
Tin tức
Tối ưu hóa GPU với Run:ai Atlas
Tóm tắt điều hành
Phát triển mô hình AI là một quá trình phức tạp và đầy thách thức, không chỉ đòi hỏi các kỹ năng chuyên môn và chuyên môn về khoa học dữ liệu mà còn thường yêu cầu các tài nguyên điện toán quan trọng, chẳng hạn như phần cứng và thời gian. Không giống như quá trình phát triển phần mềm truyền thống, thường tuân theo quy trình tuyến tính, từng bước, việc phát triển mô hình AI mang tính lặp đi lặp lại và thử nghiệm. Các nhà phát triển thường đánh giá các thuật toán, kiến trúc và kỹ thuật đào tạo khác nhau để xem cái nào hoạt động tốt nhất cho một tác vụ hoặc tập dữ liệu cụ thể. Quá trình này làm cho các công cụ CNTT đã được thiết lập cho các nhiệm vụ như lập kế hoạch năng lực và quản lý hạn ngạch hầu như không còn phù hợp. Do đó, các nhóm CNTT và MLOps thường thấy mình có ít quyền kiểm soát và khả năng hiển thị hạn chế đối với việc phân bổ và sử dụng tài nguyên điện toán.
Nền tảng phần mềm Run:ai Atlas có thể hợp lý hóa quá trình phát triển, đào tạo và triển khai AI bằng cách điều phối các tài nguyên GPU. Bằng cách trừu tượng hóa cơ sở hạ tầng GPU cơ bản, Run:ai Atlas tối ưu hóa việc sử dụng các cụm AI bằng cách cho phép chia sẻ và chia sẻ tài nguyên linh hoạt giữa người dùng, nhóm và dự án. Phần mềm phân phối khối lượng công việc một cách linh hoạt – linh hoạt, không cần khởi động lại, thay đổi số lượng tài nguyên được phân bổ cho một công việc – cho phép các nhóm khoa học dữ liệu chạy nhiều thử nghiệm hơn trên cùng một phần cứng. Các nhóm CNTT giữ quyền kiểm soát bằng cách đặt các chính sách tự động để phân bổ tài nguyên và có được khả năng hiển thị theo thời gian thực, bao gồm thời gian chạy, hàng đợi và mức sử dụng GPU của từng công việc. Bảng điều khiển tập trung hiển thị các dự án và công việc trên nhiều trang web, cho dù tại cơ sở hay trên đám mây.
Mục đích tài liệu
Sách trắng kỹ thuật này mô tả việc điều phối tài nguyên GPU bằng nền tảng Run:ai Atlas trên Nền tảng Symcloud với cơ sở hạ tầng của Dell. Chúng tôi cung cấp kiến trúc tham chiếu cho nền tảng Run:ai Atlas và mô tả cách chúng tôi xác thực phần mềm.
Khán giả
Sách trắng kỹ thuật này dành cho những người ra quyết định, nhà quản lý, kiến trúc sư và quản trị viên kỹ thuật của môi trường CNTT trong bất kỳ lĩnh vực nào quan tâm đến việc khám phá và triển khai các giải pháp AI trên cơ sở hạ tầng tăng tốc GPU.
Tổng quan nền tảng
Bản tóm tắt
AI tác động đáng kể đến các doanh nghiệp trong các ngành vì nó cung cấp cho các tổ chức khả năng phân tích lượng dữ liệu khổng lồ và trích xuất thông tin chi tiết để tác động đến quá trình ra quyết định. Từ dịch vụ khách hàng đến quản lý chuỗi cung ứng, mọi bộ phận trong doanh nghiệp đang sử dụng AI để tự động hóa các tác vụ thông thường, cải thiện mức độ tương tác của khách hàng bên trong và bên ngoài, tối ưu hóa quy trình kinh doanh và xác định các cơ hội kinh doanh mới. Các doanh nghiệp đang sử dụng các công nghệ AI như học máy, xử lý ngôn ngữ tự nhiên và thị giác máy tính để thúc đẩy đổi mới, tăng hiệu quả và giảm chi phí.
Tuy nhiên, hầu hết các sáng kiến nghiên cứu về AI không bao giờ được đưa vào sản xuất. Một lý do là các nhà nghiên cứu tiêu thụ sức mạnh tính toán, thường là sử dụng GPU, để xây dựng và huấn luyện các thuật toán học máy (ML) và học sâu (DL) cũng như đưa các sáng kiến AI vào sản xuất. Các tài nguyên GPU này được phân bổ cho các nhà nghiên cứu theo cách tĩnh. Các tài nguyên điện toán đắt tiền được phân bổ cho một nhà nghiên cứu thường không hoạt động – ngay cả khi một nhà nghiên cứu khác đang chờ phân bổ GPU. Đưa các mô hình vào sản xuất rất chậm do quá trình phân bổ điện toán tĩnh hạn chế tiến độ.
Việc phát triển các mô hình AI thường yêu cầu tài nguyên tính toán đáng kể, với GPU cao cấp được sử dụng cho mạng lưới thần kinh. Tuy nhiên, các máy chủ này có thể tốn kém về không gian giá đỡ, nguồn điện và yêu cầu làm mát. Do tính chất tĩnh và cứng nhắc của phân bổ GPU, những tài nguyên đắt tiền này thường không được sử dụng đúng mức, dẫn đến lãng phí sức mạnh tính toán có giá trị và tạo gánh nặng cho ngân sách CNTT. Việc phân bổ tài nguyên GPU có thể gặp vấn đề vì bản chất của khối lượng công việc AI có thể không đoán trước được, với các yêu cầu tính toán khác nhau tùy thuộc vào dữ liệu được phân tích và độ phức tạp của mô hình AI đang được sử dụng. Do đó, việc phân bổ tài nguyên GPU thường không được tối ưu hóa, với một số GPU bị sử dụng quá mức trong khi những GPU khác không hoạt động. Việc sử dụng tài nguyên không hiệu quả này có thể dẫn đến chi phí đáng kể cho các tổ chức,
Việc không thể sử dụng tài nguyên một cách hiệu quả làm chậm quá trình thử nghiệm và là một trong những lý do chính khiến hầu hết các doanh nghiệp không thấy được lợi tức đầu tư (ROI) từ các sáng kiến AI. Từ góc độ chứng minh khái niệm, cơ sở hạ tầng máy chủ với GPU có thể cung cấp hiệu suất cần thiết để khám phá thông tin chi tiết về doanh nghiệp; tuy nhiên, nó vẫn không đạt được sản xuất trong nhiều trường hợp vì giải pháp không mở rộng quy mô. Do tài nguyên GPU được phân bổ tĩnh nên khi một nhà khoa học dữ liệu bắt đầu một khối lượng công việc, những người khác có thể phải xếp hàng đợi cho đến khi tác vụ hoàn thành. Thông thường, các doanh nghiệp chỉ sử dụng trung bình từ 10 phần trăm đến khoảng 20 phần trăm tài nguyên GPU của họ tại một thời điểm.
Sự hợp tác giữa Dell Technologies và Run:ai mang đến giải pháp cho các doanh nghiệp phân bổ tài nguyên GPU một cách linh hoạt cho khối lượng công việc cụ thể để mang lại kết quả kinh doanh tốt hơn và nhanh hơn, đồng thời cải thiện ROI trên các dự án AI bằng cách tổng hợp và tối ưu hóa tài nguyên GPU. Phần mềm Run:ai Atlas trừu tượng hóa khối lượng công việc AI từ sức mạnh tính toán của GPU—tạo ra các “nhóm ảo” trong đó các tài nguyên được phân bổ động và tự động—để doanh nghiệp có toàn quyền sử dụng GPU. Sự phân bổ này giúp các nhà khoa học dữ liệu và CNTT quản lý cơ sở hạ tầng điện toán một cách hiệu quả ở quy mô và trong phạm vi ngân sách, đồng thời nâng cao khả năng hiển thị của việc lập lịch trình công việc và sử dụng tài nguyên cho cả nhóm khoa học dữ liệu và CNTT.
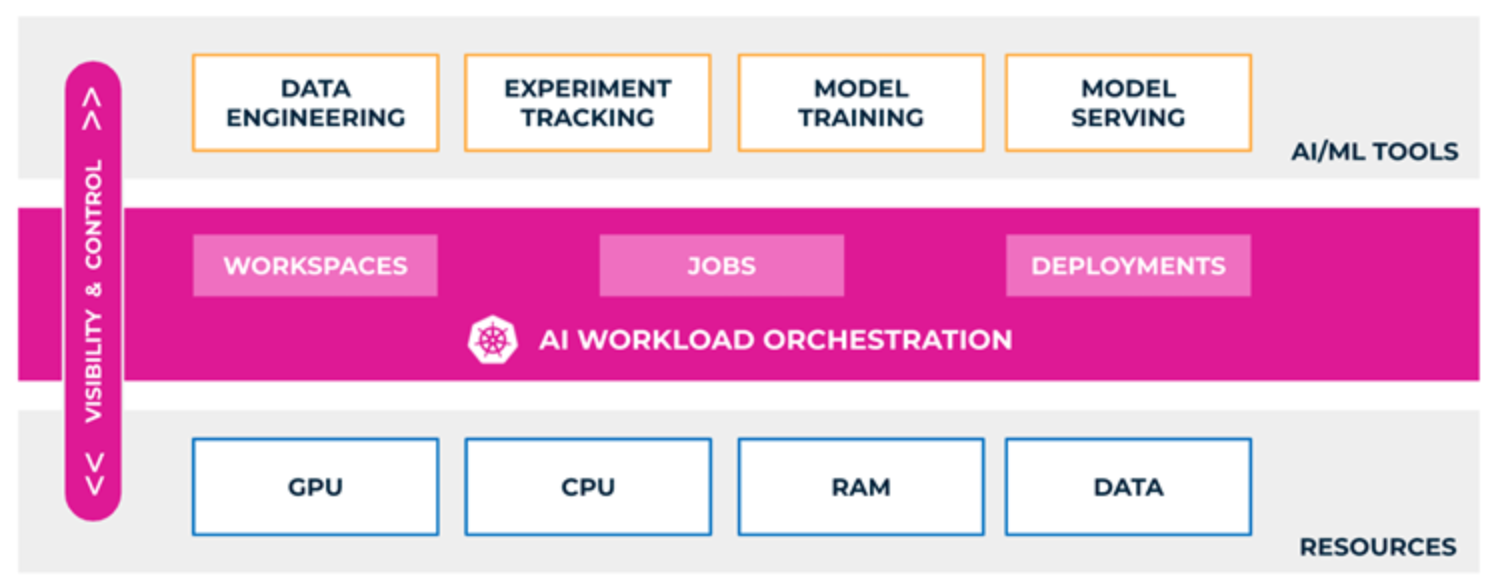
Hình 1. Phối hợp GPU sử dụng nền tảng Run:ai Atlas
Các tính năng chính của Run:ai Atlas bao gồm:
- Một ngăn kính ─Quản lý tài nguyên, sử dụng, tình trạng và hiệu suất tập trung và đa bên được cung cấp trên tất cả các khía cạnh của đường ống AI bất kể khối lượng công việc được chạy ở đâu.
- Mức tiêu thụ tài nguyên GPU dựa trên chính sách ─Việc quản lý và tự động hóa đơn giản được cung cấp bằng cách xác định trước các chính sách giữa các dự án, người dùng và phòng ban để điều chỉnh mức tiêu thụ tài nguyên theo các ưu tiên kinh doanh.
- Giám sát và Báo cáo ─Nền tảng quản lý chế độ xem lịch sử và thời gian thực của tất cả các tài nguyên. Việc giám sát và báo cáo này bao gồm các công việc, quá trình triển khai, dự án, người dùng, GPU, cụm, v.v.
- Phối hợp dựa trên Kubernetes ─Hỗ trợ tích hợp sẵn cho tất cả các bản phân phối Kubernetes chính cho phép tích hợp dễ dàng trong một hệ sinh thái hiện có. Bộ lập lịch Kubernetes nhận biết khối lượng công việc đưa ra các quyết định thông minh và tự động dựa trên loại khối lượng công việc AI chạy trên nền tảng. Sự phối hợp này cung cấp khả năng tích hợp sâu vào các trình tăng tốc AI và cho phép chia sẻ hiệu quả cũng như cấu hình tự động các tài nguyên này trên nhiều khối lượng công việc. Được xây dựng xung quanh Kubernetes, nền tảng phần mềm Atlas mở rộng quy mô và thích ứng với mọi loại môi trường đám mây (riêng tư, công khai và kết hợp).
- GPU phân đoạn ─Khả năng trừu tượng hóa GPU của Run:ai Atlas cho phép chia sẻ tài nguyên GPU mà không bị tràn bộ nhớ hoặc xung đột xử lý. Bằng cách sử dụng các GPU logic được ảo hóa, với bộ nhớ và không gian tính toán riêng, các bộ chứa có thể sử dụng và truy cập các phần GPU như thể chúng là các bộ xử lý độc lập. Giải pháp minh bạch, đơn giản và di động; nó không yêu cầu thay đổi mã hoặc thay đổi đối với chính các vùng chứa.
- Hỗ trợ đào tạo đa GPU và phân tán ─Đào tạo phân tán là khả năng phân chia quá trình đào tạo một mô hình giữa nhiều bộ xử lý. Đào tạo đa GPU là phân bổ nhiều hơn một GPU cho khối lượng công việc chạy trên một vùng chứa. Run:ai Atlas cung cấp khả năng chạy, quản lý và xem khối lượng công việc đào tạo phân tán và đa GPU.
- Chứng nhận để chạy Bộ phần mềm NVIDIA AI Enterprise ─NVIDIA AI Enterprise tăng tốc quy trình khoa học dữ liệu và hợp lý hóa quá trình phát triển và triển khai AI sản xuất (bao gồm AI tổng quát), thị giác máy tính, AI lời nói, v.v. Với hơn 50 khung, mô hình được đào tạo trước và công cụ phát triển, NVIDIA AI Enterprise được thiết kế để tăng tốc các doanh nghiệp lên vị trí dẫn đầu về AI đồng thời đơn giản hóa AI để mọi doanh nghiệp đều có thể tiếp cận AI. Nền tảng Run:ai Atlas được chứng nhận để chạy NVIDIA AI Enterprise.
- Hỗ trợ cho vòng đời của một mô hình AI ─Vòng đời của một mô hình AI là lặp đi lặp lại. Mô hình này liên tục được tinh chỉnh và cải tiến theo thời gian để đáp ứng nhu cầu kinh doanh luôn thay đổi và đảm bảo tính chính xác và hiệu quả. Run:ai Atlas hỗ trợ các yêu cầu GPU đa dạng của từng giai đoạn trong vòng đời phát triển mô hình AI:
- Xây dựng ─Chạy nhiều thử nghiệm hơn thông qua điều phối khối lượng công việc hiệu quả. Tương tác dễ dàng đến từ hỗ trợ tích hợp cho Jupyter Notebook và các khuôn khổ phổ biến khác.
- Đào tạo ─Dễ dàng mở rộng quy mô khối lượng công việc đào tạo và đơn giản hóa mọi loại hình đào tạo, từ đào tạo đơn giản đến đào tạo đa nút phân tán.
- Suy luận ─Đưa các mô hình vào sản xuất và chạy suy luận ở bất kỳ đâu từ tại chỗ đến vùng biên cho đến đám mây ở mọi quy mô. Đưa các mô hình AI của bạn vào sản xuất bằng cách sử dụng các công cụ tích hợp của chúng tôi và tích hợp với tất cả các máy chủ suy luận chính, bao gồm cả Máy chủ suy luận Triton của NVIDIA.
- Hỗ trợ cho nhiều personas:
- Nhà nghiên cứu ─Tương tác với nền tảng bằng cách sử dụng giao diện người dùng, CLI, API hoặc YAML trực quan của chúng tôi mà không cần suy nghĩ về các tài nguyên cơ bản. Bắt đầu thử nghiệm dễ dàng chỉ bằng một lần bấm nút hoặc tạo ra hàng trăm công việc đào tạo. Run:ai Atlas cung cấp một cách đơn giản để các nhà nghiên cứu tương tác với nền tảng bằng cách sử dụng tích hợp sẵn cho các công cụ IDE như Jupyter Notebook và PyCharm. Bắt đầu thử nghiệm một cách dễ dàng và chạy hàng trăm công việc đào tạo mà không phải lo lắng về cơ sở hạ tầng cơ bản.
- Kỹ sư MLOps ─Vận hành các mô hình AI ở mọi nơi và ở mọi quy mô bằng cách sử dụng bộ công cụ ML tích hợp hoặc bất kỳ công cụ hiện có nào của bạn như Kubeflow và MLflow. Nhận thông tin chi tiết lịch sử và theo thời gian thực về cách các mô hình đang hoạt động và lượng tài nguyên mà chúng đang tiêu thụ.
- Quản trị viên CNTT ─Cho phép sử dụng tài nguyên điện toán giống như đám mây một cách an toàn trên mọi cơ sở hạ tầng, tại chỗ, biên hoặc đám mây. Có toàn quyền kiểm soát và khả năng hiển thị tài nguyên trên các cụm, vị trí hoặc nhóm khác nhau trong tổ chức của bạn.
- Tích hợp và hỗ trợ hệ sinh thái ─Run:ai Atlas tích hợp với các bản phân phối chính của Kubernetes bao gồm OpenShift EKS, Symcloud Platform, Kubernetes ngược dòng, cùng với tất cả các công cụ MLOps phổ biến và khung khoa học dữ liệu. Nền tảng điều phối và quản lý khối lượng công việc AI trên các tài nguyên tại chỗ và điện toán đám mây, chẳng hạn như:
- PyTorch
- Kubeflow
- Mũ đỏ OpenShift
- Trung tâm Jupyter
- MLflow
- Trọng lượng và thành kiến
- cá đuối
- Nhiều tùy chọn triển khai ─Có hai tùy chọn cài đặt cho nền tảng Run:ai Atlas:
- Cổ điển (SaaS) ─Run:ai Atlas được cài đặt trên cụm GPU khoa học dữ liệu của khách hàng. Cụm kết nối với mặt phẳng điều khiển Run:ai Atlas trên đám mây ( https://.run.ai ). Với cài đặt này, cụm yêu cầu kết nối ra bên ngoài với đám mây Run:ai Atlas.
- Tự lưu trữ ─Mặt phẳng điều khiển Run:ai Atlas được cài đặt trong trung tâm dữ liệu của khách hàng.
Kiến trúc tham khảo
Bản tóm tắt
Dell Technologies đã hợp tác chặt chẽ với Run:ai để cung cấp khả năng lập lịch trình và điều phối GPU thông qua một giải pháp được thiết kế và xác nhận chung nhằm giúp các doanh nghiệp tăng cường sử dụng cơ sở hạ tầng AI được tăng tốc GPU của họ.
Giải pháp Run:ai Atlas có thể áp dụng cho tất cả các máy chủ Dell PowerEdge được tăng tốc GPU, bao gồm các máy chủ PowerEdge R7625, R7525, R760, R760xa, XE8640, XE9640 và XE9680. Do đó, Run:ai Atlas cũng có thể áp dụng cho các giải pháp hỗ trợ GPU của Dell cho AI và phân tích dữ liệu, bao gồm AI Sáng tạo trong Doanh nghiệp và Thiết kế được Xác thực cho Analytics—Data Lakehouse.
Trong thiết kế này, chúng tôi đã xác thực Run:ai Atlas trên Nền tảng Symcloud. Nền tảng Symcloud được xác thực như một phần của Thiết kế được xác thực cho Analytics—Data Lakehouse của chúng tôi .
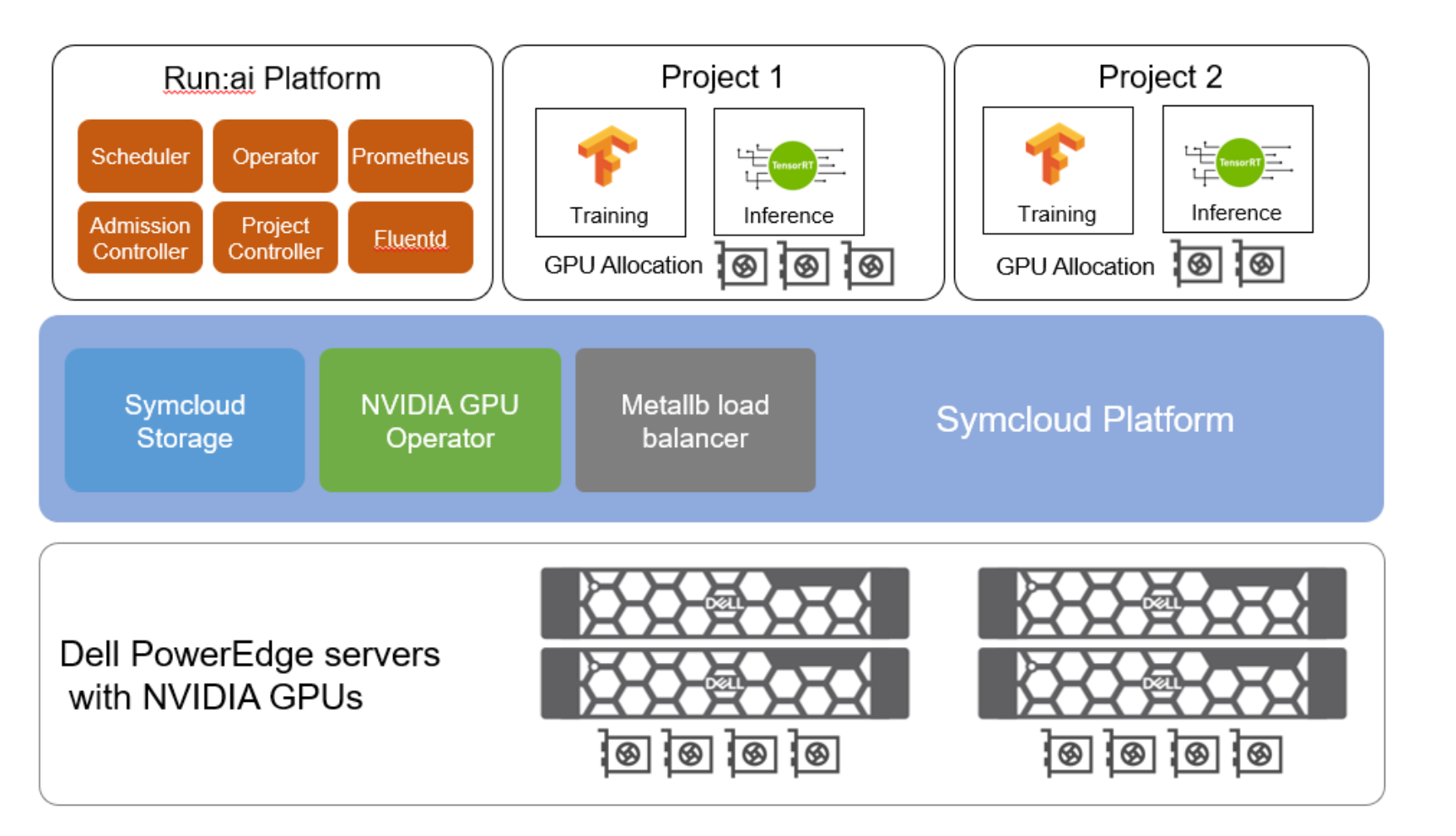
Hình 2. Thiết kế đã được xác thực cho AI – Run:ai Atlas
Kiến trúc tham chiếu kết hợp các thành phần sau:
- Nền tảng Symcloud được sử dụng cho lớp Kubernetes. Nó là một phần của Thiết kế đã được Xác thực của Dell dành cho Analytics—Data Lakehouse.
- Nền tảng Run:ai Atlas được sử dụng để điều phối và lên lịch GPU.
- Máy chủ PowerEdge cung cấp tài nguyên điện toán, bao gồm cả GPU cho các dự án AI.
- Symcloud Storage cung cấp Lớp lưu trữ Kubernetes bằng cách khám phá các đĩa được gắn vào máy chủ PowerEdge. Run:ai Atlas cài đặt tự lưu trữ yêu cầu khối lượng liên tục có thể sử dụng Lớp lưu trữ Kubernetes này.
- Các thành phần Dell PowerSwitch được sử dụng để kết nối mạng.
- Toán tử GPU NVIDIA được sử dụng để quản lý tài nguyên GPU NVIDIA trong cụm Kubernetes.
- MetalLB là bộ cân bằng tải cung cấp bản cài đặt tự lưu trữ Run:ai Atlas với địa chỉ IP bên ngoài. MetalLB được đưa vào như một phần của Nền tảng Symcloud
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...