
Tin tức
Tăng tốc đào tạo phân tán trong môi trường ảo hóa đa nút
Giới thiệu
Trong thời đại học sâu (DL), với các mô hình phức tạp, điều quan trọng là phải có một hệ thống cho phép đào tạo phân tán nhanh hơn. Tùy thuộc vào ứng dụng, một số mô hình DL yêu cầu đào tạo lại và tinh chỉnh các siêu tham số thường xuyên hơn để triển khai trong môi trường sản xuất. Điều quan trọng là phải hiểu các phương pháp hay nhất để cải thiện hiệu suất đào tạo phân tán đa nút.
Kết nối mạng rất quan trọng trong thiết lập đào tạo phân tán vì có nhiều gradient được trao đổi giữa các nút. Độ phức tạp tăng lên khi chúng ta tăng số lượng nút. Trước đây, chúng ta đã thấy những lợi ích của việc sử dụng:
- Truy cập bộ nhớ trực tiếp (DMA), cho phép thiết bị truy cập bộ nhớ máy chủ mà không cần sự can thiệp của CPU
- Truy cập bộ nhớ trực tiếp từ xa (RDMA), cho phép truy cập vào bộ nhớ trên máy từ xa mà không làm gián đoạn quá trình CPU trên hệ thống đó
Blog này kiểm tra hiệu suất khi giao tiếp trực tiếp được thiết lập giữa các GPU trong thử nghiệm đào tạo đa nút chạy trên máy chủ Dell PowerEdge với GPU NVIDIA và VMware vSphere.
GPURDMA trực tiếp
Được giới thiệu như một phần của GPU lớp Kepler và CUDA 5.0, GPUDirect RDMA cho phép đường dẫn liên lạc trực tiếp giữa GPU NVIDIA và các thiết bị của bên thứ ba như giao diện mạng. Bằng cách thiết lập giao tiếp trực tiếp giữa các GPU, chúng tôi có thể loại bỏ nút thắt cổ chai quan trọng khi dữ liệu cần được chuyển vào bộ nhớ hệ thống máy chủ trước khi có thể gửi qua mạng, như minh họa trong hình sau:
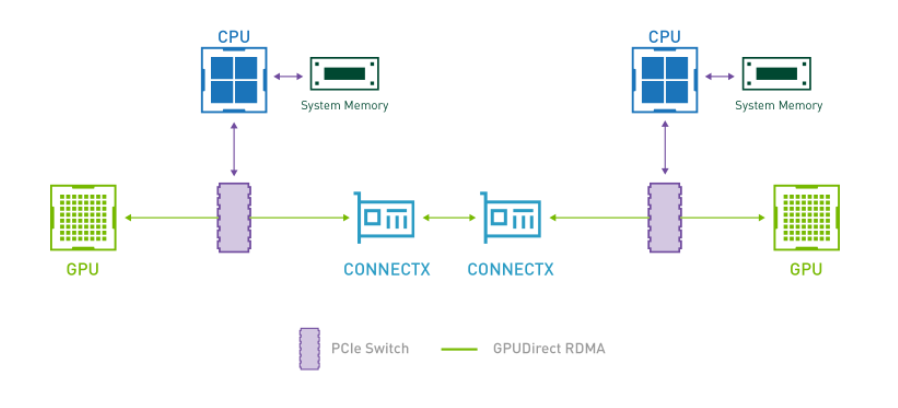
Hình 1: Giao tiếp trực tiếp – GPUDirect RDMA
Để biết thêm thông tin, xem:
Chi tiết hệ thống
Bảng sau đây cung cấp thông tin chi tiết về hệ thống:
Bảng 1: Chi tiết hệ thống
| Thành phần | Chi tiết |
| Máy chủ | Dell PowerEdge R750xa (Hệ thống được NVIDIA chứng nhận) |
| Bộ xử lý | 2 x CPU Intel Xeon Gold 6338 @ 2,00 GHz |
| GPU | 4 x NVIDIA A100 PCIe |
| Bộ điều hợp mạng | Mellanox ConnectX-6 Cổng kép 100 GbE và 25 GbE |
| Kho | Dell PowerScale |
| phiên bản ESXi | 7.0.3 |
| phiên bản sinh học | 1.1.3 |
| Phiên bản trình điều khiển GPU | 470.82.01 |
| Phiên bản CUDA | 11.4 |
Cài đặt
Thiết lập đào tạo đa nút trong môi trường ảo hóa được nêu trong blog trước của chúng tôi .
Ở mức cao, sau khi Dịch vụ dịch địa chỉ (ATS) được bật trên VMware ESXi, máy ảo và ConnectX-6 NIC:
- Cho phép ánh xạ giữa các cổng logic và vật lý.
- Tạo vùng chứa Docker với trình điều khiển Mellanox OFED, Thư viện MPI mở và TensorFlow được tối ưu hóa cho NVIDIA.
- Thiết lập đăng nhập SSH không cần chìa khóa giữa các máy ảo
Đánh giá hiệu suất
Để đánh giá, chúng tôi sử dụng tf_cnn_benchmarks bằng mô hình ResNet50 và dữ liệu tổng hợp với kích thước lô cục bộ là 1024. Mỗi VM được định cấu hình với 32 vCPU, bộ nhớ 64 GB và một GPU NVIDIA A100 PCIE 80 GB. Các thử nghiệm được thực hiện bằng cách sử dụng phương pháp song song dữ liệu trong thiết lập đào tạo phân tán, mở rộng tối đa bốn nút. Các kết quả được dựa trên trung bình ba lần chạy thử nghiệm. Các thử nghiệm nút đơn chỉ mang tính chất so sánh vì không có giao tiếp giữa các nút.
Lưu ý : Sử dụng tiện ích ibdev2netdev để hiển thị thẻ Mellanox ConnectX-6 đã cài đặt cùng với ánh xạ các cổng. Trong các hình sau, BẬT và TẮT cho biết liệu ánh xạ có được bật giữa các cổng logic và vật lý hay không.
Hình sau đây cho thấy hiệu suất khi mở rộng tối đa bốn nút bằng Cổng kép Mellanox ConnectX-6 100 GbE. Rõ ràng là thông lượng tăng đáng kể khi bật ánh xạ (BẬT), cung cấp khả năng liên lạc trực tiếp giữa các GPU NVIDIA. Các thử nghiệm hai nút cho thấy sự cải thiện về thông lượng là 18,7% trong khi các thử nghiệm bốn nút cải thiện thông lượng lên 26,7%.
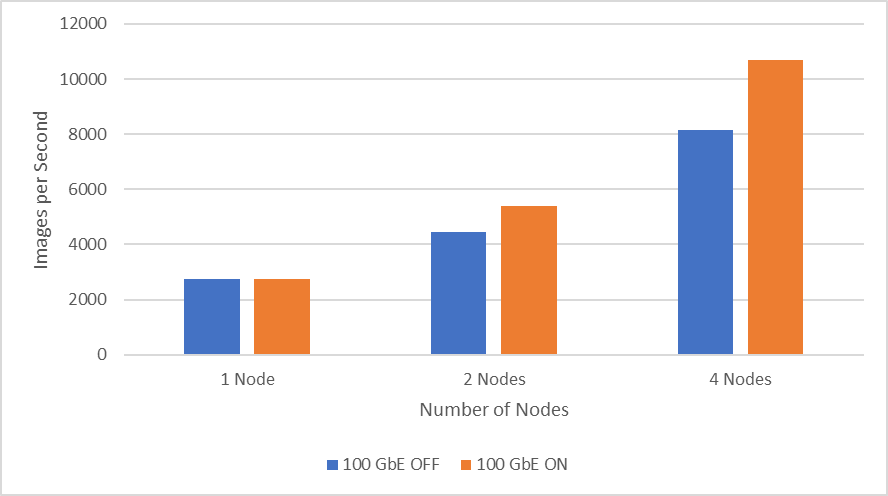
Hình 2: Hiệu suất mạng 100 GbE
Hình dưới đây cho thấy so sánh hiệu suất mở rộng giữa Mellanox ConnectX-6 Dual Port 100 GbE và Mellanox ConnectX-6 Dual Port 25 GbE trong khi thực hiện đào tạo phân tán của mô hình ResNet50. Khi sử dụng 100 GbE, kết quả thử nghiệm hai nút cho thấy thông lượng được cải thiện thêm 6% trong khi thử nghiệm bốn nút cho thấy hiệu suất được cải thiện 11,6% so với 25 GbE.
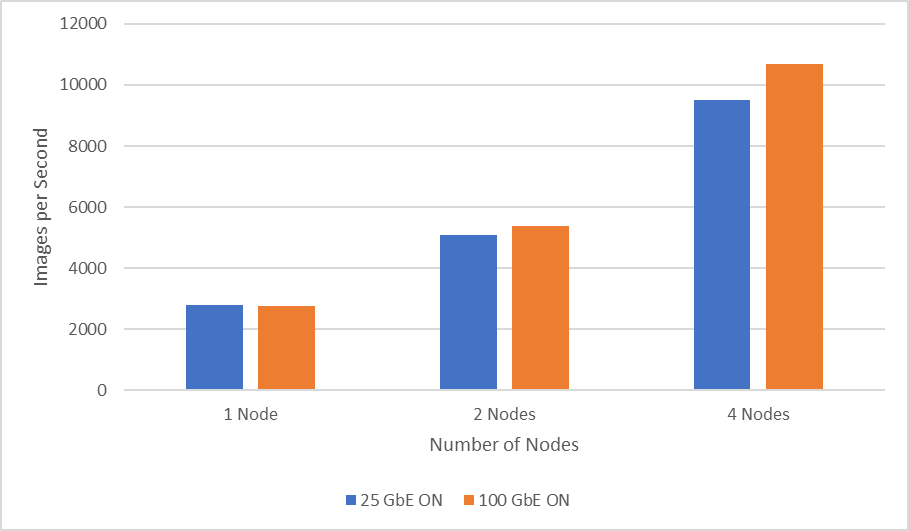
Hình 3: 25 GbE so với hiệu suất mạng 100 GbE
Phần kết luận
Trong blog này, chúng tôi đã xem xét GPUDirect RDMA và một số bước bắt buộc để thiết lập thử nghiệm nhiều nút trong môi trường ảo hóa. Kết quả cho thấy rằng việc mở rộng quy mô đến số lượng nút lớn hơn sẽ tăng thông lượng đáng kể khi thiết lập liên lạc trực tiếp giữa các GPU trong thiết lập đào tạo phân tán. Blog này cũng trình bày sự so sánh hiệu suất giữa các bộ điều hợp mạng Mellanox ConnectX-6 Dual Port 100 GbE và 25 GbE được sử dụng để đào tạo phân tán mô hình ResNet50.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...