
Tin tức
Thiết kế nghịch đảo đáp ứng dữ liệu lớn: Giải pháp dựa trên tia lửa để phát hiện bất thường theo thời gian thực
Thiết kế ngược là một quá trình trong đó bạn bắt đầu với kết quả mong muốn và mục tiêu hiệu suất. Nó hoạt động ngược lại để tìm ra cấu hình hệ thống và các tham số thiết kế nhằm đạt được mục tiêu thay vì thiết kế chuyển tiếp truyền thống hơn, trong đó các tham số đã biết sẽ định hình thiết kế.
Để xác định chính xác và kịp thời các điểm bất thường trong luồng dữ liệu lớn từ máy chủ, điều quan trọng là phải định cấu hình sự kết hợp tối ưu giữa các công nghệ. Trước tiên, chúng tôi chọn kỹ thuật mã hóa tự động định hình các phân tích đa biến, sau đó định cấu hình tích hợp Kafka-Spark-Delta cho luồng dữ liệu và cuối cùng chọn nhóm dữ liệu tại nguồn để phân tích kích hoạt.
Mô-đun iDRAC trong máy chủ Dell PowerEdge thu thập dữ liệu dải biên quan trọng trong ngân hàng cảm biến của nó. Dữ liệu này có thể được lập trình để truyền phát theo thời gian thực, nhưng không phải mọi tín hiệu (chuỗi dữ liệu) đều phù hợp với các mô hình trực tuyến sử dụng chúng. Ví dụ: nếu mục tiêu là tìm các máy chủ trong trung tâm dữ liệu đang quá nóng thì việc sạc pin dư bên trong máy chủ sẽ không hữu ích. Dữ liệu iDRAC có thể tổng hợp từ máy chủ PowerEdge được gộp trong bộ lưu trữ PowerScale được nối mạng. Các khối dữ liệu gần đây nhất được tải vào bộ nhớ để phát hiện sự bất thường trên các mẫu ngẫu nhiên. Các biến động theo thời gian được tính toán về cường độ dị thường sẽ hoàn tất quá trình tổng hợp thông tin từ dữ liệu thô. Hành trình được phân tách này từ dữ liệu thô được nhóm hợp lý đến thông tin sử dụng đặc tả cơ sở hạ tầng mạng Dell Data Lakehouse (DLH) (không hiển thị ở đây) sẽ kích hoạt hành động trong thời gian thực. Hình dưới đây mô tả kiến trúc:
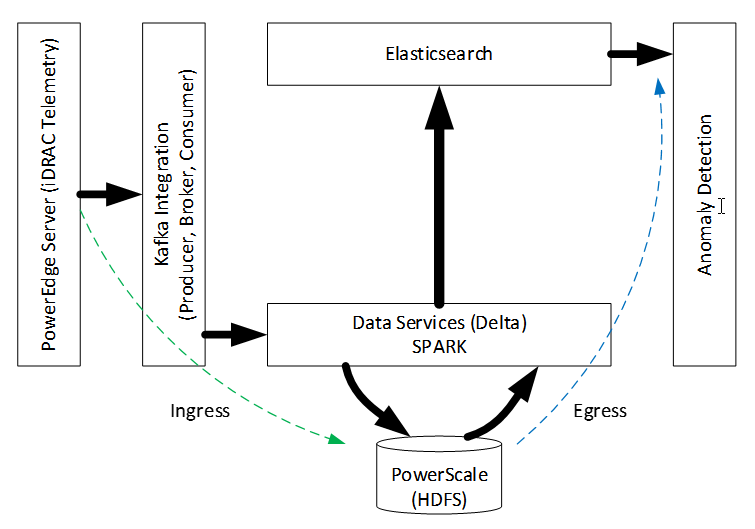
Hình 1. Kiến trúc đầu cuối cho phân tích phát trực tuyến
Quy trình có hai giai đoạn theo thứ tự─ đi vào và đi ra . Trong giai đoạn xâm nhập, các tính năng của mô hình mục tiêu (ví dụ: quá nhiệt) ảnh hưởng đến việc hỗ trợ dữ liệu, tần suất chụp và tham số hóa bộ truyền phát. Máy chủ iDRAC [1] ghi vào Kafka Pump (KP), diễn giải ngữ nghĩa gốc để Người tiêu dùng Kafka đa luồng sử dụng, như trong hình sau:
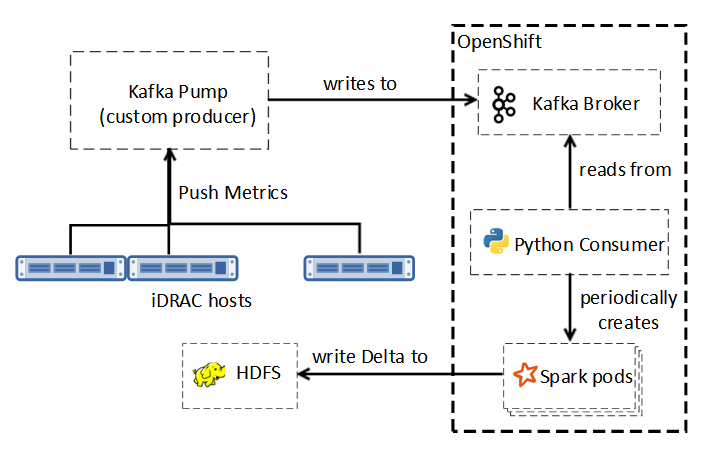
Hình 2. Kafka tới Delta
Luồng trình đọc thu thập dữ liệu từ bộ đệm đầu vào đã được định cấu hình trong khi luồng trình ghi xóa dữ liệu này theo định kỳ bằng cách ghép nối với bộ lưu trữ HDFS ở định dạng Delta, sử dụng dịch vụ Spark để tính toán trong bộ nhớ, khả năng mở rộng và khả năng chịu lỗi. Độ tin cậy, khả năng mở rộng, hiệu quả của HDFS và Delta Lake trong lưu trữ và quản lý dữ liệu, cùng với các cân nhắc về hiệu suất của Spark và Kafka đã ảnh hưởng đến lựa chọn của chúng tôi.
Ở giai đoạn đầu ra của quy trình, chúng tôi áp dụng phân tích cường độ bất thường cho mô hình bộ mã hóa tự động được huấn luyện trước [2] . Việc sử dụng GPU NVIDIA A100 đã tăng tốc quá trình đào tạo bộ mã hóa tự động. Elaticsearch đã giúp sàng lọc các mẫu ngẫu nhiên của gói dữ liệu máy chủ gần đây nhất để xác định điểm bất thường. Độ lệch lỗi điểm Z tổng hợp trên các mẫu này đã giúp mô tả cường độ dị thường đa biến chính xác (như được hiển thị trong hình sau), phép ngoại suy trong cửa sổ thời gian ghi lại những biến động không mong muốn. 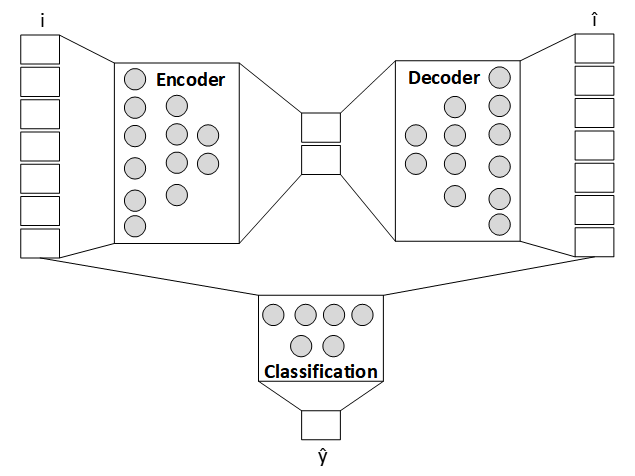
Hình 3. Phân tích bất thường
Chúng tôi đã sử dụng Matplotlib để kết xuất, nhưng bạn có thể tạo các sự kiện theo yêu cầu để điều chỉnh chất nền. Nếu khái quát hóa, phương pháp này có thể liên tục xác định các điểm bất thường của máy.
Phần kết luận
Trong PoC này, chúng tôi đã kết hợp một số công nghệ mới nổi. Chúng tôi đã sử dụng Kafka để nhập dữ liệu theo thời gian thực với Spark để xử lý hiệu suất cao đáng tin cậy, HDFS với Delta Lake để lưu trữ và phân tích nâng cao để phát hiện sự bất thường. Chúng tôi đã thiết kế giải pháp Spark để phát hiện sự bất thường theo thời gian thực. Bằng cách sử dụng bộ mã hóa tự động, được bổ sung chiến lược định lượng cường độ bất thường mà không yêu cầu bù sai lệch định kỳ, chúng tôi đã chứng minh rằng phân tích dữ liệu hiện đại tích hợp tốt trên cơ sở hạ tầng Dell DLH. Cơ sở hạ tầng này bao gồm Red Hat OpenShift, bộ lưu trữ Dell PowerScale, điện toán PowerEdge và các thành phần mạng PowerSwitch.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...