
Học sâu là một công cụ mạnh mẽ dành cho các doanh nghiệp đang tìm cách thu thập thông tin chi tiết có thể hành động và cho phép phản hồi tự động đối với một loạt dữ liệu.
_________________________________

Trong phần trước của loạt bài này, “ Đi sâu vào Học máy ”, chúng ta đã xem xét một số cách tiếp cận phổ biến đối với học máy, đây là một tập hợp con của AI cung cấp cho các hệ thống khả năng học hỏi từ dữ liệu và cải thiện theo thời gian mà không cần lập trình rõ ràng. Trong bài viết mới nhất này trong loạt bài Enterprise AI của chúng tôi, chúng tôi cung cấp tổng quan về học sâu, đây là một cách tiếp cận cụ thể đối với danh mục học máy tổng quát hơn. Cũng như các kỹ thuật học máy khác, học sâu là một khối xây dựng quan trọng cho trí tuệ nhân tạo trong doanh nghiệp.
Trước tiên, hãy nhanh chóng xem xét học máy là gì. Học máy đề cập đến quá trình đào tạo một mô hình, không gì khác hơn là chức năng ánh xạ đầu vào (ví dụ: quy mô ngôi nhà, sở thích của khách hàng) thành đầu ra (ví dụ: giá trị căn nhà, đề xuất sản phẩm mới). Quá trình đào tạo này cung cấp một lượng lớn dữ liệu vào các thuật toán giúp mô hình có khả năng học cách thực hiện một nhiệm vụ được nhắm mục tiêu. Ở cấp độ đơn giản nhất, máy học ánh xạ các đầu vào đã biết với các đầu ra đã biết để huấn luyện một mô hình. Hồi quy tuyến tính là một ví dụ về một hình thức học máy cơ bản được sử dụng để thể hiện mối quan hệ giữa các biến đầu vào và đầu ra, thường được biểu thị dưới dạng độ dốc và tung độ gốc Y trong biểu đồ. Vui lòng tham khảo “ Đi sâu vào Học máy ” để biết tổng quan về các kỹ thuật học máy.
Học sâu là một loại học máy xử lý các mối quan hệ phức tạp hơn nhiều giữa đầu vào và đầu ra. Học sâu thường được sử dụng với dữ liệu phi cấu trúc trong các ứng dụng nhận dạng hình ảnh, nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên. Các mối quan hệ được liên kết với các loại dữ liệu này—hình ảnh, âm thanh, văn bản, video—không thể được ánh xạ trên các trục XY.
Hãy lấy một ví dụ đơn giản. Giả sử bạn có nhiều hình ảnh và bạn muốn đào tạo một mô hình mạng thần kinh để xác định hình ảnh nào chứa mèo hoặc chó. Trong trường hợp này, bạn huấn luyện mô hình trên một số lượng lớn các hình ảnh có nhãn “mèo” hoặc “chó”, nghĩa là một nơi nào đó trong hình ảnh là một con mèo hoặc một con chó. Mô hình thực hiện các tính toán mở rộng trên tất cả các đầu vào có nhãn là “mèo” và cuối cùng phát triển các quy tắc nội bộ cho các đặc điểm của mèo (hay chính xác hơn là hình ảnh của mèo). Với đủ hình ảnh về mèo—thuộc các loại khác nhau, ở các tư thế khác nhau, trong ánh sáng và bối cảnh khác nhau, v.v.—cuối cùng, thông qua tính toán khổng lồ, nó học cách nhận ra các đặc điểm khiến một con mèo trở thành một con mèo.
Tương tự như vậy đối với tất cả các hình ảnh được gắn nhãn “chó”, nếu nó có đủ (chính xác) các hình ảnh được gắn nhãn bao gồm chó. Trong quá trình này, mô hình đưa ra các quy tắc riêng của nó — bạn không nói cho mô hình biết các quy tắc đó; bạn chỉ cần nói với nó “đây là hình ảnh của một con mèo” và “đây là hình ảnh của một con chó.” Sau khi mô hình được đào tạo và xác thực, bạn có thể đưa nó vào hoạt động trên các tập hợp hình ảnh mà không cần nhãn và nó sẽ tìm thấy hầu hết các chú chó và mèo cho bạn.
Quá trình học sâu
Vì vậy, làm thế nào để mô hình đạt được điều đó? Học sâu sử dụng mạng thần kinh nhân tạo đa cấp để đào tạo các mô hình. Mạng thần kinh xử lý dữ liệu để xác định các quy tắc và tính năng phổ biến liên quan đến dữ liệu. Dựa trên rất nhiều toán học mạnh mẽ và bắt chước lỏng lẻo các chức năng của bộ não con người, mỗi lớp của mạng nhận và xử lý đầu vào và biến chúng thành đầu ra. Kết quả là một hàm phức tạp, không thể biểu diễn được ánh xạ đầu vào thành đầu ra, thông qua một số lớp ẩn thực hiện các phép tính lớn. ( Mạng lưới thần kinh sâu sẽ có nhiều lớp ẩn.)
Có nhiều cách tiếp cận để học sâu, một số trong đó cơ bản hơn những cách khác. Trong bài đăng này, chúng tôi sẽ nêu bật ba cách tiếp cận cơ bản và phổ biến đối với mạng nơ-ron được sử dụng trong học sâu: mạng nhận thức đa lớp, mạng nơ-ron tích chập và mạng nơ-ron tuần hoàn. Những cách tiếp cận khác nhau để học sâu mang lại lợi thế cho các ứng dụng khác nhau. Một lần nữa, có nhiều loại phương pháp học sâu khác và lĩnh vực này đang phát triển nhanh chóng; chúng ta sẽ khám phá các loại và trường hợp sử dụng bổ sung trong các bài đăng bổ sung để theo dõi sau trong loạt bài này.
Mạng perceptron nhiều lớp
Mạng perceptron đa lớp (MLP) là dạng mạng nơ-ron sâu lâu đời nhất và được sử dụng phổ biến nhất. MLP là một loại thuật toán học sâu hoạt động tốt với việc phân loại đơn giản dữ liệu có cấu trúc và phi cấu trúc cũng như với các vấn đề hồi quy tuyến tính.
Các mạng được kết nối đầy đủ này giống như các chồng nút tính toán, trong đó mỗi nút trong mỗi lớp được kết nối với tất cả các nút trong lớp tiếp theo. Khi dữ liệu được đưa lên mạng, mỗi nút sẽ tổng hợp đầu vào của nó và chuyển đầu vào đó sang lớp tiếp theo. Điều này hoạt động giống như các tế bào thần kinh trong não: các nút nhận đầu vào rồi kích hoạt, gửi kết quả đầu ra đến các nút khác.
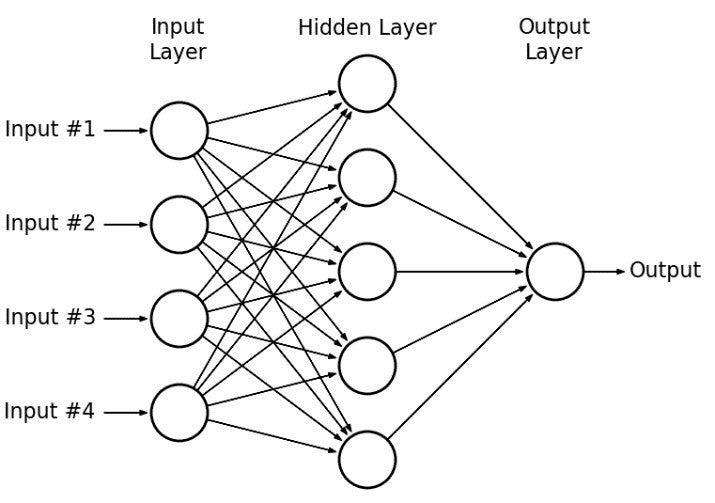 DellEMC
DellEMCHình 1 : Một ví dụ giả định về mạng perceptron đa lớp 2 Hình ảnh này xuất hiện trong nghiên cứu “ Đánh giá Mạng nơ-ron nhân tạo để ước tính độ sâu bằng cách sử dụng hình ảnh vệ tinh có độ phân giải cao ở các hồ cạn: Nghiên cứu điển hình Hồ El Burullus ,” Tạp chí Công nghệ Nước Quốc tế, IWTJ . tập 5, số 4, tháng 12 năm 2015.
Mạng thần kinh tích chập
Mạng thần kinh chuyển đổi (CNN) là một loại thuật toán học sâu thường được sử dụng trong các ứng dụng tập trung vào hình ảnh. CNN có thể khám phá các tính năng trong hình ảnh và xác định mối quan hệ giữa các hình ảnh đó. Chúng hoạt động tốt cho các ứng dụng như phân loại hình ảnh, nhận dạng khuôn mặt, phát hiện đối tượng và phân đoạn hình ảnh.
CNN tìm kiếm các mẫu định kỳ trong hình ảnh. Trong CNN, các lớp của mạng thần kinh không được kết nối đầy đủ. Họ nhìn vào các phần hoặc các phần của hình ảnh, thay vì nhìn vào toàn bộ hình ảnh cùng một lúc. Cách tiếp cận này giúp quá trình đào tạo diễn ra nhanh hơn và nó cho phép bạn xây dựng các mạng phức tạp hơn nhiều mà không làm cho chúng không thể đào tạo được. Các lớp tích chập thường được kết hợp với các loại lớp khác (được kết nối đầy đủ, nhóm tối đa, v.v.) để tăng độ chính xác đồng thời tối ưu hóa hiệu quả. Hiện tại, đừng lo lắng về các loại lớp khác này; chúng tôi sẽ giải thích điều đó trong một bài viết sau. Chỉ cần hiểu rằng CNN sử dụng nhiều lớp, bao gồm các lớp tích chập để cô lập các mảnh hình ảnh nhằm trở nên rất tốt trong việc phân loại hình ảnh, phát hiện đối tượng, v.v., điều đó thậm chí có thể được sử dụng để nhận dạng khuôn mặt với độ chính xác cao!
Dưới đây là một vài ví dụ với bối cảnh doanh nghiệp hơn:
- Một công ty vận chuyển có thể đào tạo một mô hình để nhận biết liệu hình ảnh của những chiếc hộp trên băng tải dành cho xe tải có bị hư hỏng hay không bằng cách sử dụng nhiều hình ảnh của cả những chiếc hộp không bị hư hại và bị hư hại.
- Một cửa hàng có thể đào tạo một mô hình để nhận biết sản phẩm mà người tiêu dùng đã đặt trên một bề mặt phẳng để xác định thứ mà người mua muốn mua—chẳng hạn như sản phẩm tươi sống, và thuộc loại nào—và do đó, tính phí bao nhiêu, tức là một máy quét cho mọi thứ, kể cả những thứ không có mã vạch.
- Một công ty sản xuất có thể đào tạo một mô hình để nhận biết liệu các bộ phận của máy móc—bánh răng, dây đai, v.v.—có bị hỏng, hư hỏng hoặc không thẳng hàng hay không.
Đây là những ví dụ đơn giản cho mục đích giải thích; một số công ty đã đào tạo các mô hình phức tạp hơn nhiều để cải thiện hoạt động và dịch vụ. Chúng tôi sẽ cung cấp các ví dụ về những điều này sau trong loạt blog này.
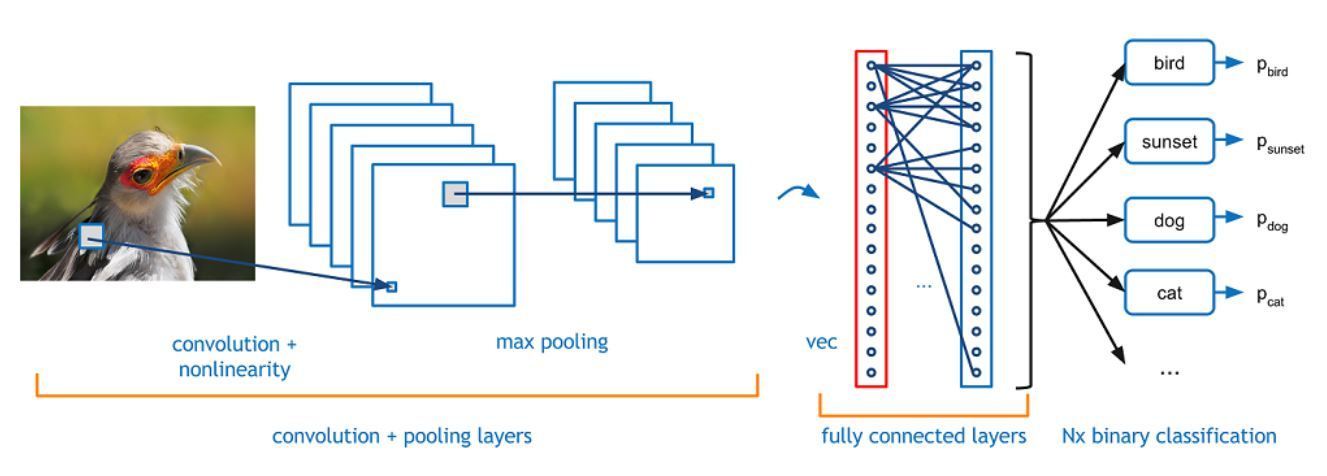 DellEMC
DellEMCHình 2 : Mạng nơ ron tích chập 3 Những hình ảnh này xuất hiện trong “ Hướng dẫn cho người mới bắt đầu để hiểu về mạng nơ ron tích chập ,” của Adit Deshpande.
Mạng thần kinh định kỳ
Mạng thần kinh định kỳ (RNN) là một loại mạng thần kinh sử dụng thông tin từ quá khứ để hiểu hiện tại và đưa ra dự đoán về tương lai. RNN có thể được sử dụng trong nhiều ứng dụng doanh nghiệp, từ dịch ngôn ngữ đến bảo trì dự đoán đến chăm sóc sức khỏe có sự hỗ trợ của AI.
Nguyên lý trung tâm ở đây là những gì đang xảy ra bây giờ có liên quan đến những gì đã xảy ra trong quá khứ. Ví dụ, trong dịch ngôn ngữ, RNN xây dựng dựa trên ngữ cảnh của các từ và câu xuất hiện trước đó để hiểu cách dịch chính xác các câu trong hiện tại.
Ví dụ: các công ty muốn tối ưu hóa đường ống và hàng tồn kho của họ để họ không bao giờ hết nguyên liệu để sản xuất sản phẩm của mình cũng như không bao giờ hết sản phẩm mà khách hàng muốn mua. Tuy nhiên, họ cũng muốn giảm thiểu lượng hàng dư thừa cần lưu trữ và điều đó có thể dẫn đến mất lợi nhuận nếu giá giảm trước khi các mặt hàng được bán. Vì vậy, các công ty hiện có thể sử dụng RNN để phát triển các mô hình chính xác hơn nhằm tối ưu hóa việc mua và sản xuất, nhờ đó, tối đa hóa lợi nhuận.
điểm chính
Học sâu là một công cụ mạnh mẽ dành cho các doanh nghiệp đang tìm cách thu thập thông tin chi tiết có thể hành động và cho phép phản hồi tự động đối với một lượng lớn dữ liệu, đặc biệt là dữ liệu phi cấu trúc, từ tất cả các loại thiết bị, Internet vạn vật (IoT), phương tiện truyền thông xã hội và – tất nhiên – từ dữ liệu của công ty các hệ thống. Với những kỹ thuật này, bạn có thể tìm thấy các mối quan hệ mới, rút ra những hiểu biết chính xác hơn từ các loại dữ liệu đa dạng và biến dữ liệu đó thành giá trị kinh doanh.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...