
Dell Technologies đã tham gia trình MLPerf trong hai năm qua. Đệ trình hiện tại là vòng thứ tư của chúng tôi đối với bộ đo điểm chuẩn suy luận MLPerf.
Blog này cung cấp các kết quả đóng cửa trung tâm dữ liệu MLPerf Inference v1.1 mới nhất trên các máy chủ Dell EMC từ phòng thí nghiệm Đổi mới HPC & AI của chúng tôi . Mục tiêu của blog này là hiển thị hiệu suất suy luận và hiệu suất/watt tối ưu cho các máy chủ GPU Dell EMC (PowerEdge R750xa, DSS8440 và PowerEdge R7525). Bạn có thể tìm thấy blog về hiệu suất MLPerf Inference v1.0 tại đây . Blog này cũng giải quyết các quy tắc điểm chuẩn, các ràng buộc và danh mục gửi. Chúng tôi khuyên bạn nên đọc nó để làm quen với các thuật ngữ và quy tắc MLPerf.
Kết quả đáng chú ý
Kết quả đáng chú ý của chúng tôi bao gồm:
- Máy chủ DSS8440 (10 x A100-PCIE-80GB, TensorRT) mang lại kết quả Số Một trên tất cả những người gửi về:
- BERT 99 Ngoại tuyến và Máy chủ
- BERT 99.9 Ngoại tuyến và Máy chủ
- RNN-T ngoại tuyến và máy chủ
- SSD-Resnet34 Ngoại tuyến và Máy chủ
- Máy chủ R750xa (4 x A100-PCIE-80GB, TensorRT) mang lại kết quả Số Một trên mỗi bộ tăng tốc PCIe cho:
- 3D UNet Ngoại tuyến và 3D UNet 99.9 Ngoại tuyến
- Resnet50 Ngoại tuyến và Máy chủ Resnet50
- Máy chủ BERT 99 Ngoại tuyến và BERT 99
- Máy chủ BERT 99.9 Ngoại tuyến và BERT 99.9
- DLRM 99 Ngoại tuyến và Máy chủ DLRM
- Máy chủ DLRM 99.9 Ngoại tuyến và DLRM 99.9
- Máy chủ RNN-T ngoại tuyến và RNN-T
- SSD-Resnet34 Ngoại tuyến và Máy chủ SSD-Resnet34
- Máy chủ R750xa (4 x A100-PCIE-80GB, MIG) mang lại kết quả Số Một trên mỗi kết quả MIG của máy gia tốc PCIe cho:
- Resnet50 Ngoại tuyến và Máy chủ Resnet50
- Máy chủ BERT 99 Ngoại tuyến và BERT 99
- Máy chủ BERT 99.9 Ngoại tuyến và BERT 99.9
- Máy chủ SSD-Resnet34 Ngoại tuyến và SSD-Reset34
- Máy chủ R750xa (4 x A100-PCIE-80GB, Triton) mang lại kết quả Số Một trên mỗi kết quả Triton tăng tốc PCIe cho:
- 3D UNet Ngoại tuyến và 3D UNet 99.9 Ngoại tuyến
- Resnet50 Ngoại tuyến và Máy chủ Resnet50
- Máy chủ BERT 99
- Máy chủ BERT 99.9 Ngoại tuyến và BERT 99.9
- DLRM 99 Ngoại tuyến và Máy chủ DLRM
- Máy chủ DLRM 99.9 Ngoại tuyến và DLRM 99.9
Để cho phép so sánh tương tự các kết quả của Dell Technologies, chúng tôi đã chọn thử nghiệm trong bộ phận khép kín Trung tâm dữ liệu, như được hiển thị trong blog này. Khách hàng và đối tác có thể tin tưởng vào kết quả của chúng tôi, tất cả đều được MLCommons TM chính thức chứng nhận. Các kết quả được chứng nhận chính thức được đánh giá ngang hàng, đã trải qua các bài kiểm tra tuân thủ và tuân thủ các ràng buộc do MLCommons thực thi. Nếu muốn, khách hàng và đối tác cũng có thể sao chép kết quả của chúng tôi. Bạn có thể tìm thấy blog giải thích cách chạy MLPerf Inference v1.1 tại đây .
Cái gì mới?
Sự khác biệt giữa suy luận MLPerf v1.1 và suy luận MLPerf v1.0 là kịch bản Đa luồng không được dùng nữa. Tất cả các điểm chuẩn và quy tắc khác vẫn giữ nguyên như đối với suy luận MLPerf phiên bản 1.0.
Đối với các lần gửi v1.1 tới MLCommons, hơn 1700 kết quả đã được gửi. Số lượng người gửi tăng từ 17 lên 21.
Các kết quả đệ trình của Dell Technologies bao gồm các cấu hình SUT mới, chẳng hạn như GPU NVIDIA A100 Tensor Core 80GB với TDP 300 W, A30, A100-MIG và kết quả nguồn với các máy chủ R750xa được NVIDIA chứng nhận.
Kết quả điểm chuẩn MLPerf Inference 1.1
Các biểu đồ sau bao gồm các chỉ số hiệu suất cho các kịch bản Ngoại tuyến và Máy chủ. Nhìn chung, kết quả của Dell Technologies bao gồm khoảng 200 kết quả về hiệu suất và 80 kết quả về hiệu năng và sức mạnh. Những kết quả này đóng vai trò là điểm tham chiếu để cho phép định cỡ các cụm học tập sâu. Số lượng kết quả cao hơn trong lần gửi của chúng tôi giúp tinh chỉnh thêm các câu trả lời cho các câu hỏi cụ thể mà khách hàng có thể có.
Đối với kịch bản Ngoại tuyến, chỉ số hiệu suất là Mẫu ngoại tuyến mỗi giây. Đối với kịch bản Máy chủ, chỉ số hiệu suất là số truy vấn mỗi giây (QPS). Nói chung, các số liệu đại diện cho thông lượng. Một thông lượng cao hơn là một kết quả tốt hơn. Trong các biểu đồ sau, trục Y là trục được chia tỷ lệ theo cấp số nhân biểu thị thông lượng và trục X biểu thị các SUT và các mô hình tương ứng của chúng (được mô tả trong phần phụ lục).
Hình 1, 2 và 3 cho thấy hiệu suất của các máy chủ Dell EMC khác nhau được đánh giá chuẩn cho các kiểu máy khác nhau. Tất cả các máy chủ này đều hoạt động tối ưu và mang lại thông lượng cao. Phần phụ trợ bao gồm NVIDIA Triton, NVIDIA TensorRT trên các kịch bản Ngoại tuyến và Máy chủ. Một số kết quả thể hiện trong hình 1 và 3 bao gồm số MIG.
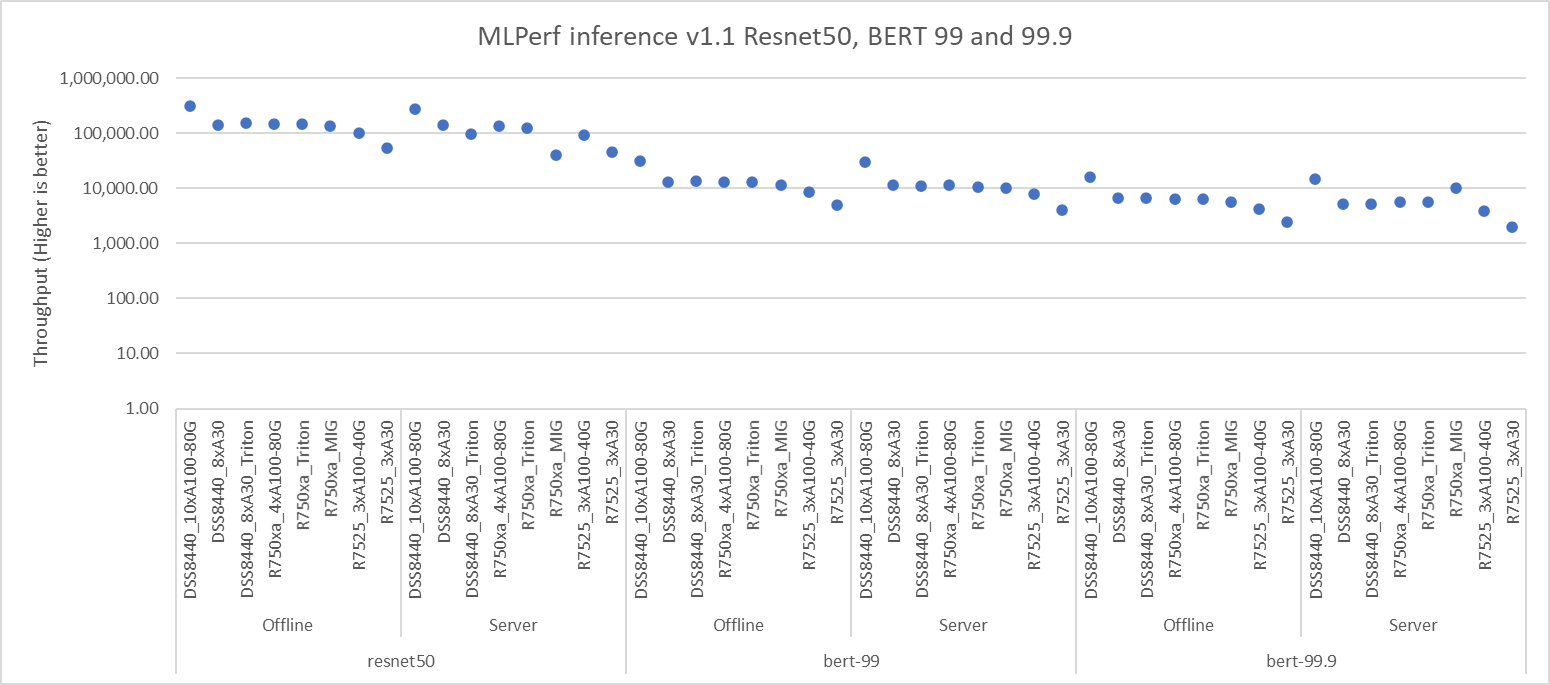
Hình 1: Resnet50, mặc định BERT và kết quả có độ chính xác cao
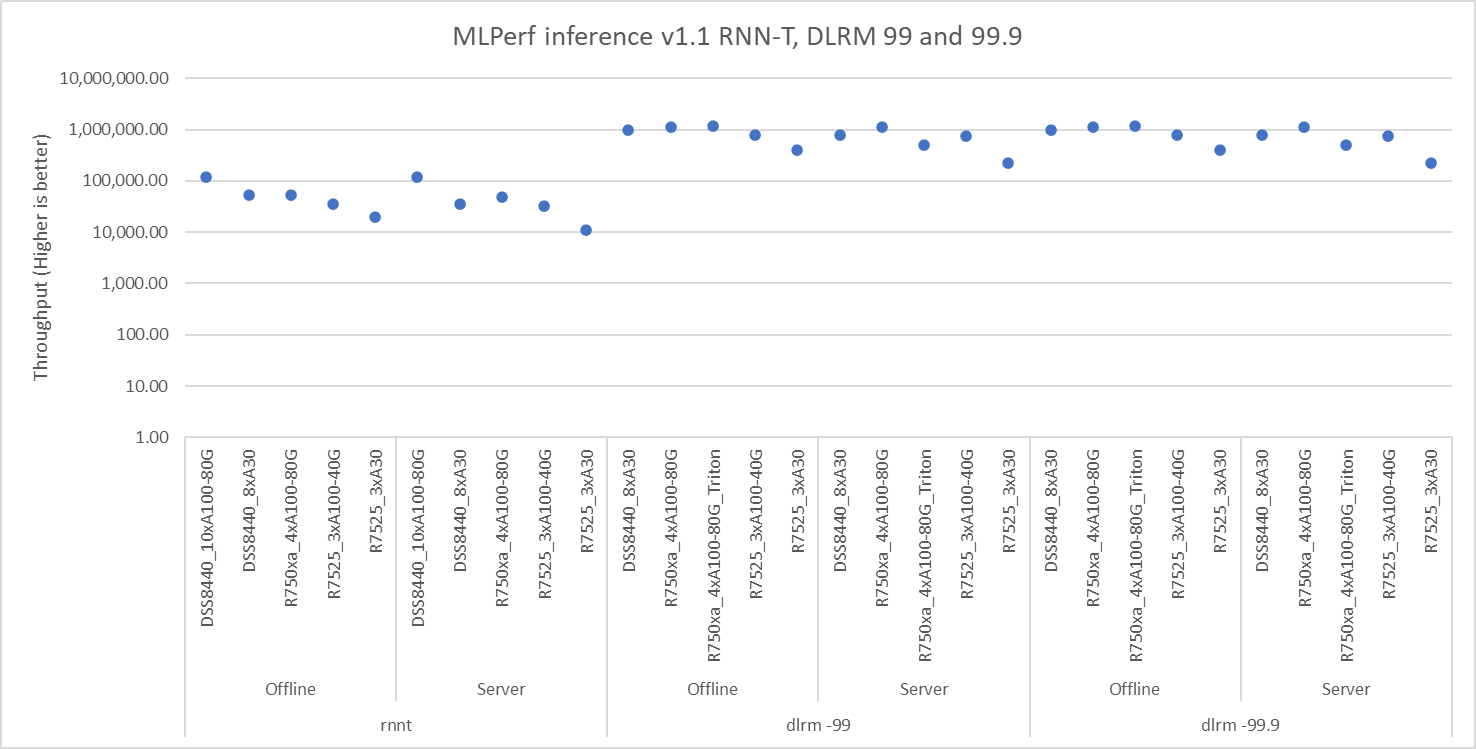
Hình 2: Kết quả mặc định RNN-T, DLRM và độ chính xác cao
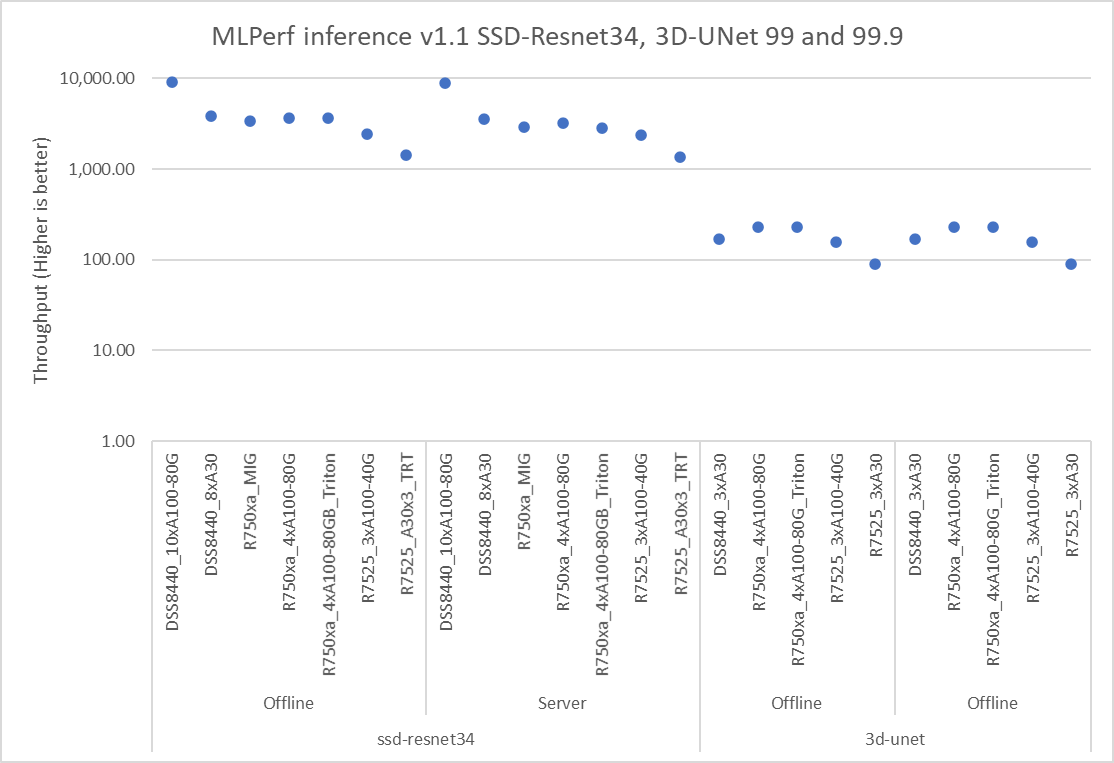
Hình 3: SSD-Resnet34, mặc định 3D-UNet và kết quả có độ chính xác cao
Hình 4 cho thấy hiệu suất của máy chủ Dell EMC R750xa đã được đánh giá chuẩn cho các mẫu 3D-UNet, BERT 99, BERT 99.9, Resnet và SSD-Resnet34. SUT cung cấp thông lượng cao trong khi vẫn duy trì mức tiêu thụ điện năng thấp. Thông lượng cao hơn đã đạt được với mức sử dụng năng lượng tương tự cho các kiểu máy khác nhau. Những thông lượng này đã thiết lập kết quả của chúng tôi về hiệu suất tối ưu và hiệu suất tối ưu trên mỗi loại watt.
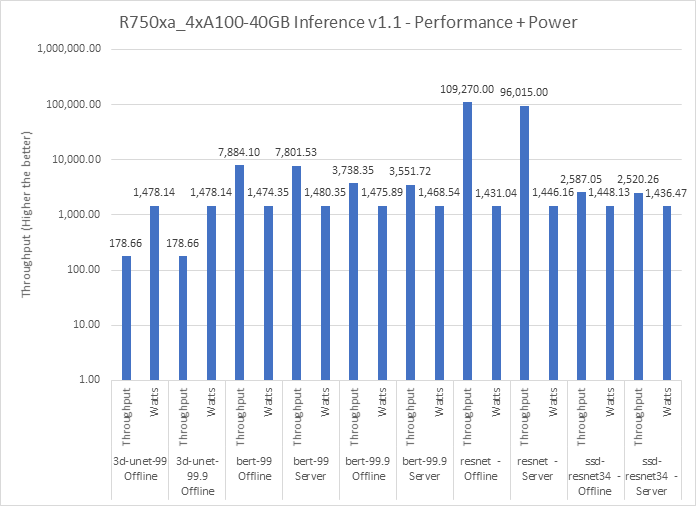
Hình 4: Hiệu suất và năng lượng cung cấp với inference v1.1 với R750xa và 4 x NVIDIA A100–40G
Quan sát về kết quả từ Dell Technologies
Tất cả các kết quả trước đó đều được gửi chính thức tới tập đoàn MLCommons TM và được xác minh. Nội dung gửi bao gồm hiệu suất và các số liên quan đến sức mạnh. Các bài nộp của Dell Technologies bao gồm khoảng 200 kết quả về hiệu suất và 80 kết quả về hiệu suất và sức mạnh.
Các loại tác vụ khối lượng công việc khác nhau như phân loại hình ảnh, phát hiện đối tượng, phân đoạn hình ảnh y tế, lời nói thành văn bản, xử lý ngôn ngữ và đề xuất là một phần của những kết quả đầy hứa hẹn này. Các mô hình này đã đáp ứng các mục tiêu chất lượng dịch vụ như mong đợi của tập đoàn MLCommons.
Với các loại GPU khác nhau như GPU NVIDIA A30 Tensor Core, các biến thể NVIDIA A100 khác nhau như A100 40 GB PCIe và A100 80 GB PCIe cũng như các CPU khác nhau từ AMD và Intel, máy chủ Dell EMC hoạt động với hiệu suất và kết quả năng lượng tối ưu. Bạn có thể tìm thấy các kết quả cấu hình Dell EMC SUT khác cho GPU NVIDIA A40, RTX8000 và T4 trong kết quả v1.0 , có thể dùng kết quả này để so sánh với kết quả v1.1 .
Nội dung gửi bao gồm các kết quả từ các chương trình phụ trợ suy luận khác nhau, chẳng hạn như NVIDIA TensorRT , và GPU đa phiên bản (MIG) . Phụ lục bao gồm một bản tóm tắt về ngăn xếp phần mềm NVIDIA.
Tất cả các hệ thống của chúng tôi đều được làm mát bằng không khí. Tính năng này cho phép quản trị viên trung tâm dữ liệu thực hiện tối thiểu hoặc không thay đổi để phù hợp với các hệ thống này trong khi vẫn mang lại hiệu suất suy luận thông lượng cao. Hơn nữa, máy chủ Dell EMC cung cấp hiệu suất cao trên mỗi watt hiệu quả hơn mà không cần thêm các ràng buộc về năng lượng đáng kể.
Sự kết luận
Trong blog này, chúng tôi đã định lượng hiệu suất suy luận MLCommons phiên bản 1.1 trên các máy chủ Dell EMC khác nhau như máy chủ DSS8440 và PowerEdge R750xa và R7525, cho ra nhiều kết quả. Khách hàng có thể sử dụng những kết quả này để giải quyết hiệu suất suy luận tương đối được cung cấp bởi các máy chủ này. Máy chủ Dell EMC là máy tính mạnh mẽ cung cấp khả năng suy luận thông lượng cao cho khách hàng suy luận các yêu cầu trong các tình huống và loại khối lượng công việc khác nhau.
Bước tiếp theo
Trong các blog trong tương lai, chúng tôi dự định mô tả:
- Cách chạy MLPerf Inference v1.1
- Máy chủ R750xa làm nền tảng cho suy luận v1.1
- Máy chủ DSS8440 làm nền tảng cho suy luận v1.1
- So sánh hiệu suất suy luận v1.0 với hiệu suất suy luận v1.1
Ruột thừa
ngăn xếp phần mềm NVIDIA
NVIDIA Triton Inference Server là phần mềm nguồn mở hỗ trợ triển khai các mô hình AI trên quy mô lớn trong sản xuất. Nó là một giải pháp suy luận được tối ưu hóa cho cả CPU và GPU. Triton hỗ trợ giao thức HTTP/REST và GRPC cho phép các máy khách từ xa yêu cầu tham chiếu cho bất kỳ mô hình nào mà máy chủ quản lý. Nó bổ sung hỗ trợ cho nhiều khung học sâu, cho phép suy luận hiệu suất cao và được thiết kế để xem xét CNTT, DevOps và MLOps.
NVIDIA TensorRT là SDK dành cho suy luận học sâu, hiệu suất cao bao gồm trình tối ưu hóa suy luận và thời gian chạy. Nó cho phép các nhà phát triển nhập các mô hình được đào tạo từ tất cả các khung học sâu chính và tối ưu hóa chúng để triển khai với thông lượng cao nhất và độ trễ thấp nhất, đồng thời duy trì độ chính xác của các dự đoán. Các ứng dụng được tối ưu hóa cho TensorRT hoạt động nhanh hơn tới 40 lần trên GPU NVIDIA so với các nền tảng chỉ có CPU trong quá trình suy luận.
MIG có thể phân vùng GPU A100 thành tối đa bảy phiên bản, mỗi phiên bản được cách ly hoàn toàn với bộ nhớ băng thông cao, bộ đệm và lõi tính toán của riêng chúng. Quản trị viên có thể hỗ trợ mọi khối lượng công việc, từ nhỏ nhất đến lớn nhất, cung cấp GPU có kích thước phù hợp với chất lượng dịch vụ (QoS) được đảm bảo cho mọi công việc, tối ưu hóa việc sử dụng và mở rộng phạm vi tiếp cận của tài nguyên máy tính được tăng tốc cho mọi người dùng.
cấu hình SUT
Chúng tôi đã chọn các máy chủ có các loại GPU NVIDIA khác nhau làm SUT của mình để tiến hành các điểm chuẩn suy luận trung tâm dữ liệu. Các bảng sau đây liệt kê các cấu hình hệ thống MLPerf cho các máy chủ này.
Lưu ý : Trong các bảng sau, điểm khác biệt chính trong ngăn xếp phần mềm là việc sử dụng Máy chủ suy luận NVIDIA Triton.
Bảng 3: Cấu hình hệ thống MLPerf cho máy chủ Dell EMC DSS 8440
| Nền tảng | DSS8440_A100 | DSS8440_A30 | DSS8440_A30 |
| Mã hệ thống MLPerf | DSS8440_A100-PCIE-80GBx10_TRT | DSS8440_A30x8_TRT | DSS8440_A30x8_TRT_Triton |
| Hệ điều hành | CentOS 8.2.2004 | ||
| CPU | CPU Intel Xeon Vàng 6248R @ 3.00 GHz | Intel Xeon Vàng 6248R | Intel Xeon Vàng 6248R |
| Kỉ niệm | 768 GB | 1TB | |
| GPU | NVIDIA A100-PCIe-80GB | NVIDIA A30 | |
| Yếu tố hình thức GPU | PCIe | ||
| số lượng GPU | 10 | số 8 | |
| ngăn xếp phần mềm | TenorRT 8.0.2
CUDA 11.3 cuDNN 8.2.1 Trình điều khiển 470.42.01 DALI 0.31.0 |
||
| Triton 21.07 | |||
Bảng 4: Cấu hình hệ thống MLPerf cho máy chủ PowerEdge
| Nền tảng | R750xa_A100 | R750xa_A100 | R750xa_A100 | R7525_A100 | R7525_A30 |
| Mã hệ thống MLPerf | R750xa_A100-PCIE-80GB-MIG_28x1g.10gb_TRT_Triton | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100-PCIE-80GBx4_TRT_Triton | R7525_A100-PCIE-40GBx3_TRT | R7525_A30x3_TRT |
| Hệ điều hành | CentOS 8.2.2004
|
||||
| CPU | Intel Xeon vàng 6338 | Bộ xử lý 32 nhân AMD EPYC 7502 | AMD EPYC 7763 | ||
| Kỉ niệm | 1TB | 512GB | 1TB | ||
| GPU | NVIDIA A100-PCIE-80GB (7x1g.10gb MIG) | NVIDIA A100-PCIE-80GB
|
NVIDIA A100-PCIE-40GB | NVIDIA A30 | |
| Yếu tố hình thức GPU | PCIe | ||||
| số lượng GPU | 4 | 3 | |||
| ngăn xếp phần mềm | TenorRT 8.0.2
CUDA 11.3 cuDNN 8.2.1 Trình điều khiển 470.42.01 DALI 0.31.0 |
||||
| Triton 21.07 | Triton 21.07 | ||||
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...