
Tin tức
Quản lý và phân tích lượng dữ liệu khổng lồ với Cụm dữ liệu lớn SQL Server 2019
Một tập hợp các dữ kiện và số liệu thống kê để tham khảo hoặc phân tích được gọi là dữ liệu và theo một cách nào đó, thuật ngữ “dữ liệu lớn” là một tổng lượng lớn dữ liệu. Khái niệm dữ liệu lớn đã tồn tại trong nhiều năm và khối lượng dữ liệu đang tăng lên hơn bao giờ hết, đó là lý do tại sao dữ liệu là tài sản cực kỳ có giá trị trong thế giới kết nối này. Quản lý dữ liệu lớn hiệu quả cho phép tổ chức xác định thông tin có giá trị một cách dễ dàng, bất kể dữ liệu lớn hay không có cấu trúc như thế nào. Dữ liệu được thu thập từ nhiều nguồn khác nhau bao gồm nhật ký hệ thống, trang mạng xã hội và bản ghi chi tiết cuộc gọi.
Bốn chữ V liên quan đến dữ liệu lớn là Khối lượng, Đa dạng, Vận tốc và Độ chính xác:
- Khối lượng là về kích thước—bạn có bao nhiêu dữ liệu.
- Sự đa dạng có nghĩa là dữ liệu rất khác nhau—tức là bạn có các loại cấu trúc dữ liệu rất khác nhau.
- Vận tốc là tốc độ truyền dữ liệu đến bạn nhanh như thế nào.
- Tính xác thực, chữ V cuối cùng, là một chữ khó. Vấn đề với dữ liệu lớn là nó rất không đáng tin cậy.
Cụm dữ liệu lớn của SQL Server giúp bạn dễ dàng quản lý loại dữ liệu phức tạp này.
Bạn có thể sử dụng SQL Server 2019 để tạo kiến trúc máy học kết hợp, an toàn, bắt đầu bằng việc chuẩn bị dữ liệu, huấn luyện mô hình máy học, vận hành mô hình của bạn và sử dụng mô hình đó để ghi điểm. Cụm dữ liệu lớn của SQL Server giúp dễ dàng hợp nhất dữ liệu quan hệ có giá trị cao với dữ liệu lớn có dung lượng lớn.
Cụm dữ liệu lớn tập hợp nhiều phiên bản SQL Server với Spark và HDFS, giúp việc hợp nhất dữ liệu lớn và quan hệ cũng như sử dụng chúng trong báo cáo, mô hình dự đoán, ứng dụng và AI trở nên dễ dàng hơn nhiều.
Ngoài ra, sử dụng PolyBase, bạn có thể kết nối với nhiều nguồn dữ liệu ngoài khác nhau như MongoDB, Oracle, Teradata, SAP HANA, v.v. Do đó, Cụm dữ liệu lớn SQL Server 2019 là nền tảng SQL, kho dữ liệu, hồ dữ liệu và nền tảng khoa học dữ liệu có thể mở rộng, hoạt động hiệu quả và có thể duy trì, không yêu cầu phải thỏa hiệp giữa đám mây và tại chỗ. Thành phần bao gồm:
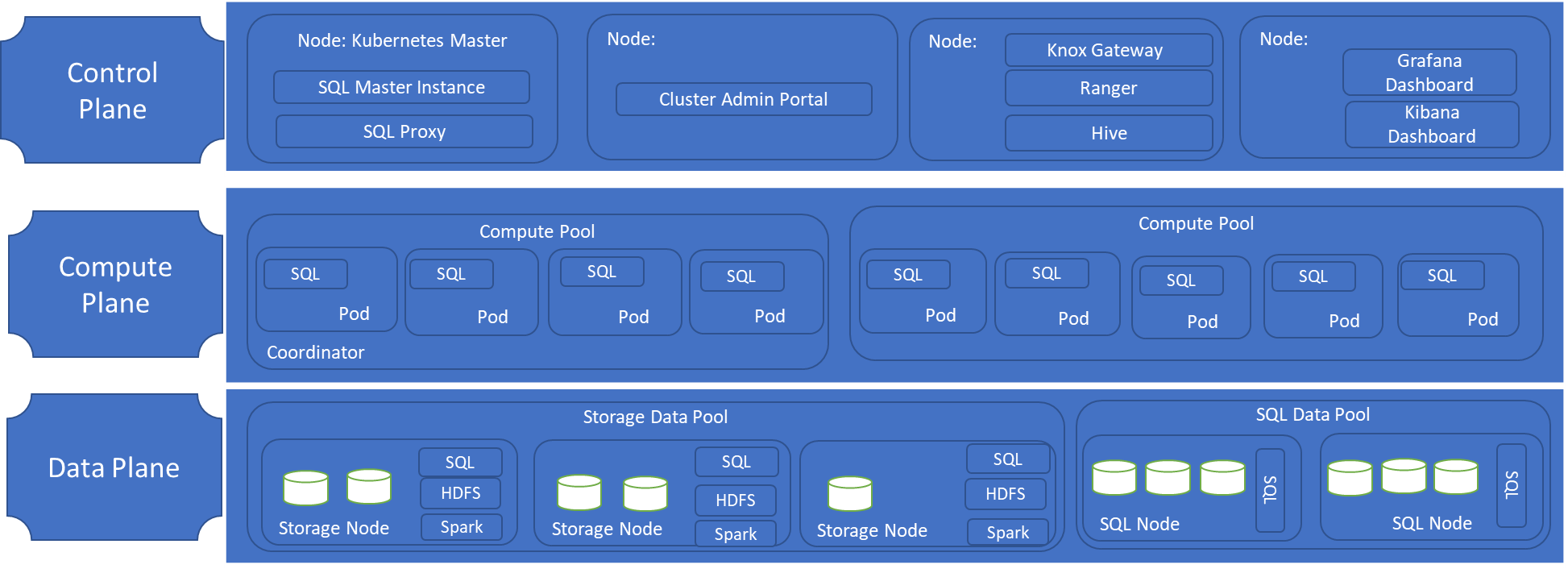
| Bộ điều khiển | Bộ điều khiển cung cấp khả năng quản lý và bảo mật cho cụm. Nó chứa dịch vụ điều khiển, kho cấu hình và các dịch vụ cấp cụm khác như Kibana, Grafana và Elastic Search. |
| Nhóm tính toán | Nhóm tính toán cung cấp tài nguyên tính toán cho cụm. Nó chứa các nút chạy SQL Server trên nhóm Linux. Các nhóm trong nhóm điện toán được chia thành các phiên bản điện toán SQL cho các tác vụ xử lý cụ thể. |
| Nhóm dữ liệu | Nhóm dữ liệu được sử dụng để lưu trữ dữ liệu và lưu vào bộ nhớ đệm. Nhóm dữ liệu bao gồm một hoặc nhiều nhóm chạy SQL Server trên Linux. Nó được sử dụng để nhập dữ liệu từ các truy vấn SQL hoặc công việc Spark. Các siêu dữ liệu của Cụm dữ liệu lớn SQL Server được duy trì trong nhóm dữ liệu. |
| Bể chứa | Nhóm lưu trữ bao gồm các nhóm nhóm lưu trữ bao gồm SQL Server trên Linux, Spark và HDFS. Tất cả các nút lưu trữ trong Cụm dữ liệu lớn của SQL Server đều là thành viên của cụm HDFS. |
Sau đây là kiến trúc tham khảo của SQL Server 2019 trên Big Data Cluster:
Tham khảo: https://docs.microsoft.com/en-us/sql/big-data-cluster/big-data-cluster-overview?view=sqlallproducts-allversions
Phân tích dữ liệu lớn
Phân tích dữ liệu là khoa học kiểm tra dữ liệu thô để khám phá thông tin cơ bản. Mục tiêu chính là đảm bảo rằng thông tin thu được có chất lượng dữ liệu cao và có thể truy cập được đối với hoạt động kinh doanh thông minh cũng như các ứng dụng phân tích dữ liệu lớn. Cụm dữ liệu lớn giúp việc học máy trở nên dễ dàng và chính xác hơn bằng cách xử lý bốn chữ V của dữ liệu lớn :
| Tác động của Vs đối với phân tích | Cụm dữ liệu lớn giúp ích như thế nào | |
| Âm lượng | Khối lượng dữ liệu được xử lý bởi thuật toán học máy càng lớn thì dự đoán sẽ càng chính xác. | Tăng khối lượng dữ liệu có sẵn cho AI bằng cách thu thập dữ liệu trong bộ lưu trữ dữ liệu lớn không tốn kém, có thể mở rộng trong HDFS và bằng cách tích hợp dữ liệu từ nhiều nguồn bằng trình kết nối PolyBase. |
| Đa dạng | Càng có nhiều nguồn dữ liệu khác nhau thì dự đoán sẽ càng chính xác. | Tăng số lượng loại dữ liệu có sẵn cho AI bằng cách tích hợp nhiều nguồn dữ liệu thông qua trình kết nối PolyBase. |
| vận tốc | Dự đoán theo thời gian thực phụ thuộc vào dữ liệu cập nhật được truyền nhanh chóng qua các đường ống xử lý dữ liệu. | Tăng tốc độ dữ liệu để kích hoạt AI bằng cách sử dụng tính toán linh hoạt và bộ nhớ đệm để tăng tốc truy vấn. |
| Tính xác thực | Học máy chính xác phụ thuộc vào chất lượng dữ liệu được đưa vào đào tạo mô hình. | Tăng tính xác thực của dữ liệu có sẵn cho AI bằng cách chia sẻ dữ liệu mà không cần sao chép hoặc di chuyển dữ liệu, điều này gây ra các vấn đề về độ trễ dữ liệu và chất lượng dữ liệu. SQL Server và Spark đều có thể đọc và ghi vào cùng một tệp dữ liệu trong HDFS. |
Quản lý cụm
Azure Data Studio là công cụ mà các kỹ sư dữ liệu, nhà khoa học dữ liệu và DBA sử dụng để quản lý cơ sở dữ liệu và viết truy vấn. Quản trị viên cụm sử dụng cổng quản trị, chạy dưới dạng nhóm trong cùng một không gian tên với toàn bộ cụm và cung cấp thông tin như trạng thái của tất cả các nhóm và dung lượng lưu trữ tổng thể.
Azure Data Studio là một công cụ quản lý đa nền tảng cho cơ sở dữ liệu của Microsoft. Nó giống như SQL Server Management Studio dựa trên công cụ soạn thảo VS Code phổ biến, một trình soạn thảo T-SQL phong phú có hỗ trợ IntelliSense và plug-in. Hiện tại, đây là cách dễ dàng nhất để kết nối với các điểm cuối SQL Server 2019 khác nhau (SQL, HDFS và Spark). Để làm như vậy, bạn cần cài đặt Data Studio và tiện ích mở rộng SQL Server 2019 .
Nếu có cơ sở hạ tầng Kubernetes, bạn có thể triển khai cơ sở hạ tầng này với một cụm máy chủ duy nhất bằng một lệnh duy nhất và có một cụm trong khoảng 30 phút.
Nếu muốn cài đặt Cụm dữ liệu lớn SQL Server 2019 trên cụm Kubernetes tại chỗ của mình, bạn có thể tìm hướng dẫn triển khai chính thức cho Cụm dữ liệu lớn trên Minikube trong tài liệu của Microsoft .
Phần kết luận
Lập kế hoạch là tất cả và việc lập kế hoạch tốt sẽ giải quyết được rất nhiều vấn đề, đặc biệt nếu bạn đang nghĩ đến việc truyền dữ liệu và phân tích thời gian thực.
Khi nói đến công nghệ, các tổ chức có nhiều loại giải pháp quản lý dữ liệu lớn khác nhau để lựa chọn. Các giải pháp của Dell Technologies dành cho SQL Server giúp các tổ chức đạt được một số lợi ích chính của Cụm dữ liệu lớn SQL Server 2019:
- Thông tin chuyên sâu cho mọi người: Quyền truy cập vào các dịch vụ quản lý, cổng quản trị và bảo mật tích hợp trong Azure Data Studio, giúp dễ dàng quản lý và tạo trải nghiệm quản trị và phát triển thống nhất cho người dùng SQL Server và dữ liệu lớn
- Dữ liệu phong phú: Dữ liệu sử dụng phân tích nâng cao và trí tuệ nhân tạo được tích hợp trong nền tảng
- Dữ liệu thông minh tổng thể:
- Truy cập thống nhất vào tất cả dữ liệu với hiệu suất tuyệt vời
- Quản lý dữ liệu dễ dàng và an toàn (lớn/nhỏ)
- Xây dựng ứng dụng thông minh và AI bằng tất cả dữ liệu
- Quản lý mọi dữ liệu, mọi quy mô, mọi nơi: Quản lý và phân tích đơn giản hóa thông qua việc triển khai, quản trị và công cụ thống nhất
- Dễ dàng triển khai và quản lý bằng cách sử dụng giải pháp dữ liệu lớn dựa trên Kubernetes được tích hợp trong SQL Server
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...