với một SSD L3. Trong trường hợp ổ đĩa L3 bị lỗi, một phần bộ nhớ đệm rõ ràng sẽ biến mất, nhưng các mục bộ nhớ đệm còn lại trên các ổ đĩa khác vẫn sẽ hợp lệ. Trước khi có thể thêm ổ đĩa L3 mới vào hàm băm, một số mục bộ nhớ đệm phải bị vô hiệu hóa.
OneFS cũng sử dụng bộ đệm inode chuyên dụng, trong đó lưu giữ các inode được yêu cầu gần đây. Bộ đệm inode thường có tác động lớn đến hiệu suất, vì máy khách thường lưu trữ dữ liệu trong bộ đệm và nhiều hoạt động I/O mạng chủ yếu là các yêu cầu về thuộc tính tệp và siêu dữ liệu, có thể nhanh chóng được trả về từ inode được lưu trữ trong bộ đệm.
OneFS cung cấp các công cụ để đánh giá chính xác hiệu suất của các cấp độ bộ nhớ đệm khác nhau tại một thời điểm. Các số liệu thống kê bộ nhớ đệm này có thể được xem từ OneFS CLI bằng lệnh isi_cache_stats. Số liệu thống kê cho bộ nhớ đệm L1, L2 và L3 được hiển thị cho cả dữ liệu và siêu dữ liệu. Ví dụ:
# isi_cache_stats Tổng số l1_data: a 224G 100% r 226G 100% p 318M 77%, l1_encoded: a 0.0B 0% r 0.0B 0% p 0.0B 0%, l1_meta: r 4.5T 99% p 152K 48%, l2_data: r 1.2G 95% p 115M 79%, l2_meta: r 27G 72% p 28M 3%, l3_data: r 0,0B 0% p 0,0B 0%, l3_meta: r 8G 99% p 0,0B 0%
Để có kết quả định dạng và chi tiết hơn, bạn có thể sử dụng tùy chọn lệnh chi tiết hơn bằng cách sử dụng tùy chọn ‘isi_cache_stats -v’.
Điều đáng chú ý là đối với bộ đệm L3, số liệu thống kê trước khi truy xuất sẽ luôn là số không vì đây là bộ đệm loại bỏ thuần túy và không sử dụng dữ liệu hoặc siêu dữ liệu để truy xuất trước.
Nhờ phân phối dữ liệu cân bằng, tự động cân bằng lại và xử lý phân tán, OneFS có thể tận dụng thêm CPU, cổng mạng và bộ nhớ khi hệ thống phát triển. Điều này cũng cho phép hệ thống con lưu trữ đệm (và, theo đó, thông lượng và IOPS) mở rộng tuyến tính với kích thước cụm.
Tác giả : Nick Trimbee
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...