
Tin tức
Trong thế giới dựa trên dữ liệu, những thay đổi đổi mới đang buộc phải có một mô hình mới
Trong hai thập kỷ qua, tôi rất thích làm việc tại Dell Technologies, tập trung vào những ý tưởng mang tính toàn cảnh của khách hàng. Không chỉ tập trung vào những thay đổi về phần cứng mà còn tập trung vào giải pháp tổng thể bao gồm phần cứng, phần mềm và dịch vụ nhằm đạt được mục tiêu kinh doanh bằng cách giải quyết các mục tiêu, vấn đề và nhu cầu của khách hàng. Tôi cũng đã hợp tác với khách hàng của mình trên hành trình chuyển đổi của họ. Các khái niệm về chuyển đổi kỹ thuật số và chuyển đổi CNTT đã trở thành chủ đề phổ biến và việc biến những ý tưởng này thành hiện thực chính là nơi mà cao su gặp đường.
Giờ đây, khi tôi tương tác với khách hàng và đối tác về các giải pháp của Microsoft, nhận thức ngày càng tăng về ý tưởng về “dữ liệu” cũng như cách truy cập và tận dụng dữ liệu đã trở nên rõ ràng. Một sự thay đổi cơ bản xung quanh dữ liệu đã xảy ra.
Chúng ta hiện đang sống trong kỷ nguyên mới của quản lý dữ liệu, nhưng nhiều người trong chúng ta không nhận thức được sự thay đổi này đang phát triển. Điều này đã đến với chúng tôi mà không hề có sự phô trương nào mà bạn có thể thấy khi ra mắt công nghệ mới. Khi bạn lùi lại một bước và xem xét toàn bộ những thay đổi này, bạn sẽ thấy những thay đổi này không chỉ là những cập nhật riêng lẻ mà thay vào đó đang khuếch đại lợi ích của chúng với nhau. Đây là một sự chuyển đổi cơ bản trong ngành, tương tự như khi ảo hóa lần đầu tiên được áp dụng cách đây 15 năm.
Đối với nhiều người, sự thay đổi này bắt đầu trở nên rõ ràng khi kết thúc hỗ trợ cho SQL Server 2008 vào đầu năm nay (cùng với việc hỗ trợ cho tất cả các phiên bản trước của sản phẩm). Thời hạn này, cùng với cơ sở cài đặt lớn vẫn tồn tại trên nền tảng này, đang giúp ích cho cuộc trò chuyện nhưng nó không chỉ là sự thay thế cái cũ bằng cái mới trong một sự hoán đổi từng điểm một. Những cánh cửa mở ra trong kỷ nguyên mới này buộc phải có một cái nhìn và cách tiếp cận hoàn toàn khác. Chúng ta không còn cần phải có một cuộc trò chuyện về SQL, Oracle, SAP hoặc Hadoop nữa – thay vào đó nó trở thành một quan điểm “dữ liệu” tổng thể.
Trong thế giới kết hợp/nhiều đám mây của chúng ta, không chỉ có một câu trả lời duy nhất cho việc quản lý dữ liệu. Bất kể loại dữ liệu hay nơi nó cư trú, tất cả các ngôn ngữ dữ liệu và phương pháp kiểm soát đa dạng, từ “dữ liệu” có thể bao hàm rất nhiều thứ.
Các công nghệ mới nổi bao gồm IoT, 5G, AI và ML đang tạo ra lượng dữ liệu lớn hơn và đa dạng hơn. Cách chúng tôi truy cập dữ liệu đó và rút ra thông tin chuyên sâu từ dữ liệu đó trở nên quan trọng, nhưng chúng tôi đã bị giới hạn bởi con người, quy trình và công nghệ.
Mọi người đã bị mắc kẹt trong lối mòn, “Tôi muốn mọi chuyện diễn ra theo cách này bởi vì nó đã luôn như vậy”. Do đó, việc thay thế các kiến trúc lỗi thời/hết hạn trở thành một câu chuyện hoán đổi, một câu chuyện kiểm tra lại và những hiệu quả mới hoàn toàn bị bỏ sót. Các quy trình trong tổ chức trở nên cứng nhắc với cùng một suy nghĩ đó và tôi dám nói là chính trị, nơi việc truy cập vào dữ liệu đó bị hạn chế. Công nghệ bị ảnh hưởng bởi cả con người và quy trình vì “cách cũ cũng đủ tốt phải không?”
Giá trị/tầm quan trọng của “dữ liệu” thực sự phản ánh thông tin chi tiết mà bạn thu được từ dữ liệu đó. Có một loạt các số 1 và 0 trên ổ cứng là điều tốt nhưng những gì bạn rút ra được từ dữ liệu đó là cực kỳ quan trọng. Những cuộc trò chuyện của tôi với khách hàng không quá nhiều, “Dữ liệu của tôi ở đâu và nó được lưu trữ như thế nào?” Cuộc trò chuyện phổ biến hơn là “Tôi cần thu thập các phân tích kinh doanh từ dữ liệu độc quyền của mình để có thể tác động đến khách hàng của mình theo cách mà tôi chưa từng làm trước đây”.
Để đội chiếc mũ Stephen Covey của tôi lên, chúng ta đang ở trong một sự thay đổi về mô hình. Những gì đang diễn ra có tác động cực kỳ lớn đến cách khách hàng xem và xử lý dữ liệu. Có ba lĩnh vực chính mà chúng ta sẽ xem xét với mô hình mới hôm nay và chúng ta sẽ bắt đầu với trọng lực dữ liệu.
Trọng lực dữ liệu
 Trọng lực dữ liệu là ý tưởng rằng dữ liệu có trọng lượng. Bất cứ nơi nào dữ liệu được tạo ra, nó có xu hướng tồn tại. Các kho lưu trữ dữ liệu ngày càng lớn đến mức việc di chuyển dữ liệu xung quanh trở nên tốn kém, bị hạn chế về thời gian và ảnh hưởng đến hiệu suất cơ sở dữ liệu. Ngược lại, điều này dẫn đến các kho dữ liệu theo vị trí và loại. Việc lập phiên bản và thiếu việc nâng cấp/di chuyển/hợp nhất cơ sở dữ liệu cũng gây ra những thách thức riêng lẻ này.
Trọng lực dữ liệu là ý tưởng rằng dữ liệu có trọng lượng. Bất cứ nơi nào dữ liệu được tạo ra, nó có xu hướng tồn tại. Các kho lưu trữ dữ liệu ngày càng lớn đến mức việc di chuyển dữ liệu xung quanh trở nên tốn kém, bị hạn chế về thời gian và ảnh hưởng đến hiệu suất cơ sở dữ liệu. Ngược lại, điều này dẫn đến các kho dữ liệu theo vị trí và loại. Việc lập phiên bản và thiếu việc nâng cấp/di chuyển/hợp nhất cơ sở dữ liệu cũng gây ra những thách thức riêng lẻ này.
Giống như trọng lực vật lý, chúng tôi hiểu rằng khối lượng của dữ liệu khuyến khích các ứng dụng và phân tích quay quanh kho lưu trữ dữ liệu nơi nó cư trú. Sau đó, sự phụ thuộc của ứng dụng vào phiên bản ngôn ngữ của dữ liệu sẽ càng củng cố thêm yêu cầu về silo. Chúng tôi đã chứng kiến sự phát triển nhanh chóng của các thiết bị lõi và biên thông minh, cũng như đưa các ứng dụng đến nơi chứa dữ liệu – tại địa điểm của khách hàng.
Không thể truy cập dễ dàng các kho dữ liệu dựa trên ngôn ngữ, phiên bản và vị trí từ một giao diện chung. Nếu tôi là người dùng SQL, làm cách nào để có được dữ liệu Oracle mà tôi cần? Tôi không thể tập hợp tất cả dữ liệu của mình lại thành một tập dữ liệu chung khổng lồ – nó quá lớn. Chúng tôi thấy những silo này ở hầu hết mọi môi trường khách hàng.
Ảo hóa dữ liệu
Đây là nơi ảo hóa dữ liệu đi vào câu chuyện. Xin lưu ý đây không phải là máy ảo (một sự nhầm lẫn thường gặp khi đặt tên). Thay vào đó hãy suy nghĩ về việc dân chủ hóa dữ liệu: khả năng cho phép tất cả mọi người truy cập vào tất cả dữ liệu – tất nhiên là trong phạm vi lý do. Ảo hóa dữ liệu cho phép bạn truy cập vào dữ liệu nơi dữ liệu được lưu trữ mà không có sự kiện ETL lớn. Bạn có thể xem và kiểm soát dữ liệu bất kể ngôn ngữ, phiên bản hoặc vị trí. Dữ liệu vẫn giữ nguyên nhưng bạn có quyền truy cập nguồn theo thời gian thực vào dữ liệu này. Bạn có thể truy cập dữ liệu từ các nguồn từ xa hoặc đa dạng và thực hiện các hành động trên dữ liệu đó theo một quan điểm chung.
Ảo hóa dữ liệu cho phép truy cập vào các silo mà trước đây rất cứng nhắc, cản trở khả năng sử dụng dữ liệu đó một cách hiệu quả. Từ quan điểm không phải của SQL Server, việc có dữ liệu phi cấu trúc hoặc dữ liệu có cấu trúc ở định dạng khác (như Oracle), yêu cầu bạn phải thuê một người chuyên môn có bộ kỹ năng cụ thể để truy cập dữ liệu đó. Với ảo hóa dữ liệu, điều đó không còn là rào cản khi các bức tường silo này được giảm bớt. Ảo hóa dữ liệu trở thành dân chủ hóa dữ liệu, nghĩa là tất cả mọi người (có quyền phù hợp) đều có thể truy cập và thực hiện mọi việc với dữ liệu đó.
Theo quan điểm của Microsoft, công nghệ đó đã trở thành hiện thực với Polybase. Polybase with SQL Server cho phép truy cập bằng T-SQL, ngôn ngữ cơ sở dữ liệu được sử dụng phổ biến nhất. Tôi đã bắt đầu sử dụng tài nguyên này với Hệ thống nền tảng phân tích (APS) từ nhiều năm trước. Sau khi Microsoft đưa công cụ này vào SQL Server vào năm 2016 và cập nhật rất nhiều chức năng của nó trong SQL Server 2019, giờ đây chúng tôi có thể sử dụng Hadoop, Oracle và sử dụng các bộ điều phối như Spark để truy cập tất cả các nguồn dữ liệu khác nhau này. Để hình dung điều này, hãy nghĩ về Polybase với SQL Server 2019 như một trình bao bọc xung quanh các kho dữ liệu đa dạng này. Bây giờ bạn có thể truy cập tất cả các nguồn dữ liệu khác nhau này trong một giao diện chung: T-SQL bằng Polybase.
Giải pháp toàn diện
Nguyên lý cuối cùng của sự thay đổi cơ bản này là sự ra đời của công nghệ container hóa. Công nghệ hỗ trợ này cho phép trừu tượng hóa ngoài ảo hóa và chạy ở mọi nơi. Dữ liệu trở nên nhanh nhẹn và bạn có thể di chuyển nó khi cần thiết.
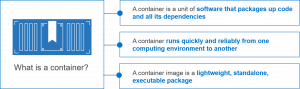
Thật ngạc nhiên khi các container đã trở nên phổ biến như thế nào. Nó không còn là một thử nghiệm khoa học nữa mà đang nhanh chóng trở thành một điều bình thường mới. Trước đây, nhiều khách hàng có quan niệm về xe nâng rằng khi có công nghệ mới ra đời thì cần phải nâng và thay thế. Tôi từng nghe nói: “Việc tôi làm hôm nay không còn tốt nữa nên tôi phải thay thế bằng sản phẩm mới của bạn, sẽ rất đau đớn”.
Tôi đang sử dụng cụm từ cho phép việc chứa trong vùng chứa “tất cả mọi thứ”. Quá trình container hóa đã được rất nhiều kiến trúc áp dụng nên việc nói về những nơi bạn không thể làm sẽ dễ dàng hơn so với những nơi bạn có thể. SAN truyền thống, đám mây hội tụ, siêu hội tụ, lai — bạn có thể đặt nó ở hầu hết mọi nơi. Ở đây không chỉ có một con đường đúng đắn – hãy làm những gì có ý nghĩa với bạn. Nó trở thành một giải pháp toàn diện.
Có nhiều cách để giải quyết nhu cầu kinh doanh mà khách hàng có ngay cả khi điều đó tận dụng các thiết kế hiện có mà họ đã sử dụng trong nhiều năm. Dell Technologies đã công bố thông tin chi tiết về một số kiến trúc hỗ trợ SQL Server và vừa mới xuất bản bài báo đầu tiên trong số nhiều bài báo về SQL Server trong các vùng chứa .
Câu trả lời là bạn có thể làm tất cả những điều này với tất cả các kiến trúc này. Nhân tiện, điều này không dành riêng cho Microsoft và SQL Server. Chúng tôi thấy các kiến trúc tương tự đang được tạo ra trong các cơ sở dữ liệu và định dạng công nghệ khác.
Ba nguyên lý này đều tự hỗ trợ cho mô hình mới. Trọng lực dữ liệu được hỗ trợ bởi ảo hóa và chứa dữ liệu. Ảo hóa dữ liệu cho phép các silo khi cần thiết (trọng lực) và được kích hoạt bằng cách chứa. Containerization cho phép truy cập vào silo (trình bao bọc) và là cơ chế kích hoạt ảo hóa dữ liệu.
Từ quan điểm của Dell Technologies, chúng tôi đang tích cực áp dụng những nguyên lý này. Các công nghệ hỗ trợ của chúng tôi nhằm hỗ trợ mô hình này được trình bày theo ba điểm riêng biệt – tăng tốc, bảo vệ và tái sử dụng. Chúng tôi sẽ xem xét những điểm này trong một blog riêng.
Còn nhiều điều nữa sẽ xảy ra khi chúng ta tiếp tục hành trình bước vào kỷ nguyên mới của quản lý dữ liệu. Dell Technologies đã đầu tư sâu vào các nguồn lực xung quanh chủ đề này với một số ấn phẩm và thiết kế tham khảo gần đây đề cập đến sự thay đổi mô hình này. Sự lãnh đạo của chúng tôi về chủ đề này là kết quả của mối quan hệ hơn 30 năm của chúng tôi với Microsoft và câu chuyện tiếp tục “cùng nhau tốt đẹp hơn” của chúng tôi.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...