
Tin tức
Việc tích hợp GPU có quan trọng đối với Phân tích dự đoán không?
GPU đang nhận được sự chú ý rộng rãi trong không gian Phân tích dự đoán (PredAn). Điều này là do khả năng thực hiện tính toán song song trên khối lượng dữ liệu lớn. GPU tận dụng các mô hình phức tạp được tích hợp chặt chẽ với mô phỏng cần thiết để thực hiện tổng hợp điều khiển nhằm đáp ứng thời gian thực trong các giải pháp Công nghiệp 4.0 (I4). Hãy xem xét trường hợp sử dụng bảo trì dự đoán, trong đó dữ liệu đo từ xa từ các máy chủ trong trung tâm dữ liệu được ghi lại để phân tích lỗi trong cụm phân tích và các chuỗi điều khiển được tạo để tránh thời gian ngừng hoạt động. Rõ ràng, để đi đúng hướng, máy cần chiếu dữ liệu hiện tại vào tương lai và mô phỏng các phân vùng lỗi trong danh sách có thể giám sát để thương lượng cách khắc phục, tất cả đều diễn ra trong một khoảng thời gian eo hẹp. Tuy nhiên, dự đoán và mô phỏng vốn đã chậm, đặc biệt khi việc này cần được thực hiện trên nhiều phân vùng lỗi trên nhiều máy chủ.
Chúng tôi lập luận rằng có hai điều có thể giúp ích:
- Dự đoán tuyến tính hóa với bộ lọc Koopman
- Tận dụng các mô hình tổng quát để tổng hợp điều khiển trong không gian mô phỏng
Chúng tôi sử dụng bộ lọc Koopman để chiếu dữ liệu vào không gian cơ sở tiềm ẩn mỏng hơn cho Giảm kích thước (DR) và nhúng phép chuyển đổi này vào bên trong bộ mã hóa tự động. Sau đó, một đầu dò để chuyển đổi các phần vectơ riêng thành Chuỗi giá trị riêng (EVS) tương quan với xác suất sống sót, sau đó có thể được chuyển đổi thành ước tính Time2Failure (T2F). Sau đó, phát hiện lỗi này có thể được gắn thẻ với tham chiếu đến tập lệnh tự động sửa lỗi được hiệu chỉnh trước bắt nguồn từ Dấu vân tay bất thường (AF) trong khi mô phỏng phân vùng lỗi dự kiến. Các mô hình tạo (GAN) cho phép tối ưu hóa hiệu suất và dấu chân, dẫn đến suy luận nhanh hơn. Theo nghĩa đó, điều này cải thiện thông lượng suy luận. Chúng tôi đào tạo các mô hình tổng quát cho Dữ liệu, DR, T2F và AF và sử dụng chúng để suy luận nhanh. Hình 1(a) hiển thị luồng suy luận, 1(b) hiển thị tuyến tính hóa Koopman và 1(c) hiển thị dấu chân GAN cơ bản.
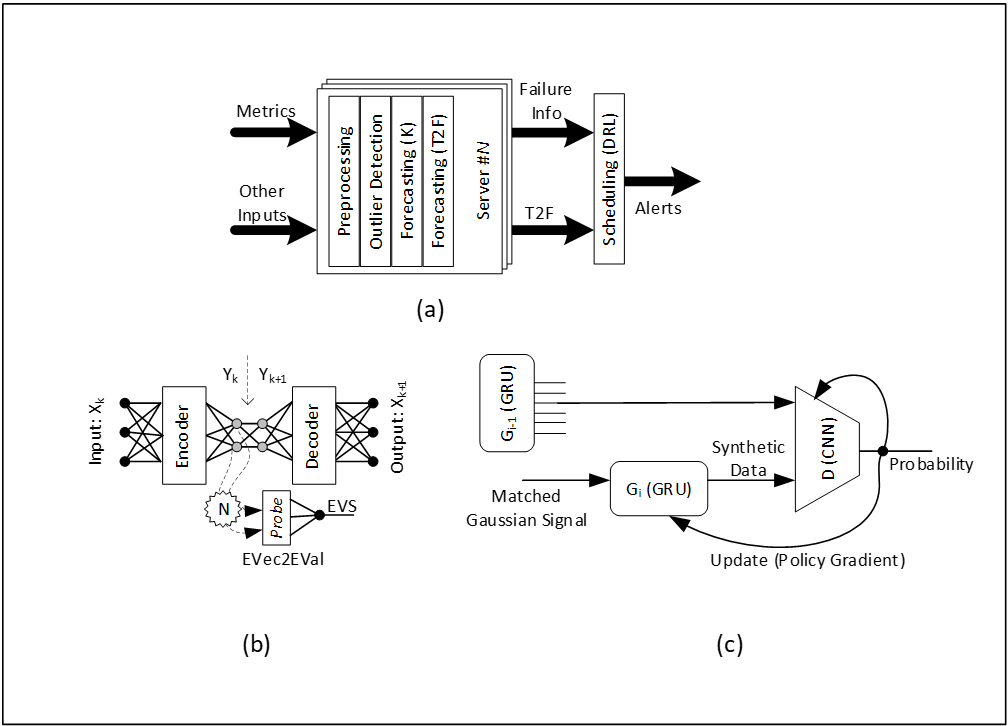
Hình 1. Luồng suy luận, tuyến tính hóa Koopman và dấu chân GAN cơ bản
Trong hình 1(a), các ước tính T2F cho tất cả lỗi trên tất cả các máy chủ được bộ lập lịch xử lý bằng cách sử dụng DRL trong giai đoạn suy luận. Trong hình 1(b), mỗi nhóm lỗi, thứ nguyên vectơ riêng được tìm kiếm trong khung bộ mã hóa tự động bằng cách thay đổi kích thước độ sâu của bộ mã hóa để biết rõ lỗi trong EVS. Trong hình 1(b), G 2 được suy ra từ G 1 và G 1 từ G 0 cho mỗi nhóm lỗi. Tổng hợp mô hình tổng quát cho phép ánh xạ tính toán phức tạp sang các tính toán tương tự có hiệu suất cao, tiêu tốn ít dấu chân và có thể được tận dụng tại thời điểm suy luận.
Đối số GPU
GPU thường được sử dụng cho cả đào tạo và hội thảo. Trong thử nghiệm bảo trì dự đoán, chúng tôi truyền dữ liệu đo từ xa trực tiếp từ iDRAC đến cụm phân tích được xây dựng bằng các dịch vụ Splunk như các công cụ phát trực tuyến, lập chỉ mục, tìm kiếm, phân tầng và khoa học dữ liệu trên nền tảng Robin.io k8s. Cụm này có quyền truy cập vào tài nguyên GPU Nvidia cho cả hoạt động đào tạo và hội thảo. Sơ đồ trong hình 2(a) cho thấy rằng việc sử dụng quyền truy cập không đồng bộ vào suy luận GPU đa phiên bản (MIG) mang lại hiệu suất tăng lên so với phương án chặn, được đo bằng ước tính đồng hồ treo tường. Bộ lập lịch GPU quản lý khối lượng công việc T2F không đồng bộ tốt hơn và việc chặn cuộc gọi sẽ yêu cầu cấu hình lại thời gian chờ trong quá trình sản xuất. Biểu đồ trong hình 2(b) cho thấy rằng hiệu suất suy luận của các mô hình tổng quát được cải thiện 15% (đối với hơn 12 tập) khi chọn tối ưu hóa có chọn lọc (DRL-on-CPU và T2F-Tính toán trên GPU). Hướng đi của xu hướng này có ý nghĩa vì DRL-in-GPU yêu cầu chuyển bộ nhớ sang bộ nhớ thường xuyên và do đó là ứng cử viên lý tưởng cho việc ghim CPU, trong khi ước tính T2F là các phép tính dày đặc nhưng tương đối ít thường xuyên hơn, hoạt động tốt khi ánh xạ tới GPU bằng MIG đã bật. Khi khoảng cách giữa các ô ngày càng mở rộng, điều này cho thấy rằng tính toán chỉ của CPU không thể theo kịp với việc chồng dữ liệu, do đó các phần đầu vào cần được rút ngắn. Biểu đồ trong hình 2(c) cho thấy rằng ít đợt hơn (giả sử kích thước tập dữ liệu cố định) đã rút ngắn thời gian cần thiết để đạt được độ chính xác huấn luyện mong muốn trong GAN. Tuy nhiên, kích thước lô lớn hơn đòi hỏi nhiều bộ nhớ GPU hơn, đồng nghĩa với việc vô hiệu hóa MIG để cải thiện thông lượng và mức tiêu thụ năng lượng. Dựa trên dữ liệu này, chúng tôi lập luận rằng việc dành riêng GPU cho việc đào tạo (nhân đơn) thay vì chuyển đổi nhân (giữa đào tạo và suy luận) sẽ cải thiện thông lượng. Điều này cho chúng ta biết rằng GPU đào tạo (không hỗ trợ MIG) và GPU suy luận (có hỗ trợ MIG) phải được tách biệt trong I4 để có hiệu suất và sử dụng tối ưu. Dựa trên các lựa chọn cấu hình hiện tại, điều này chỉ ra tùy chọn GPU Nvidia A30 kép thay vì một GPU Nvidia A100 duy nhất được gắn vào nút nhân viên máy chủ Power Edge. Sơ đồ trong hình 2 (d) cho thấy các mô hình tạo một lớp cải thiện hiệu suất suy luận và mở rộng quy mô một cách dễ dự đoán hơn. Kỳ vọng là đa lớp sẽ hoạt động tốt hơn. Biểu đồ cho thấy sự cải thiện hiệu suất khi kích thước phần tăng lên, mặc dù cần nhiều công việc hơn để hiểu tác động của nhiều lớp.
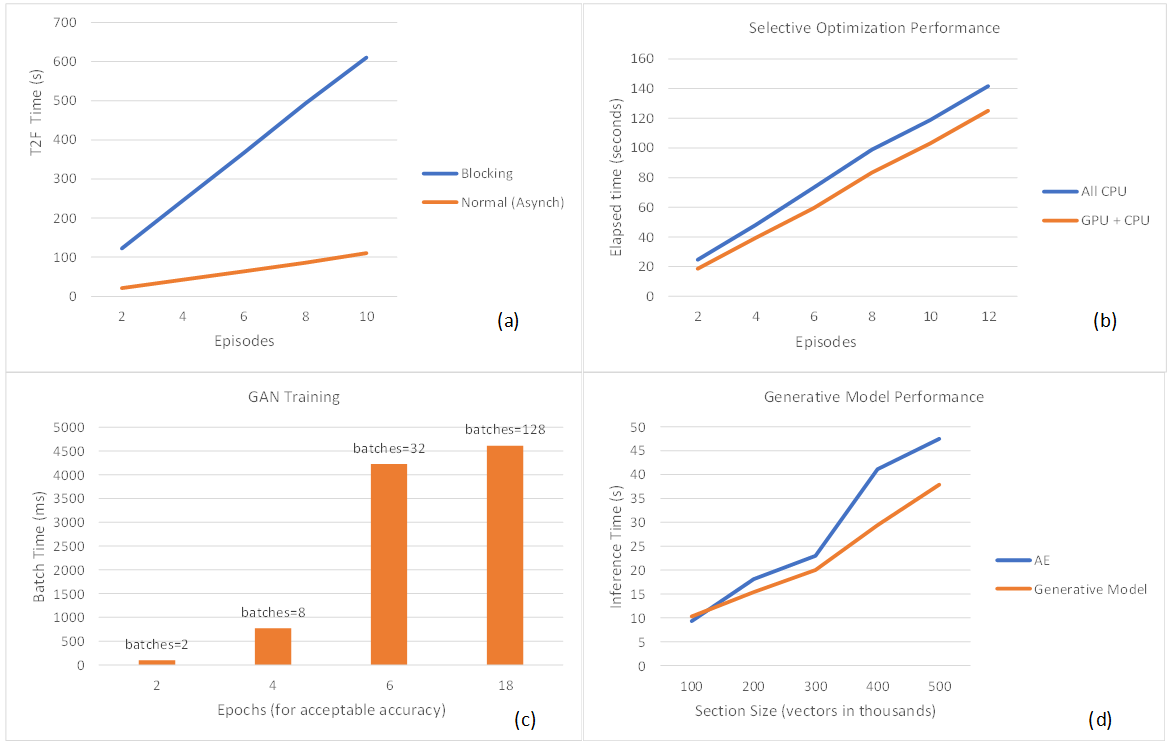
Hình 2. (a) Các lệnh gọi không đồng bộ cho suy luận MIG mang lại hiệu suất cao hơn so với việc chặn các cuộc gọi. (b) Tối ưu hóa có chọn lọc mang lại hiệu suất suy luận tốt hơn. (c) Quy mô lô đào tạo lớn hơn (ít lô hơn) rút ngắn thời gian cần thiết để đạt được độ chính xác chấp nhận được. (d) Các mô hình sáng tạo cải thiện hiệu suất suy luận.
Tóm lại, phân tích dự đoán là điều cần thiết để bảo trì trong kỷ nguyên chuyển đổi kỹ thuật số. Chúng tôi trình bày một giải pháp phù hợp với đặc điểm kỹ thuật đo từ xa của máy chủ Dell. Người ta chấp nhận rộng rãi rằng để sửa lỗi lặp lại, các hệ thống điều khiển phản hồi tuyến tính hoạt động tốt hơn so với các hệ thống phi tuyến tính tương ứng của chúng. Chúng tôi đã định hình các dự đoán để hành xử một cách tuyến tính. Bằng cách sử dụng các mô hình tổng quát, người ta có thể đạt được khả năng suy luận nhanh hơn. Chúng tôi đã đề xuất một cách mới để kết hợp các mô hình tổng quát với các mô hình mô phỏng Digital Twins (DT) để lập lịch trình được định hình bởi DRL. Các thử nghiệm của chúng tôi chỉ ra rằng GPU trong cụm phân tích giúp tăng tốc hiệu suất phản hồi trong các vòng phản hồi I4 (ví dụ: hỗ trợ MIG khi suy luận, tận dụng các mô hình tổng quát để tổng hợp điều khiển theo dõi nhanh).
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...