
Tin tức
VxRail và Intel® AMX, mang AI đến mọi nơi
Chúng ta đã chứng kiến sự tăng trưởng và áp dụng Trí tuệ nhân tạo (AI) theo cấp số nhân trên hầu hết mọi lĩnh vực trong những năm gần đây, trong đó nhiều lĩnh vực triển khai chiến lược AI của họ càng sớm càng tốt để khai thác những lợi ích và hiệu quả mà AI mang lại.
Với nền tảng VxRail của mình, chúng tôi đã hỗ trợ các GPU được tích hợp đầy đủ và cài đặt sẵn trong nhiều năm, với một loạt GPU NVIDIA có sẵn đã phục vụ cho tính toán, đồ họa hiệu suất cao và tất nhiên là cả khối lượng công việc AI.
Các GPU này được thiết lập như một phần của quá trình triển khai lần đầu tiên hệ thống VxRail của bạn (mặc dù việc cấp phép cho NVIDIA sẽ riêng biệt) và sẽ được hiển thị và quản lý trong vCenter. Ngoài việc tích hợp với vSphere và VxRail Manager, bạn cũng sẽ thấy việc quản lý vòng đời của GPU được đảm nhiệm thông qua vLCM, trong đó GPU vib sẽ được thêm vào gói LCM của VxRail và sau đó được nâng cấp như một phần của quá trình nâng cấp đó.
Khi xem xét loại bộ tăng tốc bạn cần cho hệ thống VxRail của mình, giờ đây có một tùy chọn bổ sung ngoài GPU rời, có thể có đủ khả năng tăng tốc để phục vụ khối lượng công việc AI của bạn.
 Hình 1. Tận dụng AI với VxRail
Hình 1. Tận dụng AI với VxRail
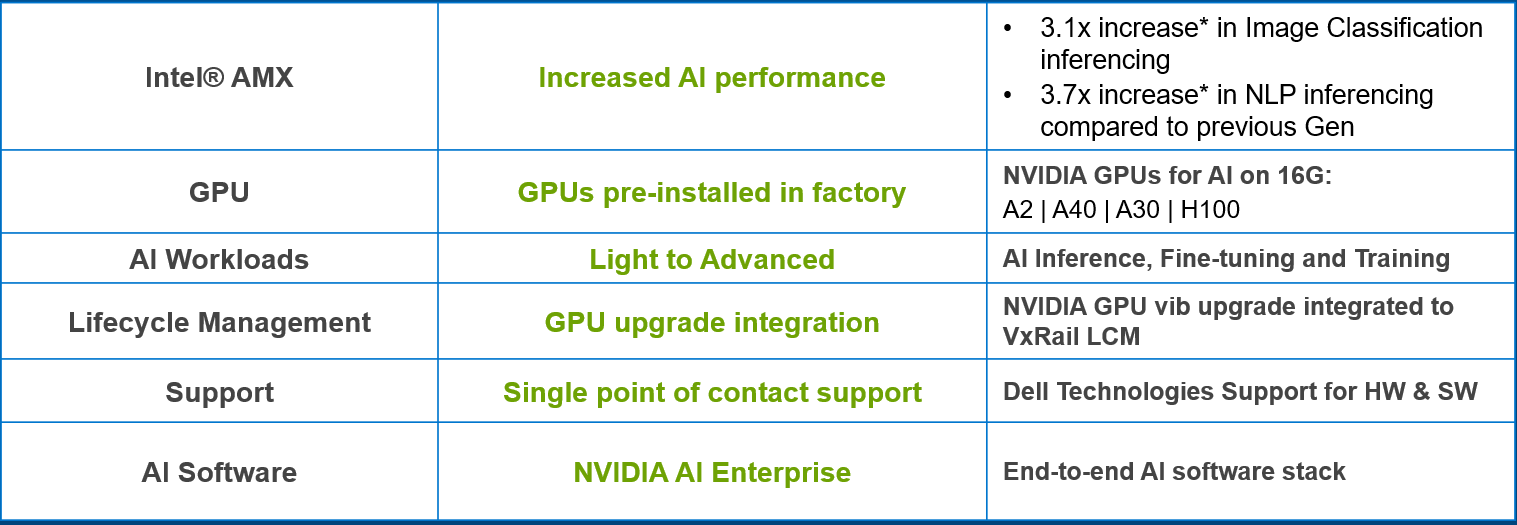
Nền tảng VxRail thế hệ thứ 16 của chúng tôi , được ra mắt vào mùa hè vừa qua, đi kèm với các bộ xử lý Intel® Xeon® có thể mở rộng thế hệ thứ 4 , tất cả đều đi kèm với bộ tăng tốc tích hợp có tên là Intel® Advanced Matrix Extensions (AMX) được nhúng sâu trong mọi lõi của bộ xử lý. Bộ tăng tốc Intel® AMX, mang lại lợi ích cho cả khối lượng công việc AI và HPC, được hỗ trợ ngay lập tức và đạt tiêu chuẩn mà không cần bất kỳ yêu cầu nào về trình điều khiển, phần cứng đặc biệt hoặc giấy phép bổ sung.
Trong blog này, chúng tôi sẽ đề cập đến thử nghiệm hiệu suất do nhóm Hiệu suất VxRail của chúng tôi kết hợp với Intel thực hiện, cũng như những lợi ích mà chúng tôi có thể mong đợi thấy khi chạy khối lượng công việc suy luận AI trên nền tảng VxRail Thế hệ thứ 16 sử dụng Intel® AMX.
Nhưng trước tiên – Intel® AMX là gì và nó hoạt động như thế nào?
Kiến trúc của Intel® AMX bao gồm hai thành phần:
- Các ô – bao gồm tám thanh ghi hai chiều lưu trữ các khối dữ liệu lớn, mỗi khối có kích thước 1kilobyte
- Phép nhân ma trận ô (TMUL) – một công cụ tăng tốc được gắn vào các ô để thực hiện các phép tính nhân ma trận cho AI
Trình tăng tốc hoạt động bằng cách kết hợp các tệp thanh ghi 2D lớn hơn được gọi là các ô xếp và một bộ hướng dẫn nhân ma trận, cho phép Intel® AMX cung cấp loại chức năng điện toán ma trận mà bạn thường thấy trong các bộ tăng tốc AI chuyên dụng (tức là GPU) trực tiếp vào lõi CPU của chúng tôi. Điều này cho phép khối lượng công việc AI chạy trên CPU thay vì chuyển chúng sang GPU chuyên dụng.
 Hình 2. Ô kiến trúc Intel AMX và TMUL
Hình 2. Ô kiến trúc Intel AMX và TMUL
Với chức năng này, bộ tăng tốc Intel® AMX hoạt động tốt nhất với khối lượng công việc AI dựa vào toán học ma trận, như xử lý ngôn ngữ tự nhiên, hệ thống đề xuất và nhận dạng hình ảnh. Bộ tăng tốc Intel® AMX mang lại khả năng tăng tốc cho cả hoạt động suy luận và học sâu trên các khối lượng công việc này, mang lại mức tăng hiệu suất đáng kể mà chúng tôi sẽ đề cập sau.
Có hai loại dữ liệu – INT8 và BF16 – được hỗ trợ cho Intel® AMX, cả hai đều cho phép nhân ma trận mà tôi đã đề cập trước đó.
Một số trường hợp sử dụng khối lượng công việc Intel® AMX bao gồm:
- Nhận dạng hình ảnh
- Xử lý ngôn ngữ tự nhiên
- Hệ thống khuyến nghị
- Xử lý phương tiện
- Dịch máy
Bạn đã nói kiểm tra hiệu suất?
Vâng, tôi đã làm vậy.
Với thử nghiệm này, chúng tôi đã thấy hiệu suất AI tăng lên cho hai bộ kết quả điểm chuẩn chứng minh mức tăng hiệu suất suy luận từ thế hệ này sang thế hệ khác được mang lại bởi nền tảng VxRail VE-660 thế hệ thứ 16 của chúng tôi (với Intel® AMX!) so với thế hệ thứ 15 trước đó Nền tảng VxRail.
Thử nghiệm tập trung vào việc suy luận hai nhiệm vụ AI khác nhau, một nhiệm vụ phân loại hình ảnh bằng mô hình ResNet50 và nhiệm vụ còn lại là xử lý ngôn ngữ tự nhiên với Mô hình lớn BERT. Phần sau đây bao gồm các chi tiết của thử nghiệm:
Kiểm tra điểm chuẩn:
- ResNet50 để phân loại hình ảnh
- Điểm chuẩn BERT cho Xử lý ngôn ngữ tự nhiên
Khung: TensorFlow 2.11
Bảng 1. Tổng quan về phần cứng VxRail đã được thử nghiệm
| Thế hệ | Thế hệ thứ 16 | Thế hệ thứ 15 | Thế hệ thứ 15 (bộ xử lý khác) |
| Tên hệ thống | VxRail VE-660 | VxRail E660N | VxRail E660N |
| Số nút | 4 | 4 | 4 |
| Các thành phần trên mỗi nút VE-660 | Các thành phần trên mỗi nút E660N | Các thành phần trên mỗi nút E660N | |
| Mẫu bộ xử lý | Intel® Xeon ® 6430 (32c) | Intel® Xeon ® 6338 (32c) | Intel® Xeon ® 6330 (28c) |
| Intel® AMX? | Đúng | KHÔNG | KHÔNG |
| Bộ xử lý trên mỗi nút | 2 | 2 | 2 |
| Số lõi trên mỗi nút | 64 | 64 | 56 |
| Tần số bộ xử lý | Tăng tốc Turbo 2,1 GHz, 3,4 GHz | Tăng tốc Turbo 2.0 GHz, 3.0 GHz | Tăng tốc Turbo 2,0 GHz, 3,10 GHz |
| Bộ nhớ trên mỗi nút | RAM 512GB | RAM 512GB | RAM 512GB |
| Kho | 2x nhóm đĩa
(1 x bộ đệm, 3 x dung lượng) |
2x nhóm đĩa
(1 x bộ đệm, 4 x dung lượng) |
2x nhóm đĩa
(1 x bộ đệm, 4 x dung lượng) |
| vSAN OSA | vSAN OSA 8.0 U2 | vSAN OSA 8.0 | vSAN OSA 8.0 |
| Phiên bản VxRail | Kỹ sư phát hành trước mã VxRail | 8.0.010 | 8.0.010 |
Chúng ta có thể thấy trong các hình sau đây rằng thông lượng phân loại hình ảnh ResNet50 đã tăng 3,1 lần và chúng ta thấy hiệu suất AI tăng 3,7 lần đối với kết quả điểm chuẩn BERT cho xử lý ngôn ngữ tự nhiên (NLP).
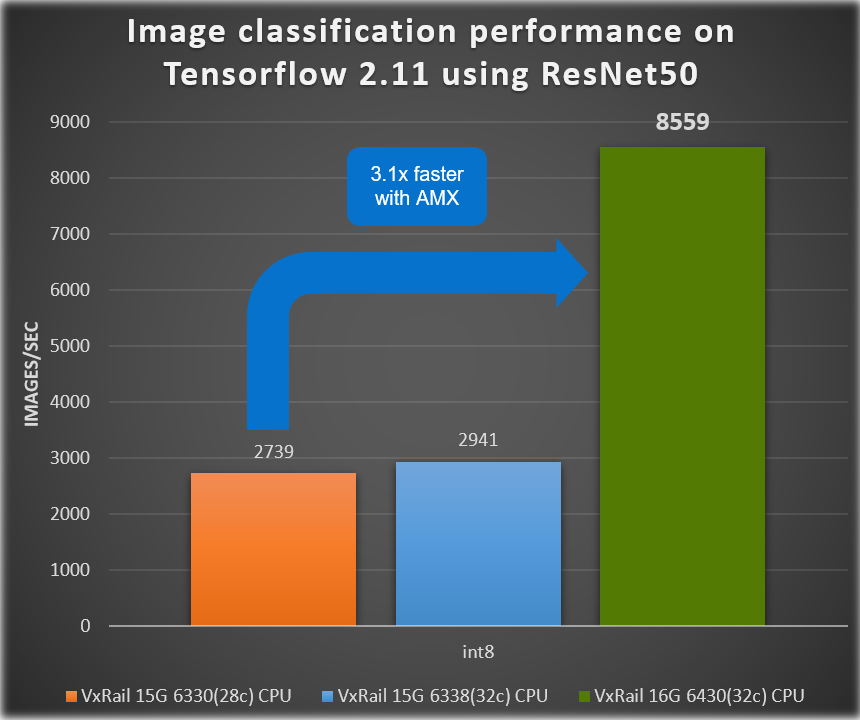 Hình 3. Kết quả suy luận từ thế hệ này sang thế hệ khác của VxRail – ResNet 50
Hình 3. Kết quả suy luận từ thế hệ này sang thế hệ khác của VxRail – ResNet 50
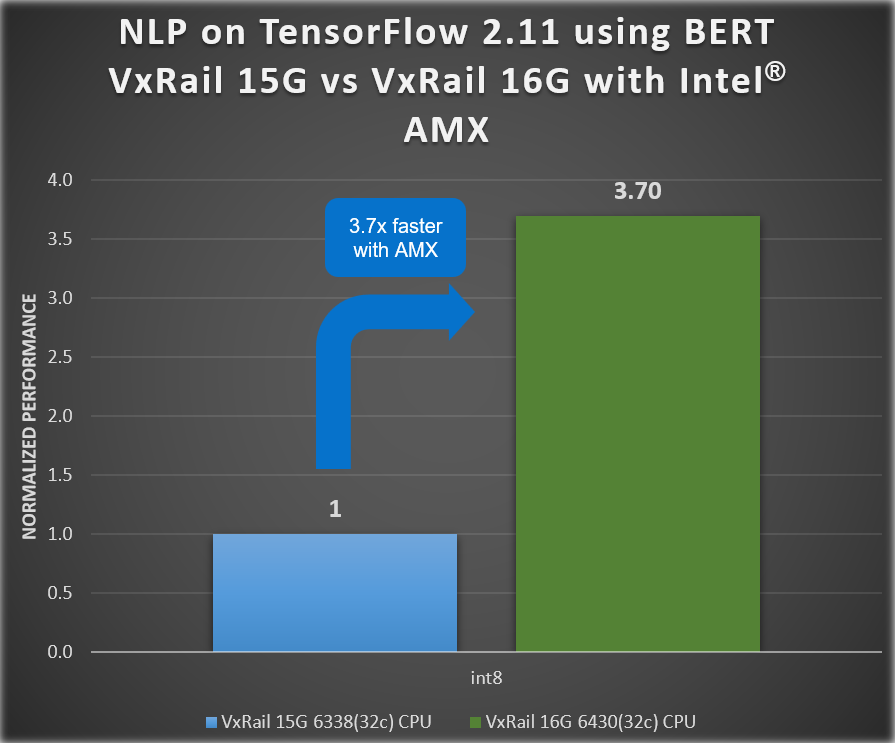 Hình 4. Kết quả suy luận từ thế hệ này sang thế hệ khác của VxRail – BERT
Hình 4. Kết quả suy luận từ thế hệ này sang thế hệ khác của VxRail – BERT
Sự gia tăng hiệu suất đặc biệt này minh họa mức tăng hiệu suất AI mà bạn có thể đạt được với Intel® AMX trên VxRail mà không cần đầu tư vào GPU chuyên dụng, cho phép bạn bắt đầu hành trình AI của mình bất cứ khi nào bạn muốn.
Trước khi chúng ta đi, hãy xem lại một số điểm nổi bật…
Intel® AMX và VxRail là…
- Đã được bao gồm trong bất kỳ bộ xử lý Intel nào trên nền tảng VxRail thế hệ thứ 16 VE-660 và VP-760
- Được tối ưu hóa cao cho các hoạt động ma trận thường gặp đối với khối lượng công việc AI
- Tiết kiệm chi phí, cho phép bạn chạy khối lượng công việc AI mà không cần GPU chuyên dụng
- Tích hợp để tăng hiệu suất AI trên nền tảng VxRail thế hệ thứ 16
- 3,1 x để phân loại hình ảnh*
- 3,7 x cho Xử lý ngôn ngữ tự nhiên (NLP)*
Hỗ trợ Intel® AMX và VxRail…
- Các khung AI phổ biến nhất, bao gồm TensorFlow, Pytorch, OpenVINO, v.v.
- kiểu dữ liệu int8 và bf16
- Khối lượng công việc đào tạo và suy luận AI của Deep Learning dành cho:
- Nhận dạng hình ảnh
- Xử lý ngôn ngữ tự nhiên
- Hệ thống khuyến nghị
- Xử lý phương tiện
- Dịch máy
(*Kết quả dựa trên mã VxRail trước khi phát hành kỹ thuật)
Phần kết luận
Nền tảng VE-660 và VP-760 VxRail của chúng tôi được trang bị bộ tăng tốc Intel® AMX tích hợp giúp cải thiện hiệu suất AI lên 3,1 lần để phân loại hình ảnh và 3,7 lần cho NLP. Sự kết hợp giữa nền tảng VxRail thế hệ thứ 16 này và bộ xử lý Intel® Xeon® thế hệ thứ 4 mang đến giải pháp tiết kiệm chi phí cho những khách hàng dựa vào Intel® AMX để đáp ứng SLA của họ nhằm tăng tốc khối lượng công việc AI.
Bài viết mới cập nhật
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...
Cơ sở hạ tầng CNTT: Mua hay đăng ký?
Nghiên cứu theo số liệu của IDC về giải pháp đăng ...