
Trừu tượng
Blog này giới thiệu kết quả hiệu suất MLPerf Inference v1.1 của máy chủ Dell EMC PowerEdge R7525 được định cấu hình với GPU NVIDIA A100 40 GB hoặc với GPU NVIDIA A30. Chúng tôi so sánh chi phí của một hệ thống với cả hai loại GPU để giúp bạn chọn cấu hình tốt nhất cho khối lượng công việc suy luận AI của mình.
Giới thiệu
Suy luận MLPerf v1.1 thuộc danh mục điểm chuẩn và chỉ số từ MLCommons ™ và đóng vai trò là tiêu chuẩn ngành cho hiệu suất suy luận máy học (ML). Bộ điểm chuẩn MLPerf đo lường hiệu suất của khối lượng công việc ML một cách nhất quán và công bằng. Điểm chuẩn Suy luận MLPerf đo lường tốc độ một hệ thống có thể thực hiện suy luận ML bằng cách sử dụng mô hình được đào tạo trước trong các tình huống triển khai khác nhau. Để hiểu toàn diện về Suy luận MLPerf, hãy xem blog này .
Chi tiết giường thử nghiệm
Các hệ thống được thử nghiệm (SUT) bao gồm:
- Máy chủ PowerEdge R7525 được định cấu hình với ba GPU NVIDIA A100 PCIe 40 GB (250 W, 40 GB thụ động, chiều rộng gấp đôi, chiều cao tối đa GPU). Tất cả các tham chiếu đến máy chủ PowerEdge R7525 với GPU A100 đều giả định rằng cấu hình bao gồm ba GPU NVIDIA A100.
- Máy chủ PowerEdge R7525 được định cấu hình với ba GPU NVIDIA A30 (165 W, 24 GB thụ động, chiều rộng gấp đôi, chiều cao đầy đủ với cáp). Tất cả các tham chiếu đến máy chủ PowerEdge R7525 với GPU A30 đều giả định rằng cấu hình bao gồm ba GPU NVIDIA A100.
Hình dưới đây hiển thị máy chủ PowerEdge R7525:

Cả hai hệ thống đều chạy TensorRT , một thư viện được thiết kế và phát triển để cải thiện hiệu suất suy luận trên GPU NVIDIA. Để biết thêm thông tin về TensorRT, hãy xem tài liệu NVIDIA .
cấu hình SUT
Bảng sau đây hiển thị các cấu hình hệ thống MLPerf cho SUT:
Bảng 1: Cấu hình SUT
| Nền tảng | PowerEdge R7525 với 3 GPU A100 PCIe 40 GB | PowerEdge R7525 với 3 GPU A30 |
| Mã hệ thống MLPerf | R7525_A100-PCIE-40GBx3_TRT | R7525_A30x3_TRT |
| Hệ điều hành | CentOS 8.2.2004 | |
| Kỉ niệm | 512GB | 1TB |
| GPU | NVIDIA A100-PCIE-40GB | NVIDIA A30 |
| số lượng GPU | 3
|
|
| ngăn xếp phần mềm | TenorRT 8.0.2
CUDA 11.3 cuDNN 8.2.1 Trình điều khiển GPU 470.42.01 DALI 0.31.0
|
|
Kết quả MLPerf Inference v1.1 trên mỗi mô hình
ResNet 50
ResNet50 là mạng thần kinh tích chập sâu 50 lớp được sử dụng cho nhiều ứng dụng thị giác máy tính. Mạng thần kinh này có thể xử lý các gradient biến mất bằng cách sử dụng khái niệm bỏ qua các kết nối bằng cách cho phép các gradient di chuyển qua các lớp trong mạng. Để biết phần giới thiệu về ResNet, hãy xem Deep Residual Learning for Image Recognition .
Chúng tôi đã tiến hành bốn thử nghiệm trên mô hình này trên hai SUT: hai trong kịch bản Ngoại tuyến và hai trong kịch bản Máy chủ. Hình dưới đây cho thấy kết quả ResNet50 của chúng tôi. Hiệu suất của máy chủ PowerEdge R7525 với GPU A30 trong cả hai kịch bản cao hơn khoảng 50 phần trăm so với máy chủ PowerEdge R7525 với GPU A100.
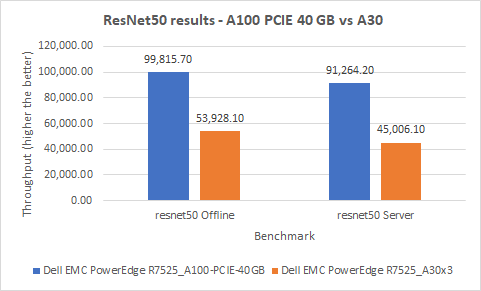
Hình 1: Kết quả ResNet50 trên máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
BERT
Biểu diễn bộ mã hóa hai chiều từ Transformers (BERT) là một mô hình biểu diễn ngôn ngữ tiên tiến nhất. Về bản chất, BERT là một chồng các bộ mã hóa Transformer. Kiến trúc Transformer nhanh vì nó có thể xử lý các từ đồng thời và ngữ cảnh của các từ có thể được học đồng thời từ cả hai hướng. BERT có thể được sử dụng để dịch máy thần kinh, trả lời câu hỏi, phân tích tình cảm và tóm tắt văn bản, tất cả đều yêu cầu hiểu ngôn ngữ. BERT được đào tạo theo hai giai đoạn: đào tạo trước trong đó mô hình hiểu ngôn ngữ và ngữ cảnh và tinh chỉnh trong đó BERT học các nhiệm vụ cụ thể như đặt câu hỏi và trả lời. Để hiểu sâu hơn, hãy xem BERT: Đào tạo trước về Máy biến áp hai chiều sâu để hiểu ngôn ngữ từ Google AI Language.
Đối với mô hình này, chúng tôi đã tiến hành tám thử nghiệm trên các hệ thống của mình, trong đó chúng tôi đã xem xét chế độ mặc định và độ chính xác cao trong cả trường hợp Máy chủ và Ngoại tuyến. Ở chế độ mặc định, máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn 69% so với máy chủ PowerEdge R7525 với GPU A30 trong kịch bản Ngoại tuyến và tốt hơn 99% trong kịch bản Máy chủ. Chế độ độ chính xác cao cung cấp kết quả tương tự, trong đó máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn 72% so với máy chủ PowerEdge R7525 với GPU A30 trong kịch bản Ngoại tuyến và tốt hơn 96% trong kịch bản Máy chủ. Trong hình dưới đây, bert-99 đề cập đến mục tiêu có độ chính xác mặc định, trong khi bert-99.9 đề cập đến mục tiêu có độ chính xác cao.
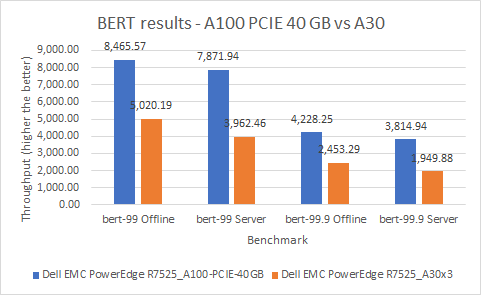
Hình 2: Kết quả BERT trên PowerEdge R7525 với GPU A100 và PowerEdge R7525 với GPU A30
SSD-ResNet34
ResNet34 là một bộ mã hóa nằm trên Bộ dò nhiều hộp một lần (SSD) được sử dụng để cải thiện hiệu suất và giảm thời gian đào tạo. Như biểu mẫu đầy đủ cho thấy, SSD là mô hình phát hiện đối tượng một giai đoạn được biết đến với tốc độ. Để hiểu sâu hơn, hãy xem Phát hiện đối tượng nhỏ bằng bối cảnh và sự chú ý .
Đối với mô hình này, chúng tôi đã tiến hành bốn thử nghiệm trên cả hai hệ thống của mình. Trong kịch bản Ngoại tuyến, máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn máy chủ PowerEdge R7525 với GPU A30 tới 74%. Tương tự, trong kịch bản Máy chủ, máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn 78% so với máy chủ PowerEdge R7525 với GPU A30.
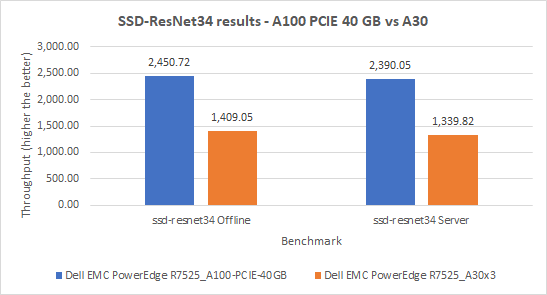
Hình 3: Kết quả SSD-ResNet34 trên máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
DLRM
DLRM, Mô hình đề xuất Deep Learning mã nguồn mở, có sẵn trên nền tảng PyTorch của Facebook. Mô hình này bao gồm các tri giác đa lớp (MLP) do điện toán chi phối và dựa vào tính song song của dữ liệu để cải thiện hiệu suất. Ví dụ: khi dự đoán tỷ lệ nhấp chuột cho một số mục nhất định, nó được căn chỉnh theo thuật toán Las Vegas ngẫu nhiên, trong đó tài nguyên (thời gian và bộ nhớ) được sử dụng tự do nhưng kết quả luôn chính xác. DLRM sử dụng các phương pháp tiếp cận dựa trên phân tích dự đoán và lọc cộng tác để xử lý lượng lớn dữ liệu. Để biết thêm thông tin về DLRM, hãy xem Mô hình Đề xuất Deep Learning cho Hệ thống Đề xuất và Cá nhân hóa .
Đối với mô hình này, chúng tôi đã tiến hành tám thử nghiệm trên cả hai hệ thống của mình. Đối với máy chủ PowerEdge R7525 có GPU A100, chúng tôi nhận thấy phạm vi hẹp với giới hạn dưới và giới hạn trên lần lượt là 764.569 và 768.806 mẫu kết quả mỗi giây. Ngoài ra, các kết quả được tạo ra qua các bài kiểm tra mặc định và độ chính xác cao đều giống nhau đối với các hệ thống tương ứng của chúng. Những con số ban đầu từ máy chủ PowerEdge R7525 với GPU A30 thấp hơn một chút so với mong đợi. Sau thời hạn gửi, nhóm của chúng tôi đã có thể trích xuất hiệu suất bổ sung, đặc biệt là trong kịch bản Máy chủ. Các số cho máy chủ PowerEdge R7525 với GPU A30 được hiển thị trong hình dưới đây không giống với các số được công bố trên trang web MLCommons. Tuy nhiên, những con số này là hợp lệ và vượt qua tất cả các bài kiểm tra tuân thủ bắt buộc. Máy chủ PowerEdge R7525 với GPU A30 hoạt động giống như máy chủ PowerEdge R7525 với GPU A100 trong đó kết quả kịch bản Máy chủ thấp hơn một chút so với kết quả Ngoại tuyến. Các con số được điều chỉnh mang lại hiệu suất tốt nhất trên mỗi thẻ trong số tất cả các lần gửi GPU A30.
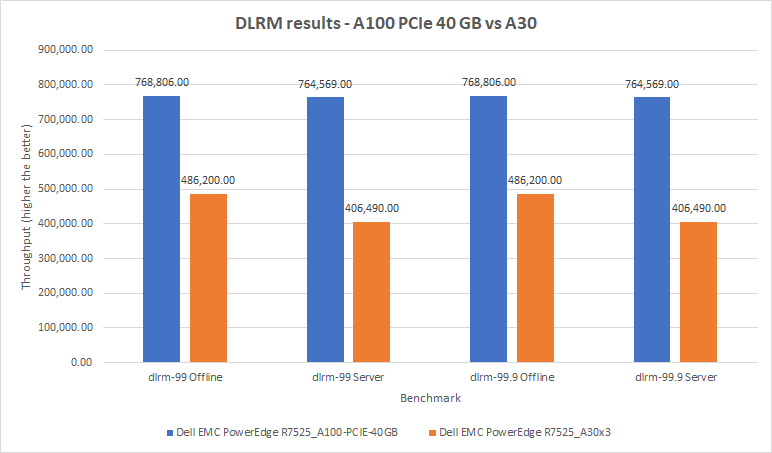
Hình 4: Kết quả DLRM trên máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
RNNT
Mạng thần kinh tái phát (RNNT) là một loại mạng thần kinh trong đó đầu ra được tái chế làm đầu vào cho bước hiện tại. Bằng cách sử dụng bộ nhớ và mã hóa một lần nóng, RNNT có thể ghi nhớ thông tin theo thời gian có thể hữu ích trong dự đoán chuỗi thời gian. Mô hình này sử dụng chức năng nén để học cách dự đoán từ hoặc bước tiềm năng tiếp theo sẽ thực hiện. Kết quả của hàm nén luôn nằm trong khoảng từ –1 đến 1, điều này cho phép mạng nơ-ron duy trì trạng thái phi tuyến tính và do đó có hiệu quả khi các giá trị giống nhau được truyền qua mạng nơ-ron.
Đối với mô hình này, chúng tôi đã tiến hành bốn thử nghiệm trên cả hai hệ thống của mình. Trong kịch bản Ngoại tuyến, máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn máy chủ PowerEdge R7525 với GPU A30 tới 80%. Trong kịch bản Máy chủ, máy chủ PowerEdge R7525 với GPU A100 xuất sắc bằng cách hoạt động tốt hơn 199 phần trăm so với máy chủ PowerEdge R7525 với GPU A30.
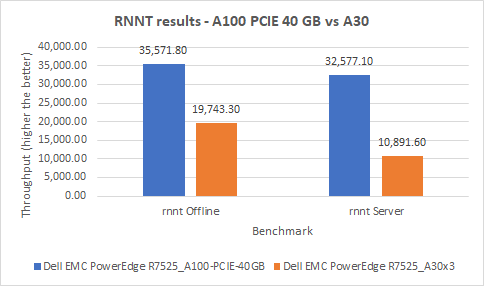
Hình 5: Kết quả RNNT trên máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
U-Net 3D
3D U-Net là một cải tiến tao nhã đối với cách tiếp cận cửa sổ trượt của mạng thần kinh tích chập (CNN), trong đó có thể sử dụng ít hình ảnh đào tạo hơn và có thể tạo ra các phân đoạn chính xác hơn. Tóm lại, một hình ảnh đầu vào đi qua một đường dẫn thu nhỏ và mở rộng (trong kiến trúc hình chữ U với các kết nối bỏ qua) và trở thành đầu ra của bản đồ phân đoạn. Bản đồ phân đoạn này cung cấp nhãn lớp cho những gì bên trong hình ảnh. Để hiểu sâu hơn về kiến trúc của 3D U-Net, hãy xem U-Net: Convolutional Networks for Biomedical .
Trên cả hai hệ thống, chúng tôi đã tiến hành kiểm tra kịch bản Ngoại tuyến cho chế độ mặc định và độ chính xác cao. Các chế độ mặc định và độ chính xác cao mang lại kết quả giống nhau trên hai hệ thống. Trên cả hai hệ thống, máy chủ PowerEdge R7525 với GPU A100 hoạt động tốt hơn 75% so với máy chủ PowerEdge R7525 với GPU A30.
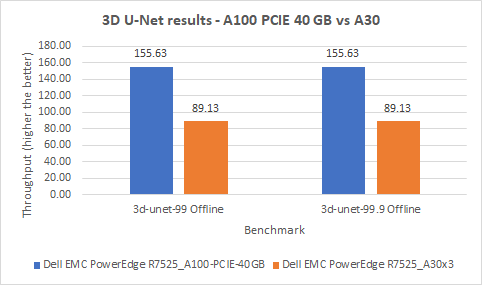
Hình 6: Kết quả 3D U-Net trên máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
Cân nhắc chi phí
Khi đặt hàng cho Máy chủ Rack PowerEdge R7525trên trang web của Dell Technologies, khách hàng được hướng dẫn về quy trình mua hàng với các đề xuất và yêu cầu đối với máy chủ giá đỡ cụ thể của họ. Máy chủ PowerEdge R7525 với ba GPU NVIDIA Ampere A100 đắt hơn 1,423 lần so với máy chủ PowerEdge R7525 với ba GPU NVIDIA Ampere A30. Sự khác biệt về giá giữa hai cấu hình là do GPU mạnh mẽ. Ngoài ra, máy chủ PowerEdge R7525 với GPU A100 yêu cầu quạt hiệu suất cao hơn và cấu hình nhiệt mạnh hơn. Mặc dù có các tùy chọn bổ sung cần thiết cho máy chủ PowerEdge R7525 với GPU A100, việc hiểu hiệu suất thông lượng (truy vấn mỗi giây (QPS) ở chế độ Máy chủ và mẫu mỗi giây ở chế độ Ngoại tuyến) trên mỗi đô la cung cấp thông tin chi tiết có giá trị về hiệu suất có thể đạt được trên mỗi đô la chi tiêu.
Hình dưới đây cho thấy hiệu suất tương đối của hai hệ thống trên mỗi đô la. Nếu chúng tôi chia hiệu suất đạt được trên một hệ thống cho một điểm chuẩn cụ thể cho tổng chi phí của hệ thống, chúng tôi sẽ xác định thông lượng có thể đạt được trên mỗi đô la chi cho hệ thống. Thông lượng trên mỗi đô la càng cao cho thấy rằng hiệu suất cao hơn có thể được trích xuất từ hệ thống trên mỗi đô la chi tiêu.
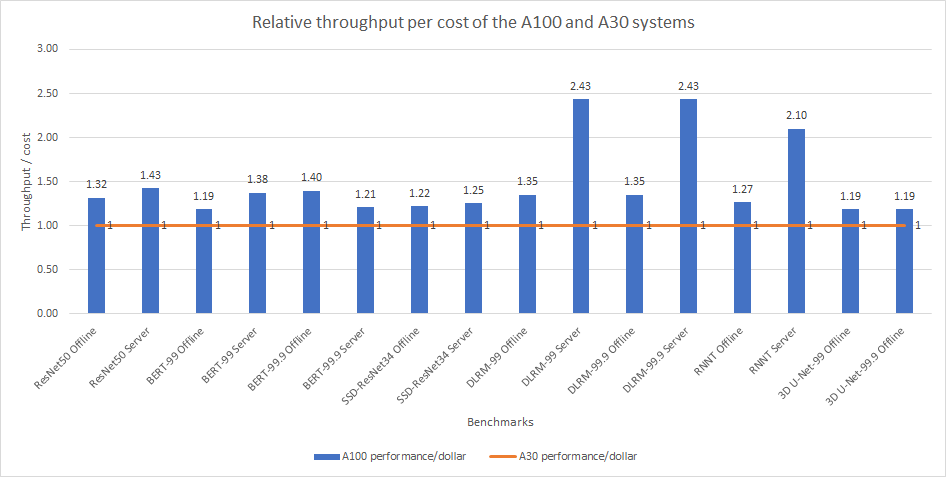
Hình 7: QPS tương đối trên mỗi chi phí của máy chủ PowerEdge R7525 với GPU A100 và máy chủ PowerEdge R7525 với GPU A30
Trong hình, đường màu cam hiển thị dữ liệu đã chuẩn hóa của thông lượng trên mỗi chi phí của máy chủ PowerEdge R7525 với GPU A30. Các thanh màu xanh biểu thị hiệu suất tương đối có thể đạt được của máy chủ PowerEdge R7525 với GPU A100. Đối với hầu hết các điểm chuẩn, chúng tôi thấy phạm vi hiệu suất có thể chấp nhận được trên cả hai hệ thống. Tuy nhiên, máy chủ PowerEdge R7525 với GPU A100 vượt trội hoàn toàn so với máy chủ PowerEdge R7525 với GPU A30 ở chế độ mặc định và độ chính xác cao của Máy chủ DLRM cũng như ở chế độ Máy chủ RNNT. Cả hai hệ thống đều hoạt động tốt trên mỗi đô la chi tiêu.
Lưu ý : Chúng tôi đã tổng hợp dữ liệu chi phí trong phần này từ trang Máy chủ dạng rack PowerEdge R7525 trên trang web Dell Technologies vào ngày 7 tháng 9 năm 2021. Dữ liệu có thể thay đổi.
Sự kết luận
Blog cung cấp một so sánh chi tiết về hiệu suất giữa máy chủ Dell EMC PowerEdge R7525 được cấu hình với ba A100 và máy chủ Dell EMC PowerEdge R7525 được cấu hình với ba GPU A30. Nếu khối lượng công việc ML của bạn tập trung vào khả năng suy luận, thì máy chủ PowerEdge R7525 được định cấu hình với A100 có thể phù hợp với nhu cầu của bạn. Tuy nhiên, nếu bạn đang tìm kiếm một hệ thống không chỉ hoạt động tốt mà còn tiết kiệm chi phí hơn, máy chủ PowerEdge R7525 được cấu hình với GPU A30 sẽ phù hợp với nhu cầu đó. Cả hai hệ thống đều hoạt động tốt và là một khoản đầu tư tuyệt vời dựa trên các yêu cầu về khối lượng công việc ML của bạn.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...