
Vào những năm 1940, nhà vật lý Richard Feynman nổi tiếng với màn so tài với một chuyên gia bàn tính qua một loạt phép tính. Bàn tính xử lý các phép tính số học cơ bản như cộng và nhân một cách dễ dàng. Nhưng khi nói đến phép chia và căn bậc hai, Feynman đã vượt lên dẫn trước. Bàn tính bị giới hạn ở các phép tính số nguyên và dựa vào các phương pháp gián tiếp như phép trừ và ước lượng lặp đi lặp lại, khiến nó chậm hơn và kém chính xác hơn.
Máy tính thời kỳ đầu cũng có những hạn chế tương tự. Mặc dù nhanh hơn bàn tính, chúng vẫn dựa vào số học dấu phẩy cố định, một hệ thống chỉ có thể biểu diễn các số trong phạm vi hẹp và ngốn hết không gian bit chỉ để hiển thị phân số. Điều này khiến chúng khó xử lý các tác vụ đòi hỏi cả giá trị lớn và nhỏ, chẳng hạn như mô hình hóa các kiểu thời tiết hoặc mô phỏng các lực trong vật lý.
Số học dấu chấm động (FP) đã thay đổi điều đó. Nó cho phép máy tính biểu diễn một dải giá trị rộng với độ chính xác cao hơn và mở đường cho các GPU mạnh mẽ mà chúng ta sử dụng ngày nay.
Từ dấu chấm cố định sang dấu chấm động: Một sự thay đổi cần thiết
CPU và GPU hoạt động bằng cách sử dụng biểu diễn nhị phân. Mỗi số và dấu tương ứng của nó được mã hóa bằng một chuỗi các số 0 hoặc 1. Số dấu phẩy cố định là dạng đơn giản nhất trong hệ nhị phân này. Mỗi bit biểu diễn một bội số của hai.

Tương tự như bàn tính, định dạng này có những hạn chế đáng kể. Nó không cho phép độ chính xác phân số. Để khắc phục điều đó, chúng tôi bắt đầu chia chuỗi nhị phân thành các thành phần nguyên và phân số, phân tách bằng dấu thập phân.

Số dấu phẩy động đã giới thiệu một giải pháp sáng tạo. Thay vì sử dụng ký hiệu chuẩn để biểu diễn số, số dấu phẩy động sử dụng ký hiệu khoa học. Mỗi số được định nghĩa bằng một dấu, một số mũ và một phần thập phân:
Giá trị = -1 dấu * phần thập phân * 2 số mũ
Cấu trúc này cho phép máy tính biểu diễn một phạm vi giá trị rộng hơn nhiều. So với dấu chấm cố định, dấu chấm động cung cấp phạm vi và độ chính xác cao hơn:
Số dấu chấm động 32 bit (Tiêu chuẩn IEEE 754)
-
- Phạm vi: −3,4×10^38 đến +3,4×10^38
- Độ chính xác: Độ chính xác 7 chữ số thập phân
Điểm cố định 32 bit (định dạng Q16.16)
-
- Phạm vi: −3,28×10^4 đến +3,28×10^4
- Độ chính xác: Độ chính xác 5 chữ số thập phân
Ở dạng nhị phân, cách bố trí này cũng rất hiệu quả. Thay vì chia một chuỗi bit thành các thành phần nguyên và phân số, giờ đây nó được chia thành các thành phần mũ và phần thập phân.

Ví dụ trên cho thấy biểu diễn FP32 , là điểm tham chiếu phổ biến để đo độ chính xác. Các biểu diễn khác, như FP64 , cung cấp độ chính xác gấp đôi và được gọi là “độ chính xác kép”. Tương tự, FP16 cung cấp độ chính xác thấp hơn và được gọi là “độ chính xác một nửa”.
Các lập trình viên thường tối ưu hóa khối lượng công việc của mình dựa trên sự cân bằng giữa tốc độ và độ chính xác, sử dụng các biểu diễn dấu phẩy động khác nhau tùy thuộc vào nhiệm vụ của họ.
Các định dạng dấu chấm động phổ biến và các trường hợp sử dụng
-
- FP64 (Độ chính xác kép) : Được sử dụng cho các tác vụ có độ chính xác cao như động lực học phân tử hoặc mô phỏng vật lý, trong đó những sai sót nhỏ có thể dẫn đến lỗi. FP64 sử dụng 1 bit dấu, 8 bit mũ và 23 bit phân số. FP64 có độ chính xác cao nhưng tốc độ tính toán chậm hơn.

-
- FP16 (Half Precision) : Được tối ưu hóa về tốc độ và hiệu suất bộ nhớ. Phù hợp nhất cho đồ họa thời gian thực và các ứng dụng AI không yêu cầu độ chính xác cao. FP16 sử dụng 1 bit dấu, 5 bit mũ và 10 bit phân số. FP16 nhanh hơn FP64 và FP32 , nhưng độ chính xác thấp hơn.

-
- BF16 (Brain-Float 16) : Phổ biến trong học sâu, nơi các phép tính gần đúng được chấp nhận. Nó sử dụng 1 bit dấu, 8 bit mũ và 7 bit phân số. Được phát triển bởi Google Brain, BF16 mở rộng phạm vi của FP16 nhưng lại hy sinh một số chi tiết do độ chính xác mantissa hạn chế.

-
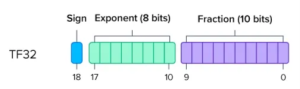
- TF32 (Tensor Float) : Được NVIDIA thiết kế cho học sâu, TF32 vẫn giữ nguyên phạm vi của FP32 đồng thời giảm độ chính xác để cải thiện tốc độ cho các tác vụ nặng về ma trận như huấn luyện mạng nơ-ron. TF32 sử dụng 19 bit, cắt giảm phân số từ 23 bit xuống còn 10 bit, và xấp xỉ các giá trị FP32 để tăng tốc hiệu suất mà không làm mất phạm vi số.
Với những tối ưu hóa dấu phẩy động này, chúng ta có thể tạo ra những tiến bộ mới trong khoa học và kỹ thuật. Từ tên lửa tái sử dụng của SpaceX, có thể tính toán góc phút từ khoảng cách hàng dặm đến các mô hình tài chính dự báo xu hướng kinh tế đến từng chữ số thập phân nhỏ nhất. Máy tính giờ đây có thể đạt đến những con số mà trước đây không thể tưởng tượng nổi.
Sự trỗi dậy của GPU: Kỷ nguyên mới của điện toán
Định dạng dấu chấm động nghe có vẻ như lý thuyết toán học trừu tượng, nhưng tác động của chúng lại hoàn toàn không phải lý thuyết. Hãy lấy SpaceX làm ví dụ, một công ty mà thành công thực sự phụ thuộc vào độ chính xác, tốc độ và khả năng mở rộng.
Tên lửa tái sử dụng của SpaceX sẽ không thể đạt được mức độ chính xác cần thiết chỉ với CPU tiêu chuẩn. Mặc dù CPU đã phát triển để hỗ trợ số học dấu phẩy động, nhưng về cơ bản chúng bị giới hạn về khả năng xử lý song song. Các tác vụ như kết xuất đồ họa, mô hình khoa học và AI thường giao tiếp với hàng nghìn, thậm chí hàng triệu phép tính dấu phẩy động cùng lúc, đặc biệt là các phép tính liên quan đến ma trận.
Nhu cầu này đã dẫn đến sự ra đời của các bộ xử lý đồ họa (GPU). GPU được thiết kế đặc biệt để tăng tốc tính toán song song. Không giống như CPU, GPU được trang bị các thành phần chuyên dụng như lõi Tensor và bộ xử lý Fused Multiply-Add (FMA) được tối ưu hóa cho các phép tính dấu chấm động.
Lõi Tensor, được NVIDIA giới thiệu, có tác động đặc biệt lớn. Chúng thực hiện phép cộng và phép nhân cùng lúc mà không cần làm tròn giữa các phép toán, một khả năng cho phép nhân ma trận nhanh chóng và chính xác. Chức năng này là nền tảng cho AI hiện đại và học sâu, biến Lõi Tensor trở thành động lực quan trọng cho những đột phá AI ngày nay.
Hỗ trợ phần cứng cho các định dạng dấu chấm động: GPU NVIDIA
Ngay cả với khả năng tăng tốc phần cứng, không phải GPU nào cũng hỗ trợ đồng đều mọi định dạng dấu chấm động. Một số nền tảng như GPU NVIDIA A100 và H100 hỗ trợ một loạt các định dạng linh hoạt bao gồm FP64 , FP32 , FP16 , BF16 và TF32 , khiến chúng trở nên cực kỳ linh hoạt. Các nền tảng khác, như NVIDIA A800, tập trung vào các khối lượng công việc đòi hỏi độ chính xác cao và được tối ưu hóa chủ yếu cho FP64 và FP32. Trong khi đó, Tesla P100 thuộc kiến trúc Ampere của NVIDIA lại tập trung vào FP32 và FP16 cho các phép tính AI.
Sự thay đổi này khiến việc lựa chọn phần cứng trở thành một phần quan trọng trong thiết kế hệ thống. Đối với các tác vụ như kết xuất 3D hoặc mô phỏng vật lý, một nền tảng máy tính cá nhân như Dell Pro Max Tower T2 , được trang bị GPU NVIDIA RTX PRO 6000 Blackwell , mang lại hiệu năng và độ chính xác cần thiết cho công việc tính toán chuyên sâu. Trong các thiết lập nghiên cứu AI, các nhóm thường sử dụng bộ hỗ trợ Tesla P100 , và phù hợp hơn để xử lý mô hình dữ liệu chuyên sâu với các tối ưu hóa FP16 và FP32 .
Ví dụ, SpaceX sử dụng GPU NVIDIA Jetson Orin NX trong các vệ tinh quỹ đạo Trái Đất thấp của họ. Các GPU NVIDIA này xử lý hình ảnh Trái Đất độ phân giải cao, phát hiện các thay đổi môi trường, theo dõi hệ thống thời tiết và tự động theo dõi vị trí tàu thuyền hoặc máy bay. Bằng cách thực hiện các phép tính này trên thiết bị, các vệ tinh giảm nhu cầu gửi dữ liệu trở lại Trái Đất để xử lý. Jetson Orin NX được tối ưu hóa cho FP16 , cho phép xử lý theo thời gian thực và tăng tốc độ so với độ chính xác cao của FP64 hoặc FP32 .

Tác động liên tục của độ chính xác dấu phẩy động
Sự phát triển của số dấu phẩy động là một ví dụ điển hình về khả năng giải quyết vấn đề sáng tạo đằng sau các hệ thống tính toán hiện đại. Từ bàn tính đến GPU, những tiến bộ trong biểu diễn số đã liên tục định nghĩa lại những gì có thể.
Ngày nay, GPU hỗ trợ mọi thứ, từ vệ tinh tự hành của SpaceX đến giao diện AI thời gian thực. Khi khối lượng công việc ngày càng phức tạp, AI tiếp tục đòi hỏi các phép toán nhanh hơn với độ chính xác cao. Định dạng dấu phẩy động và phần cứng được thiết kế để xử lý chúng hiệu quả vẫn đóng vai trò trung tâm trong tiến trình đó.
Các nền tảng như Dell Pro Max Tower T2 và tính linh hoạt cũng như hiệu suất cần thiết để tăng tốc các phép tính dấu phẩy động trên nhiều khối lượng công việc khác nhau.
Bạn đã sẵn sàng khám phá sức mạnh của độ chính xác dấu phẩy động chưa?
Từ mô hình khoa học đến tăng tốc học sâu, máy trạm Dell Pro Max với GPU NVIDIA RTX PRO được thiết kế để xử lý khối lượng công việc tính toán khắt khe nhất hiện nay, cục bộ, hiệu quả và có tính linh hoạt vô song.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...