
Tin tức
Sử dụng Thế hệ tăng cường truy xuất (RAG) trên Tập dữ liệu PDF tùy chỉnh với Dell Technologies
Sự chuyển đổi AI sáng tạo
Trí tuệ nhân tạo đang biến đổi toàn bộ bối cảnh CNTT và cuộc sống số của chúng ta. Chúng ta đã chứng kiến một số đột phá lớn làm thay đổi tiến trình công nghệ trong vài thập kỷ qua. Sự ra đời của Internet, thực tế ảo, in 3D, container hóa, v.v. đã góp phần tạo ra những thay đổi lớn về hiệu quả cũng như dân chủ hóa các công cụ cần thiết để tạo ra trong những không gian đó.
AI sáng tạo (GenAI) hiện là nhân tố đột phá lớn, buộc tất cả chúng ta phải suy nghĩ lại về những bước nhảy vọt về hiệu quả có thể, nên và không nên thực hiện với công nghệ mới này.
Trên quỹ đạo hiện tại, ngành công nghiệp AI lớn hơn có tiềm năng thay đổi toàn bộ nền kinh tế. AI không phải là điều quá mới mẻ. Trong thập kỷ qua, những trở ngại từng cản trở sự phát triển đã được loại bỏ nhờ những tiến bộ vượt bậc trong công nghệ GPU, nguồn dữ liệu dồi dào và đại dương dung lượng lưu trữ phân tán rộng lớn.
Ngày nay, chúng ta phải phân biệt giữa AI truyền thống – được sử dụng để thực hiện các nhiệm vụ cụ thể và đưa ra dự đoán dựa trên các mẫu – và GenAI – được sử dụng để tạo ra dữ liệu mới giống với nội dung giống con người.
Với các mô hình ngôn ngữ lớn GenAI (LLM) dẫn đầu nhóm cải tiến AI mới nhất, chúng ta hãy tạm dừng một chút và tự hỏi: “Tại sao nó đột nhiên trở nên phổ biến?”, “Nó hoạt động như thế nào?”, và quan trọng hơn là , “Làm cách nào tôi có thể làm cho nó hoạt động tốt hơn?” Không có cách nào tốt hơn để trả lời những câu hỏi này hơn là đi sâu vào mã khiến GenAI trở thành một mặt hàng hấp dẫn.
Nhiệm vụ của chúng tôi ngày hôm nay với GenAI
Nếu tôi hỏi bạn một câu hỏi ngẫu nhiên, rất có thể bạn có thể trả lời nó một cách phức tạp, chính xác và đúng ngữ pháp – một cách “giống con người”. Nếu tôi hỏi bạn về ô tô, rất có thể chủ đề về lốp xe sẽ xuất hiện vì ô tô và lốp xe có mối quan hệ chặt chẽ. Câu trả lời của bạn có thể sẽ không chứa bất cứ điều gì về ngựa vằn vì ngựa vằn và ô tô không có mối liên hệ chặt chẽ với nhau. Nếu tôi hỏi bạn về một tòa nhà chọc trời thì sao? Từ “tòa nhà” có liên quan chặt chẽ đến các tòa nhà chọc trời, nhưng tại sao không phải là từ “mặt trăng” hay “con chim” – chúng cũng ở trên bầu trời phải không?

Để đạt được phản hồi làm hài lòng chúng tôi, chúng tôi muốn một câu trả lời chính xác được đưa ra cho chúng tôi theo cách giống con người. Hai khái niệm đó – “độ chính xác” và “giống con người” – là những sợi chỉ chung xuyên suốt mã cho tất cả quá trình phát triển AI tổng quát.
Phản hồi truyền thống của AI là “có” hoặc “không” có thể duy trì độ chính xác cao, nhưng đó có phải là điều tôi muốn cung cấp cho người dùng hoặc khách hàng của mình không? Một phản ứng nhị phân khô khan, robot? Tuyệt đối không. Tôi muốn một phản hồi giống con người cung cấp bối cảnh và trợ giúp bổ sung. Tôi muốn phản hồi có thể giải quyết vấn đề của tôi một cách trực tiếp thông qua các hành động tự động hoặc gián tiếp bằng cách cho phép tôi tự giúp mình. Nếu chúng ta không thể có được tất cả những thứ này thì tại sao phải bận tâm xây dựng bất kỳ thứ gì trong số đó?
Có được phản ứng giống con người có giá trị to lớn và là điều mà thị trường mong muốn. Vậy làm thế nào để chúng ta nhân bản hóa phản hồi do máy tính tạo ra? Nó cần có bộ não.

Bộ não con người là những cỗ máy khớp mẫu khổng lồ dựa trên hàng triệu kết nối thần kinh vật lý. Về cơ bản, AI phản chiếu các kết nối vật lý đó dưới dạng chuỗi quan hệ số gọi là vectơ. Độ chính xác đến từ hàng nghìn mối quan hệ đan xen của kiến thức tổng quát về các sự việc riêng lẻ. Mỗi “thứ” bạn cung cấp cho mô hình AI, cho dù đó là pixel hay từ, đều được số hóa và gắn nhãn dưới dạng vectơ có giá trị và vị trí duy nhất, trên hình ảnh hoặc trong câu.
Sau khi số hóa nội dung của mình thành dạng mà máy tính có thể hiểu được, chúng tôi có thể bắt đầu phân tích nội dung đó để tìm các mẫu mối quan hệ và cuối cùng xây dựng một mô hình có khả năng cung cấp phản hồi chính xác, giống con người dựa trên các mối quan hệ được đưa ra.
Xác định vấn đề
Có hàng tá LLM chính để lựa chọn và hàng nghìn biến thể tự chế. Mỗi mô hình hỗ trợ các tính năng và trường hợp sử dụng riêng biệt, vì vậy việc chọn đúng mô hình là rất quan trọng. Trước tiên hãy xác định vấn đề của chúng ta và sau đó xác định lựa chọn mô hình.
Công ty mẫu của chúng tôi muốn cải thiện trải nghiệm tổng thể của khách hàng khi trò chuyện với bộ phận hỗ trợ. Bên cạnh việc cải thiện thời gian phản hồi và cung cấp lộ trình tự trợ giúp tốt hơn, họ muốn tích hợp các bài viết cơ sở kiến thức cũ và tương lai vào một chatbot của bộ phận trợ giúp có thể trả lời các câu hỏi bằng thông tin mới thu được từ tập dữ liệu pdf của họ. Trong ví dụ này, chúng tôi sẽ sử dụng bộ sưu tập sách trắng và đồ họa thông tin từ Dell Infohub .
Đào tạo mô hình từ đầu so với tinh chỉnh so với RAG
Nếu ngành của bạn có tính chuyên môn cao và có vốn từ vựng khá độc đáo – chẳng hạn như pháp lý, y tế hoặc khoa học – hoặc doanh nghiệp của bạn yêu cầu mức độ riêng tư cao trong đó việc trộn lẫn dữ liệu có nguồn gốc công khai và riêng tư bị cấm, thì việc đào tạo một mô hình từ đầu có thể là con đường để lấy.
Trong hầu hết các trường hợp, việc sử dụng mô hình nguồn mở hiện có rồi tinh chỉnh nó để kích hoạt một tác vụ mới được ưu tiên hơn vì nó yêu cầu ít tính toán hơn và tiết kiệm rất nhiều thời gian. Với sự cân bằng hợp lý giữa điện toán, lưu trữ và phần mềm, việc tinh chỉnh mô hình hiện có có thể cực kỳ hiệu quả.
Nếu mô hình phản hồi của bạn tốt và thực hiện được nhiệm vụ bạn muốn nhưng có thể sử dụng một số nội dung học tập cụ thể dựa trên nội dung từ tập dữ liệu tài liệu tùy chỉnh – ví dụ như cơ sở kiến thức – thì Tạo tăng cường truy xuất (RAG) sẽ là ứng cử viên sáng giá cho loại khối lượng công việc này .
Tại sao nên sử dụng Thế hệ tăng cường truy xuất?
Tạo tăng cường truy xuất (RAG) được sử dụng trong các ứng dụng LLM để truy xuất nội dung kiểu cơ sở kiến thức có liên quan, tăng cường lời nhắc người dùng bằng nội dung dành riêng cho miền này, sau đó đưa cả lời nhắc và nội dung vào LLM để tạo ra phản hồi hữu ích, đầy đủ hơn.
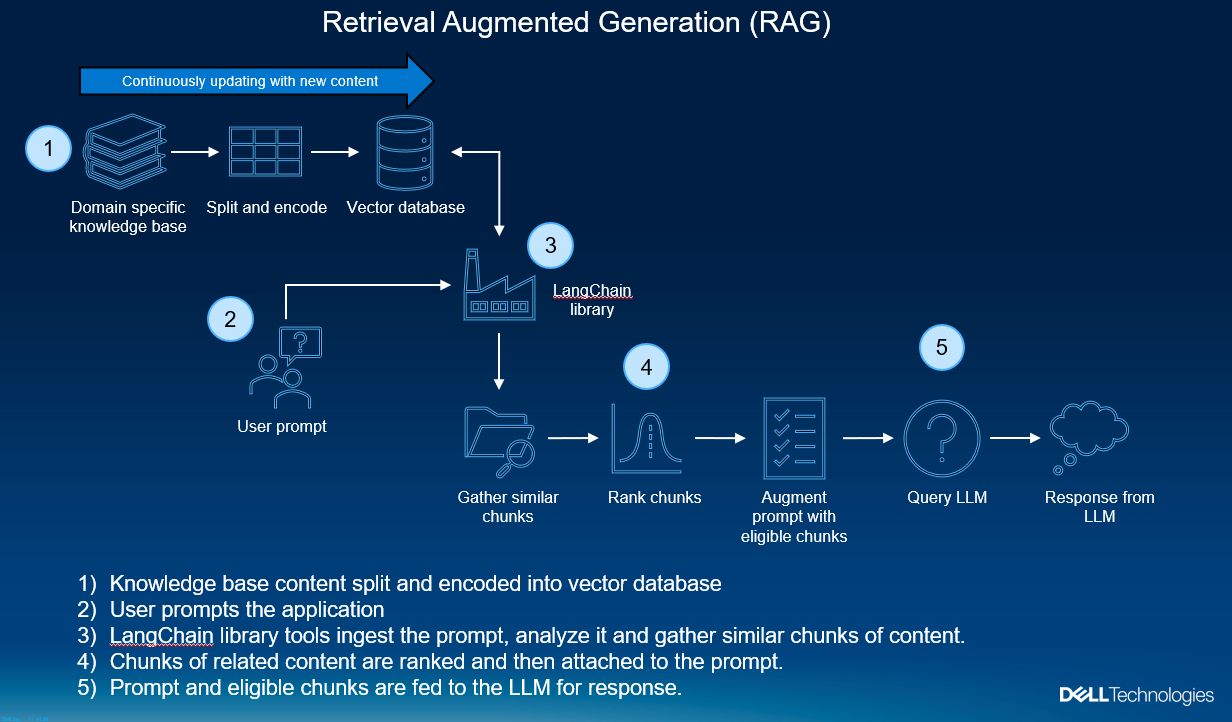
Hình 1. Hiểu cách hoạt động của RAG
Vậy RAG hoạt động như thế nào? Hãy tưởng tượng bạn đang ở một nhà hàng, hỏi người phục vụ một câu hỏi về việc kết hợp rượu vang. Theo cách tương tự này, bạn là người dùng đang nhập lời nhắc câu hỏi và người phục vụ là mô hình LLM của chúng tôi. Người phục vụ chắc chắn có những gợi ý kết hợp cơ bản – “Rượu vang đỏ kết hợp tốt với thịt bò” – nhưng câu trả lời này không nói lên điều gì về lịch sử kết hợp hàng thế kỷ, xu hướng rượu vang gần đây hay văn hóa hàng thập kỷ của nhà hàng này. Phản hồi rất khô khan này cũng không tính đến lượng hàng tồn kho hiện tại của nhà hàng. Chúng ta không muốn người phục vụ gợi ý loại rượu hiện chưa có sẵn.
Với quy trình RAG, người phục vụ sẽ nhận câu hỏi, truy xuất thông tin lịch sử và cập nhật có liên quan cụ thể về nhà hàng (bao gồm cả hàng tồn kho) và tập hợp tất cả lại cho khách hàng. Nói như vậy, chỉ lấy thông tin thôi là chưa đủ. Khách hàng của chúng tôi cần một gợi ý đầy đủ thông tin hơn là bị ngập trong hàng loạt bài viết hoặc đoạn trích về việc kết hợp rượu vang. Đó là nơi LLM tỏa sáng.
LLM rất xuất sắc trong việc thu thập các khối nội dung lớn, khác nhau, sắp xếp chúng và đưa ra phản hồi giống con người. Câu hỏi ban đầu, cùng với tất cả các đoạn rượu và đồ ăn về việc ghép đôi, được đưa vào LLM, nhờ đó đưa ra câu trả lời đầy đủ hơn, hữu ích hơn mà không cần phải học lại những điều cơ bản. Điều đó có nghĩa là, người phục vụ của chúng tôi không cần phải trở thành người phục vụ rượu để đưa ra câu trả lời này. Không cần đào tạo lại. Quá trình RAG không yêu cầu thực hiện đào tạo tốn nhiều thời gian. LLM được đào tạo trước khi tham gia vào quá trình này. Chúng tôi chỉ đơn giản là làm cho kiến thức mới về miền cụ thể dễ dàng hơn để LLM tiếp thu.
Nhìn trộm dưới mui xe
Tất cả điều này được thực hiện bằng cách lấy các cơ sở kiến thức dành riêng cho từng miền (trong trường hợp này là tệp pdf), chia chúng ra một cách thông minh, sau đó mã hóa nội dung văn bản của các đoạn này thành các vectơ số dài.
Các vectơ đại diện cho văn bản gốc được đưa vào cơ sở dữ liệu vectơ có thể được truy vấn cực kỳ nhanh chóng. Cơ sở dữ liệu vectơ có nhiều loại và trường hợp sử dụng khác nhau . Trong ví dụ này, chúng tôi đang sử dụng ChromaDB , một cơ sở dữ liệu vectơ “thuần túy” được thiết kế để lưu trữ và truy xuất vectơ từ dữ liệu phi cấu trúc, chẳng hạn như văn bản, hình ảnh và tệp. Điều này hoàn hảo cho trường hợp sử dụng của chúng tôi khi chúng tôi lấy văn bản ngẫu nhiên từ các tài liệu không xác định ở nhiều định dạng khác nhau và chuyển đổi chúng thành vectơ được sử dụng để xây dựng mối quan hệ giữa lời nhắc và các đoạn nội dung.
Ở một khía cạnh nào đó, chúng ta có thể coi cơ sở dữ liệu vectơ là một dạng bộ nhớ dài hạn. Khi chúng tôi tiếp tục thêm nội dung mới vào đó và duy trì nội dung đó, LLM của chúng tôi có thể tham chiếu đến nội dung khi cơ sở dữ liệu mở rộng với thông tin mới.
Sử dụng câu hỏi ban đầu, cơ sở dữ liệu vectơ được truy vấn để tìm ra phần nào có liên quan nhất đến câu hỏi ban đầu. Các kết quả được xếp hạng về mức độ tương tự, theo đó chỉ nội dung phù hợp nhất mới đủ điều kiện được đưa vào LLM để tạo phản hồi.
Chọn LLM của chúng tôi
Chúng tôi sẽ sử dụng mô hình Meta Llama2 vì nó có thể được lượng tử hóa và chạy cục bộ ngay từ đầu, có nhiều kích cỡ khác nhau, hoạt động tốt hoặc tốt hơn ChatGPT và cũng có sẵn miễn phí cho mục đích thương mại. Llama2 còn có một cửa sổ ngữ cảnh có kích thước vừa phải cho phép người dùng giới thiệu văn bản dưới dạng câu hoặc toàn bộ tài liệu rồi tạo phản hồi từ thông tin mới.
Việc sử dụng Llama2 hoặc LLM nguồn mở khác tại chỗ cho phép kiểm soát hoàn toàn cả nội dung dành riêng cho miền của bạn và bất kỳ nội dung nào đi vào mô hình, chẳng hạn như lời nhắc hoặc thông tin độc quyền khác. Trên các mô hình tiền sẵn cũng không phải là các đối tượng có thể thực thi được vì chúng không có khả năng gửi lại dữ liệu riêng tư của bạn cho tác giả ban đầu.
Môi trường tính toán và lưu trữ
Môi trường vật lý của chúng tôi sử dụng VMware vSphere với tư cách là bộ ảo hóa trong cụm Đám mây riêng Dell APEX với các nút VxRail PowerEdge, mỗi nút có 3 GPU Nvidia T4. Bộ nhớ nằm trên vSAN cục bộ. Máy chủ sổ tay của chúng tôi đang chạy trong môi trường ảo Pytorch trên máy ảo Ubuntu 22.04 với Miniconda. Điều này cũng có thể chạy trên PowerEdge kim loại trần với bất kỳ hệ điều hành nào bạn chọn miễn là bạn có thể chạy máy tính xách tay Jupyter và có quyền truy cập vào GPU.
Những bước đầu tiên mã hóa GenAI
Khi thực hiện bất kỳ hình thức đào tạo hoặc tinh chỉnh nào, bạn sẽ cần quyền truy cập vào các mô hình, bộ dữ liệu và giám sát để có thể so sánh hiệu suất của nhiệm vụ đã chọn. May mắn thay, có những phiên bản mã nguồn mở miễn phí cho mọi thứ bạn cần. Chỉ cần thiết lập một tài khoản trên các trang web sau và tạo mã thông báo truy cập API để lấy các mô hình và bộ dữ liệu hàng đầu vào sổ ghi chép của bạn.
- Ôm mặt – thư viện, bộ dữ liệu, mô hình, ví dụ sổ ghi chép và hỗ trợ cộng đồng mã nguồn mở cực kỳ có giá trị và được sử dụng rộng rãi
- Trọng số và Xu hướng – bảng điều khiển giám sát dựa trên SaaS miễn phí để phân tích hiệu suất mô hình
- Github – thư viện, công cụ và ví dụ về sổ ghi chép mã nguồn mở
Cùng với những trang web đó, tại một thời điểm nào đó, bạn chắc chắn sẽ thử nghiệm hoặc sử dụng các phiên bản của mô hình Llama Meta (Facebook) . Bạn sẽ cần phải điền vào mẫu giấy phép đơn giản này.
- Mẫu giấy phép mô hình Llama : https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Thiết lập RAG trên mô hình Llama2 với tập dữ liệu PDF tùy chỉnh
Đầu tiên chúng ta đăng nhập vào Huggingface để chúng ta truy cập vào thư viện, mô hình và tập dữ liệu.
## code tự động đăng nhập vào ôm mặt, tránh nhắc nhở đăng nhập !pip cài đặt -U ôm mặt-trung tâm # nhận mã thông báo tài khoản của bạn từ https://huggingface.co/settings/tokens token = '<chèn mã thông báo của bạn vào đây>' từ đăng nhập nhập ômface_hub đăng nhập(token=token, add_to_git_credential=True)
Với mỗi sổ ghi chép bạn chạy, bạn sẽ phải cài đặt, nâng cấp và hạ cấp tất cả các loại thư viện. Các phiên bản được hiển thị rất có thể thay đổi theo thời gian với các tính năng được thêm hoặc không được dùng nữa. Nếu bạn gặp sự cố tương thích phiên bản, hãy thử nâng cấp hoặc hạ cấp thư viện bị ảnh hưởng.
!pip cài đặt ngọn đuốc !pip cài đặt máy biến áp !pip cài đặt langchain !pip cài đặt chromadb !pip cài đặt pypdf !pip cài đặt xformers !pip cài đặt câu_transformers !pip cài đặt Giảng viênNhúng !pip cài đặt pdf2image !pip cài đặt pycryptodome !pip cài đặt auto-gptq
Từ các gói mới được cài đặt của chúng tôi, hãy nhập một số thư viện mà chúng tôi cần. Hầu hết trong số này sẽ liên quan đến LangChain, một công cụ tuyệt vời để kết nối các thành phần LLM lại với nhau như đã thấy trước đây trong hình 1. Như bạn có thể thấy từ tiêu đề thư viện, LangChain có thể kết nối trình tải pdf và cơ sở dữ liệu vectơ của chúng tôi cũng như tạo điều kiện thuận lợi cho việc nhúng.
ngọn đuốc nhập khẩu từ auto_gptq nhập AutoGPTQForCausalLM từ nhập langchain HuggingFacePipeline, NhắcTemplate từ langchain.chains nhập RetrievalQA từ langchain.document_loaders nhập PyPDFDirectoryLoader từ langchain.embeddings nhập HuggingFaceInstructEmbeddings từ langchain.text_spitter nhập RecursiveCharacterTextSplitter từ langchain.vectorstores nhập Chroma từ nhập pdf2image Convert_from_path từ máy biến áp nhập AutoTokenizer, TextStreamer, đường ống THIẾT BỊ = "cuda: 0" nếu torch.cuda.is_available() khác "cpu"
Hãy kiểm tra môi trường GPU Nvidia của chúng tôi để biết tính khả dụng, quy trình và phiên bản CUDA. Ở đây, chúng ta thấy 3 GPU T4. Trình điều khiển hỗ trợ phiên bản CUDA lên tới 12.2 với khoảng 16Gb cho mỗi thiết bị và không có tiến trình đang chạy nào khác. Mọi thứ có vẻ tốt để bắt đầu cuộc chạy của chúng tôi.
!nvidia-smi +------------------------------------------------ --------------------------------------+ | Phiên bản trình điều khiển NVIDIA-SMI 535.113.01: 535.113.01 Phiên bản CUDA: 12.2 | |----------------------------------------------+------- ---------------+----------------------+ | Tên GPU Persistence-M | Bus-Id Disp.A | Không ổn định. ECC | | Fan Temp Perf Pwr: Cách sử dụng/Cap | Sử dụng bộ nhớ | GPU-Util Tính toán M. | | | | MIG M. | |====================================================== ================+=========================| | 0 Tesla T4 Tắt | 00000000:0B:00.0 Tắt | Tắt | | Không áp dụng 46C P8 10W / 70W | 5MiB / 16384MiB | Mặc định 0% | | | | Không áp dụng | +----------------------------------------------+------- ---------------+----------------------+ | 1 Tesla T4 Tắt | 00000000:14:00.0 Tắt | Tắt | | Không áp dụng 30C P8 10W / 70W | 5MiB / 16384MiB | Mặc định 0% | | | | Không áp dụng | +----------------------------------------------+------- ---------------+----------------------+ | 2 Tesla T4 Tắt | 00000000:1D:00.0 Tắt | Tắt | | Không áp dụng 32C P8 9W / 70W | 5MiB / 16384MiB | Mặc định 0% | | | | Không áp dụng | +----------------------------------------------+------- ---------------+----------------------+ +------------------------------------------------ --------------------------------------+ | Quy trình: | | GPU GI CI Loại PID Tên quy trình GPU Bộ nhớ | | ID Sử dụng ID | |===================================================== =========================================| | Không tìm thấy tiến trình đang chạy nào | +------------------------------------------------ --------------------------------------+
Hãy kiểm tra để đảm bảo chúng ta có thể tiếp cận một số tệp pdf trong kho lưu trữ của mình bằng cách đặt hình ảnh thu nhỏ của trang tệp pdf vào một mảng và gọi nó để xem trước.
pdf_images = Convert_from_path("pdfs-dell-infohub/apex-navigator-for-multicloud-storage-solution-overview.pdf", dpi=100) pdf_images[0]

Hãy gọi trình tải thư mục pdf từ LangChain để biết chúng tôi đang xử lý bao nhiêu trang.
trình tải = PyPDFDirectoryLoader("pdfs-dell-infohub") tài liệu = Loader.load() len(tài liệu) 791
Tiếp theo, hãy chia các trang thành các phần dữ liệu hữu ích. Mô hình hkunlp/người hướng dẫn lớn đã tải xuống giúp chúng tôi phân chia điều này một cách thông minh thay vì thông qua thuật toán vũ phu. Chúng tôi sử dụng các phần nhúng từ mô hình này để nhận dạng nội dung mới của mình. Ở đây chúng ta thấy rằng chúng ta đã chia cái này thành hơn 1700 phần.
embeddings = HuggingFaceInstructEmbeddings( model_name="hkunlp/instructor-large", model_kwargs={"device": DEVICE} ) text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64) văn bản = text_split.split_documents(docs) len(văn bản) 1731
Tiếp theo, chúng tôi chuẩn bị LLM để nhận cả phần nhắc nhở và phần liên quan từ quy trình truy xuất LangChain của chúng tôi. Chúng tôi sẽ sử dụng một biến thể của mô hình tham số 13 tỷ Llama2 cung cấp các bản sửa đổi (lượng tử hóa) được tối ưu hóa bộ nhớ để chúng tôi tải xuống.
model_name_or_path = "TheBloke/Llama-2-13B-chat-GPTQ" model_basename = "mô hình" tokenizer = AutoTokenizer.from_pretrain(model_name_or_path, use_fast=True) model = AutoGPTQForCausalLM.from_quantized( model_name_or_path, sửa đổi="gptq-4bit-128g-actorder_True", model_basename=model_basename, use_safetensors=Đúng, Trust_remote_code=Đúng, tiêm_fused_attention=Sai, thiết bị=THIẾT BỊ, quantize_config=Không có, )
Vì đây là một chatbot nên chúng ta cần tương tác trực tiếp với mô hình của mình. Chúng tôi thực hiện điều này bằng cách cài đặt mô-đun quy trình của Huggingface để tạo điều kiện truy cập vào mô hình của bạn và tạo phiên tương tác trò chuyện thô trực tiếp từ các ô mã sổ ghi chép của bạn.
text_pipeline = đường ống( "tạo văn bản", mô hình=mô hình, mã thông báo=mã thông báo, max_new_tokens=1024, nhiệt độ=0, top_p=0,95, lặp lại_hình phạt=1,15, người truyền phát=người truyền phát, )
Lời nhắc của chúng tôi rất quan trọng trong toàn bộ nỗ lực này. Chúng ta cần cho LLM biết cách ứng xử với các phản hồi. Lời nhắc hệ thống này, dựa trên lời nhắc mặc định cho mô hình Llama2, sẽ cung cấp đủ hướng dẫn để mang lại cho chúng tôi kết quả giống như con người sau khi nội dung và câu hỏi của chúng tôi được đưa vào đó.
SYSTEM_PROMPT = "Sử dụng các ngữ cảnh sau để trả lời câu hỏi ở cuối. Nếu bạn không biết câu trả lời, chỉ cần nói rằng bạn không biết, đừng cố bịa ra câu trả lời." mẫu = generate_prompt( """ {bối cảnh} Câu hỏi: {câu hỏi} """ , system_prompt=SYSTEM_PROMPT, )
Cuối cùng, chuỗi của chúng tôi có thể được xây dựng. LangChain liên kết trình truy xuất và LLM của chúng tôi với nhau, sau đó nhét các khối tài liệu vào dấu nhắc và chuyển nó như một truy vấn thông thường tới LLM đồng thời yêu cầu các khối tài liệu nguồn.
qa_chain = Truy xuấtQA.from_chain_type( llm=llm, chuỗi_type="thứ", Retriever=vectordb.as_retriever(search_kwargs={"k": 2}), return_source_documents=Đúng, chain_type_kwargs={"prompt": nhắc}, )
Hãy hỏi nó một câu hỏi chỉ có thể tìm thấy trong các tài liệu mới. Trong ví dụ này, chúng tôi đã chọn một câu hỏi rất cụ thể mà mô hình Llama2 chưa từng được đào tạo: “Bộ lưu trữ khối APEX có hỗ trợ nhiều vùng khả dụng không?” Câu trả lời được đưa ra là “có”. Mặc dù câu trả lời là tích cực nhưng mô hình này vẫn đi sâu vào chi tiết hơn nhiều về những gì nó tìm thấy, mang lại cho chúng ta phản hồi rất hữu ích, giống con người.
Chúng tôi cũng có thể chứng minh nguồn gốc của sự thật bằng cách sử dụng tính năng return_source_documents của LangChain và trả lại nguồn đó trong ô tiếp theo. Bằng cách này, không còn nghi ngờ gì nữa liệu phản ứng đó có phải là một phần của ảo giác hay không.
result = qa_chain("Bộ lưu trữ khối apex có hỗ trợ nhiều vùng khả dụng không?")
Dựa trên thông tin được cung cấp trong văn bản, câu trả lời là có. APEX Block Storage hỗ trợ các vùng đa sẵn sàng (AZ). Văn bản nêu rõ rằng "dữ liệu được phân phối trên ba vùng khả dụng trở lên" bằng cách sử dụng các bộ lỗi, cung cấp khả năng phục hồi mà không cần sao chép hoặc sao chép dữ liệu không cần thiết. in (kết quả["source_documents"][0].page_content) dữ liệu hoặc cần sử dụng tính năng sao chép trên các AZ. Tận dụng tính năng bộ lỗi gốc, dữ liệu được phân phối trên ba vùng sẵn sàng trở lên để cung cấp khả năng bảo vệ bổ sung chống lại lỗi AZ. Rất phù hợp cho khối lượng công việc đầy thử thách APEX Block Storage cung cấp các dịch vụ dữ liệu doanh nghiệp đã được chứng minh, chẳng hạn như cung cấp mỏng, kết xuất nhanh, sao chép, di chuyển khối lượng và sao lưu/khôi phục sang S3, những dịch vụ cần thiết để tự tin chạy các khối lượng công việc quan trọng trên đám mây công cộng. Với hiệu suất và khả năng mở rộng vượt trội, APEX Block Storage rất phù hợp để hỗ trợ cơ sở dữ liệu rất lớn, khối lượng công việc phân tích cũng như triển khai sản xuất và phát triển nhiều vùng chứa (Kubernetes). Và với các dịch vụ cấp doanh nghiệp và khả năng phục hồi được cung cấp trên đám mây, APEX Block Storage dành cho AWS và Microsoft Azure là giải pháp lý tưởng để chạy những khối lượng công việc khó khăn nhất của bạn trên đám mây công cộng với sự tự tin rằng bạn có thể đáp ứng SLA của mình. Thêm thông tin -------------------------------------------------- -
Hãy đặt một câu hỏi cụ thể hơn: “Cung cấp một ví dụ về mã để xác thực PowerFlex của tôi”.
LLM mang lại phản hồi rất dễ chịu, được định dạng tốt, lịch sự và hữu ích.
result = qa_chain("cung cấp một ví dụ về mã để xác thực powerflex của tôi") Dựa trên ngữ cảnh được cung cấp, đây là ví dụ về cách xác thực bằng PowerFlex bằng cách sử dụng Curl: ``` bash Curl --location --request POST 'https://<PFXM>/rest/auth/login' \ --header 'Loại nội dung: ứng dụng/json' \ --data-raw '{"tên người dùng": "<tên người dùng>", "mật khẩu": "<password>"}' ``` Ví dụ này sử dụng phương thức `POST` để gửi yêu cầu đăng nhập đến Trình quản lý PowerFlex, chỉ định tên người dùng và mật khẩu trong nội dung yêu cầu. Tùy chọn `--header` đặt tiêu đề `Content-Type` thành `application/json` và tùy chọn `--data-raw` gửi thông tin đăng nhập ở định dạng JSON. Lưu ý rằng bạn sẽ cần thay thế `<PFXM>` bằng tên máy chủ hoặc địa chỉ IP thực tế của Trình quản lý PowerFlex của bạn và `<username>` và `<password>` bằng tên người dùng và mật khẩu PowerFlex tương ứng của bạn.
Đưa AI vào dữ liệu của bạn
Chúng tôi đã chỉ ra sứ mệnh của GenAI là cung cấp các phản hồi chính xác, giống con người và RAG là một phương pháp có tác động thấp để tăng cường các phản hồi đó bằng nội dung tùy chỉnh của riêng bạn. Chúng tôi đã xem qua một số công cụ giúp tạo điều kiện thuận lợi cho quá trình này, chẳng hạn như LangChain, cơ sở dữ liệu vectơ và chính mô hình LLM.
Để thực sự làm cho những mô hình này tỏa sáng, bạn cần áp dụng dữ liệu của riêng mình, nghĩa là có chủ quyền về dữ liệu cũng như quyền truy cập an toàn vào dữ liệu của bạn. Đơn giản là bạn không đủ khả năng để bị rò rỉ dữ liệu riêng tư, có khả năng bị bắt và bị lộ một cách không thể kiểm soát trên toàn cầu .

Dữ liệu duy nhất của bạn có giá trị to lớn. Dell sẵn sàng giúp đưa AI vào dữ liệu của bạn và đạt được kết quả tốt nhất có thể với các giải pháp tùy chỉnh hoặc được cấu hình sẵn đáp ứng nhu cầu kinh doanh của bạn bất kể quỹ đạo, cho dù đó là sử dụng RAG, tinh chỉnh hay đào tạo từ đầu.
Với Thiết kế được xác thực của Dell cho AI sáng tạo với Nvidia , khách hàng có thể tối ưu hóa tốc độ triển khai của nền tảng AI mô-đun, an toàn và có thể mở rộng. Máy chủ Dell PowerEdge mang lại hiệu suất cao và độ tin cậy cực cao và có thể được mua theo nhiều cách khác nhau, bao gồm kim loại trần, được cấu hình sẵn với các ngăn xếp đám mây phổ biến như Nền tảng đám mây APEX của chúng tôi và dưới dạng đăng ký thông qua Dell APEX. Đơn giản hóa việc mở rộng dữ liệu có cấu trúc hoặc không cấu trúc của bạn cho GenAI bằng PowerFlex, PowerScale hoặc ObjectScale , được triển khai tại chỗ hoặc dưới dạng đăng ký trong các nhà cung cấp đám mây lớn. Dell không chỉ dừng lại ở trung tâm dữ liệu. Với máy trạm Dell Precision AI tại nơi làm việc, các nhà khoa học dữ liệu có thể tăng tốc độ đổi mới đối với khối lượng công việc nặng nề nhất.
Nếu bạn có bất kỳ câu hỏi nào hoặc cần hỗ trợ của chuyên gia, Dịch vụ Chuyên nghiệp của Dell có thể giúp xây dựng chiến lược GenAI dành cho doanh nghiệp cho các trường hợp sử dụng có giá trị cao và lộ trình để đạt được chúng.
Dell cho phép bạn duy trì chủ quyền và kiểm soát dữ liệu đồng thời đơn giản hóa các quy trình GenAI, mang lại kết quả mà bạn yêu cầu với các tùy chọn tài chính linh hoạt mà bạn xứng đáng có được.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...