
Với việc phát hành Bộ xử lý sê-ri AMD EPYC 7003 (kiến trúc có tên mã là “Milan”), các máy chủ Dell EMC PowerEdge hiện đã được nâng cấp để hỗ trợ các tính năng mới. Blog này phác thảo kiến trúc Bộ xử lý Milan và các cài đặt BIOS được đề xuất để mang lại hiệu suất điểm chuẩn HPC Synthetic tối ưu. Các blog sắp tới sẽ tập trung vào hiệu suất ứng dụng và đặc tính của các ứng dụng phần mềm từ các lĩnh vực khoa học khác nhau như Khoa học thời tiết, Động lực học phân tử và Động lực học chất lỏng tính toán.
AMD Milan với các lõi Zen3 là sự kế thừa của bộ vi xử lý máy chủ thế hệ thứ hai hiệu suất cao của AMD (kiến trúc có tên mã là ” Rome “). Nó hỗ trợ tới 64 lõi ở 280w TDP và 8 kênh bộ nhớ DDR4 với tốc độ lên tới 3200MT/s.
Ngành kiến trúc
Cũng như AMD Rome, mẫu Bộ xử lý 64 lõi của AMD Milan có 1 khuôn I/O và 8 khuôn tính toán (còn gọi là CCD hoặc Khuôn phức hợp lõi) – Các mẫu OPN 32 lõi có thể có 4 hoặc 8 khuôn tính toán. Bộ xử lý Milan đã nâng cấp Bộ nhớ đệm (bao gồm cả trình tải trước mới ở cả bộ nhớ đệm L1 và L2) và Băng thông bộ nhớ, dự kiến sẽ cải thiện hiệu suất của các ứng dụng yêu cầu băng thông bộ nhớ cao hơn.
Không giống như Napoli và Rome, cách sắp xếp các CCD của Milan đã thay đổi. Mỗi CCD hiện có tối đa 8 lõi với bộ nhớ đệm L3 32MB thống nhất, có thể giảm độ trễ truy cập bộ nhớ đệm trong các chiplet điện toán. Bộ xử lý Milan có thể hiển thị từng CCD dưới dạng nút nút NUMA bằng cách đặt tùy chọn “bộ đệm L3 dưới dạng Miền NUMA” (từ GUI iDRAC ) hoặc tùy chọn BIOS.ProcSettings.CcxAsNumaDomain (sử dụng CLI racadm ) thành “Đã bật”. Do đó, Bộ xử lý ổ cắm kép 64 lõi của Milan với 8 CCD trên mỗi Bộ xử lý sẽ hiển thị 16 miền NUMA trên mỗi hệ thống trong cài đặt này. Đây là biểu diễn hợp lý của sắp xếp Lõi với NUMA Nút trên mỗi ổ cắm = 4 và CCD là NUMA = Đã tắt.
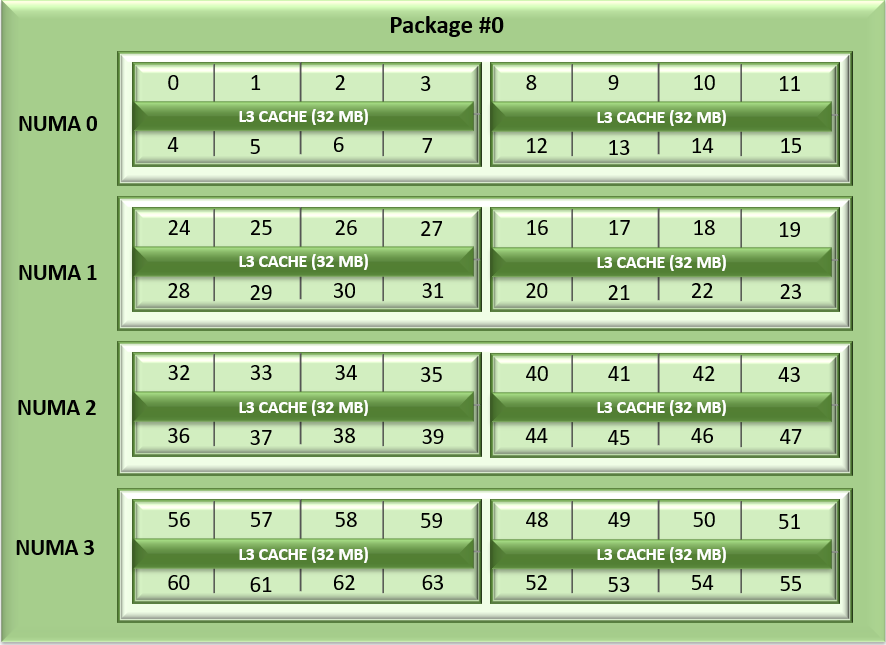
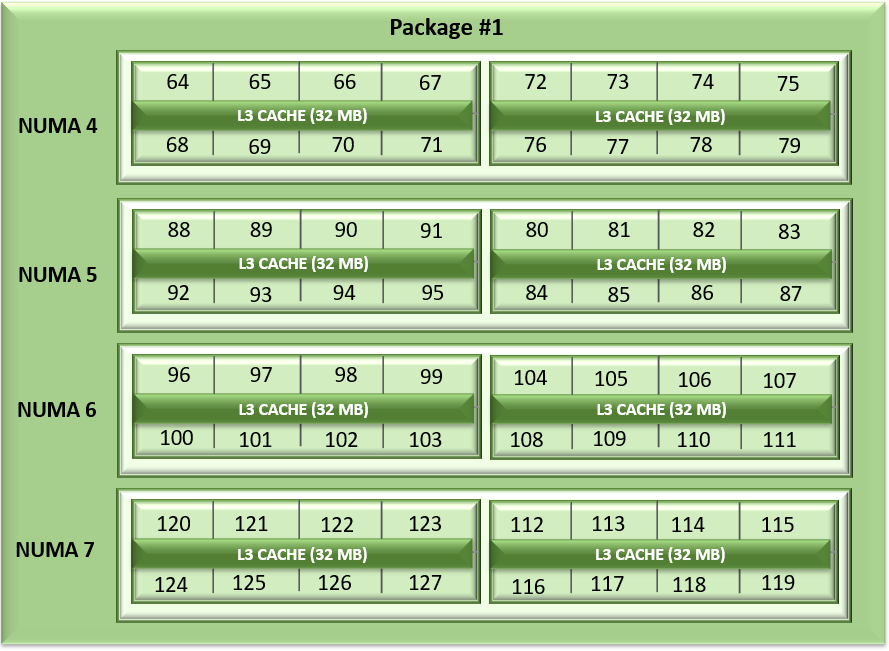
Hình 1: Liệt kê lõi tuyến tính trên hệ thống ổ cắm kép, 64c mỗi ổ cắm, cấu hình NPS4 trên mô hình Bộ xử lý 8 CCD
Như với AMD Rome, Bộ xử lý AMD Milan hỗ trợ tập lệnh AVX256 cho phép 16 DP FLOP/chu kỳ.
Tùy chọn BIOS khả dụng trên AMD Milan và Tuning
Bộ xử lý từ cả hai thế hệ Milan và Rome đều tương thích với ổ cắm, do đó, Tùy chọn BIOS giống nhau giữa các thế hệ Bộ xử lý này. Chi tiết máy chủ được đề cập trong Bảng 1 bên dưới.
Bảng 1: Chi tiết phần cứng và phần mềm thử nghiệm
| Người phục vụ | Máy chủ ổ cắm Dell EMC PowerEdge 2
(với Bộ xử lý AMD Milan) |
Máy chủ ổ cắm Dell EMC PowerEdge 2
(với Bộ xử lý AMD Rome) |
| mở
Lõi/ổ cắm Tần số (Base-Boost) TDP |
7763 (Milan)
64 2,45GHz – 3,5GHz 280W 256 MB |
7H12 (Rôma)
64 2.6GHz – 3.3GHz 280W 256 MB |
| mở
Lõi/ổ cắm Tính thường xuyên TDP |
7713 (Milan)
64 2.0GHz – 3.7GHz 225W 256 MB |
7702 (Rôma)
64 2,0 GHz – 3,35 GHz 200W 256 MB |
| mở
Lõi/ổ cắm Tính thường xuyên TDP |
7543 (Milan)
32 2,8GHz – 3,7GHz 225W 256 MB |
7542 (Rôma)
32 2.9GHz – 3.4GHz 225W 128 MB |
| Hệ điều hành | RHEL 8.3 (4.18.0-240.el8.x86_64) | RHEL 8.2 (4.18.0-193.el8.x86_64) |
| Kỉ niệm | DDR4 256G (16Gb x 16) 3200 tấn/giây | |
| BIOS / CPLD | 2.0.3/1.1.12 | 1.1.7 |
| kết nối | Mellanox HDR 200 (4X HDR) | Mellanox HDR100 |
Các tùy chọn BIOS sau đã được khám phá –
- BIOS.SysProfileSettings.SysProfile: Trường này đặt Cấu hình Hệ thống thành Chế độ Hiệu suất trên Watt (OS), Hiệu suất hoặc Chế độ tùy chỉnh. Khi được đặt ở một chế độ khác với Chế độ tùy chỉnh, BIOS sẽ đặt từng tùy chọn tương ứng. Khi được đặt thành Tùy chỉnh, bạn có thể thay đổi cài đặt của từng tùy chọn. Trong Chế độ tùy chỉnh khi trạng thái C được bật, Màn hình/Mwait cũng sẽ được bật.
- BIOS.ProcSettings.L1StridePrefetcher: Khi được đặt thành Đã bật, Bộ xử lý cung cấp tính năng tìm nạp bổ sung cho quyền truy cập dữ liệu cho một lệnh riêng lẻ để điều chỉnh hiệu suất bằng cách kiểm soát cài đặt trình tải trước sải chân L1.
- BIOS.ProcSettings.L2StreamHwPrefetcher: Khi được đặt thành Đã bật, Bộ xử lý cung cấp khả năng điều chỉnh hiệu suất nâng cao bằng cách kiểm soát cài đặt trình tải trước HW luồng L2.
- BIOS.ProcSettings.L2UpDownPrefetcher: Khi được đặt thành Đã bật, Bộ xử lý sử dụng quyền truy cập bộ nhớ để xác định nên tìm nạp tiếp theo hay trước đó cho tất cả các lần truy cập bộ nhớ để điều chỉnh hiệu suất nâng cao bằng cách kiểm soát cài đặt trình tải trước lên/xuống L2.
- BIOS.ProcSettings.CcxAsNumaDomain: Trường này chỉ định rằng mỗi CCD trong Bộ xử lý sẽ được khai báo là Miền NUMA.
- BIOS.MemSettings.MemoryInterleaving: Khi được đặt thành Tự động, tính năng xen kẽ bộ nhớ được hỗ trợ nếu cấu hình bộ nhớ đối xứng được cài đặt. Khi được đặt thành Tắt, hệ thống hỗ trợ các cấu hình bộ nhớ Truy cập bộ nhớ không đồng nhất (NUMA) (không đối xứng). Hệ điều hành nhận biết NUMA hiểu được sự phân bổ bộ nhớ trong một hệ thống cụ thể và có thể phân bổ bộ nhớ một cách thông minh theo cách tối ưu. Hệ điều hành không nhận biết NUMA có thể phân bổ bộ nhớ cho Bộ xử lý không cục bộ, dẫn đến mất hiệu suất. Chỉ nên kích hoạt xen kẽ khuôn và ổ cắm cho Hệ điều hành không nhận biết NUMA.
Sau khi đặt Cấu hình hệ thống ( BIOS.SysProfileSettings.SysProfile ) thành PerformanceOptimized, NUMA Nodes Per Socket (NPS) thành 4 và Trình tải trước (L1Region,L1Stream,L1Stride,L2Stream, L2UpDown) thành “Đã bật”, chúng tôi đã đo lường tác động của CcxAsNumaDomain và MemoryInterleaving BIOS thông số về hiệu suất ứng dụng. Chúng tôi đã kiểm tra hiệu suất của các ứng dụng được liệt kê trong Bảng 1 với các cài đặt sau.
Bảng 2: Sự kết hợp của CCX dưới dạng miền NUMA và Xen kẽ bộ nhớ
| CCX dưới dạng tên miền NUMA | xen kẽ bộ nhớ | |
| Cài đặt01 | Vô hiệu hóa | Vô hiệu hóa |
| Cài đặt02 | Vô hiệu hóa | Tự động |
| Cài đặt03 | Đã bật | Tự động |
| Cài đặt04 | Đã bật | Vô hiệu hóa |
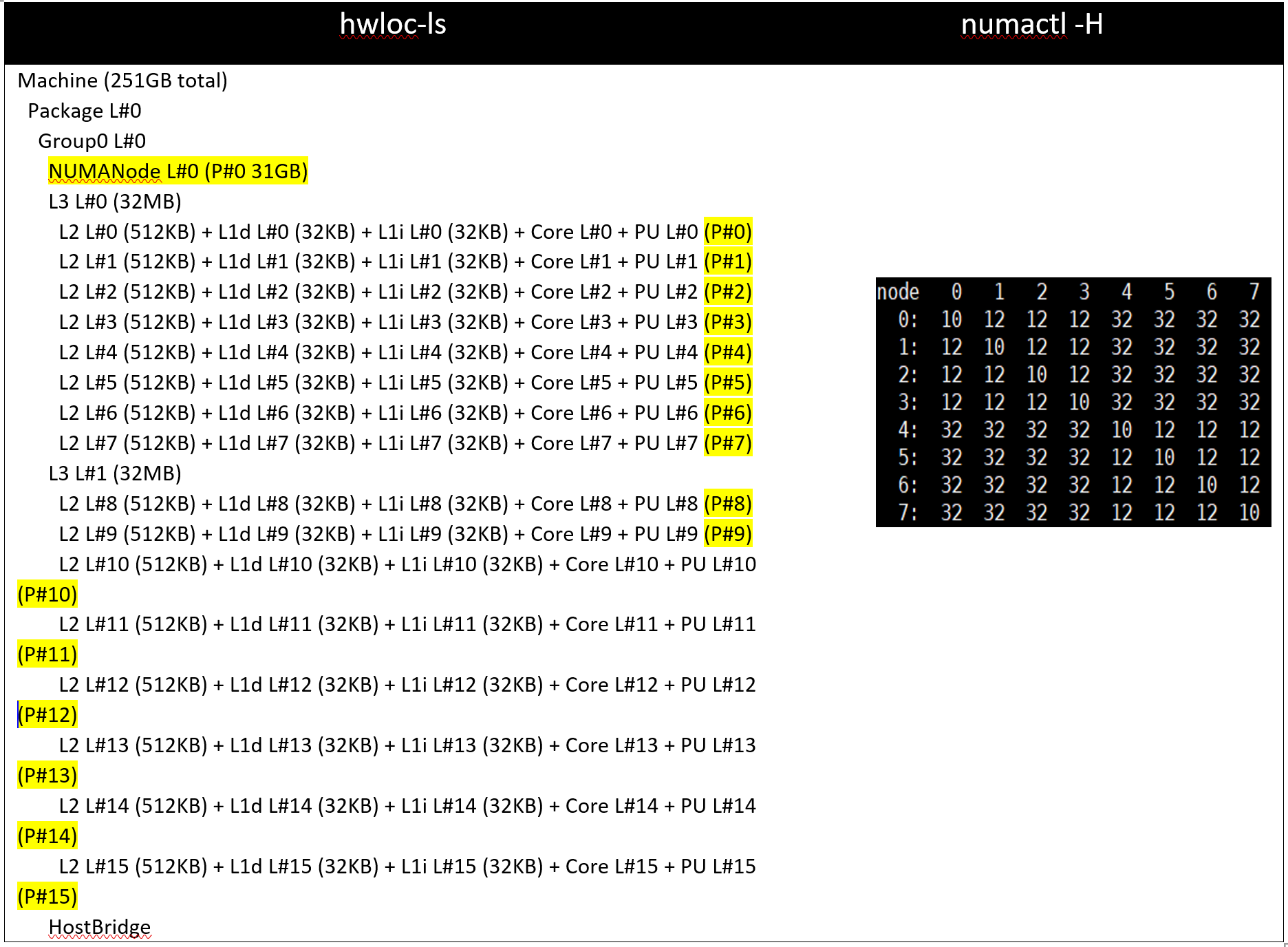
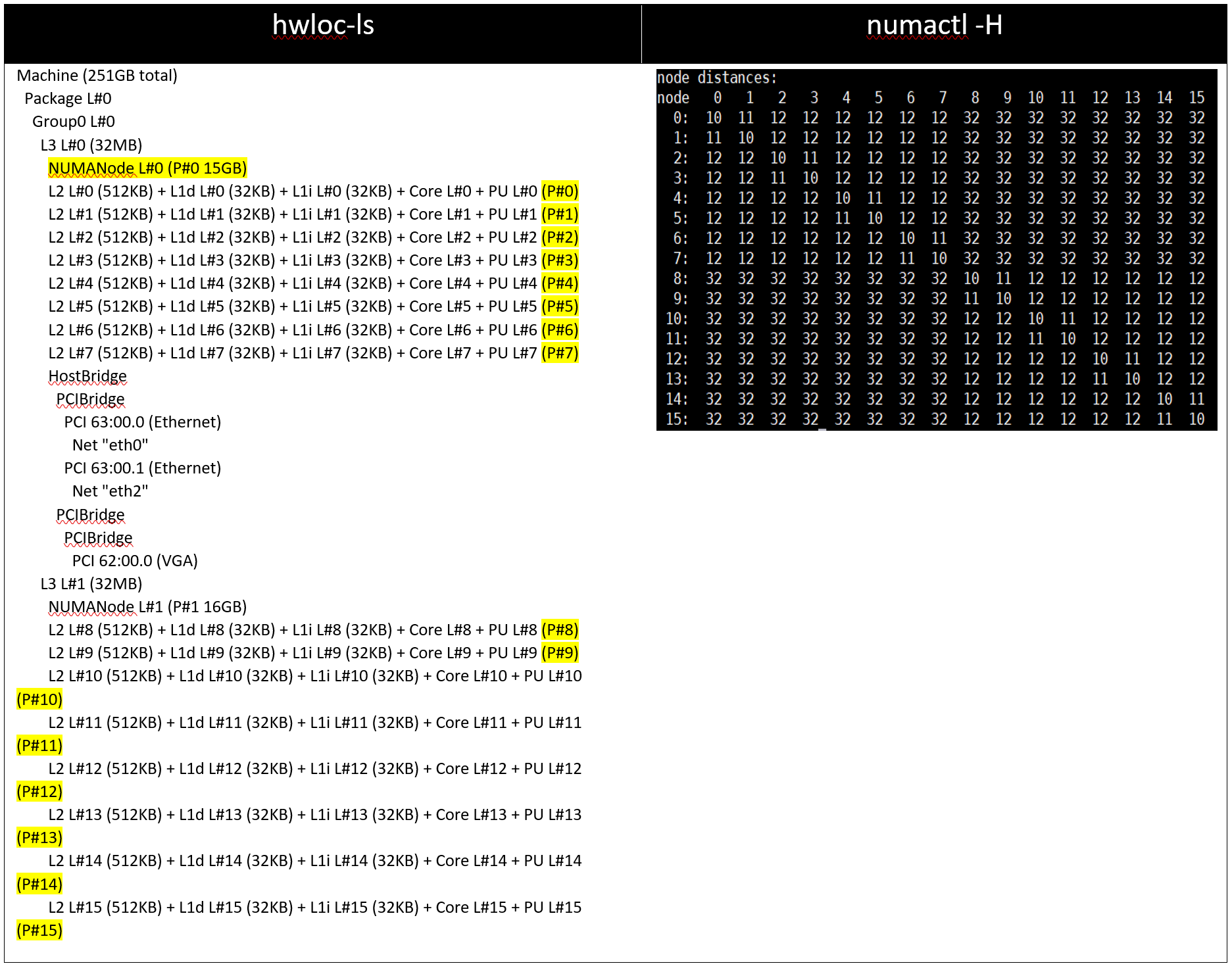
Với Cài đặt01 và Cài đặt02 (CCX là Tên miền NUMA = Đã tắt), hệ thống sẽ hiển thị 8 nút NUMA. Với Setting03 và Setting04, sẽ có 16 nút NUMA trên máy chủ ổ cắm kép với 64 Bộ xử lý Milan dựa trên lõi.
Bảng 3: đầu ra lệnh hwloc-ls và numactl -H trên máy chủ 64c với setting01/setting02 và (được liệt kê trong Bảng 2)
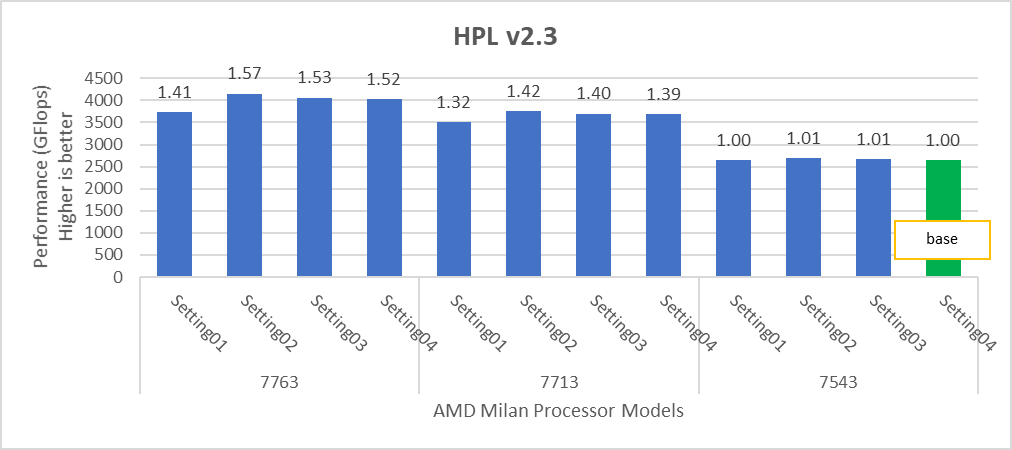
Hình 2: Sự khác biệt tương đối về hiệu suất của HPL theo cài đặt bộ xử lý và BIOS được đề cập trong Bảng 1 và Bảng 2.
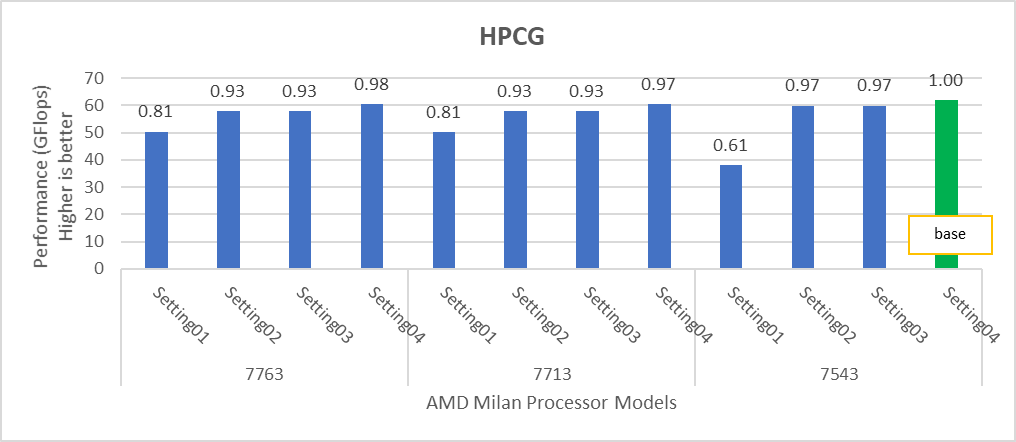
Hình 3: Sự khác biệt tương đối về hiệu suất của HPCG theo cài đặt bộ xử lý và BIOS được đề cập trong Bảng 1 và Bảng 2.
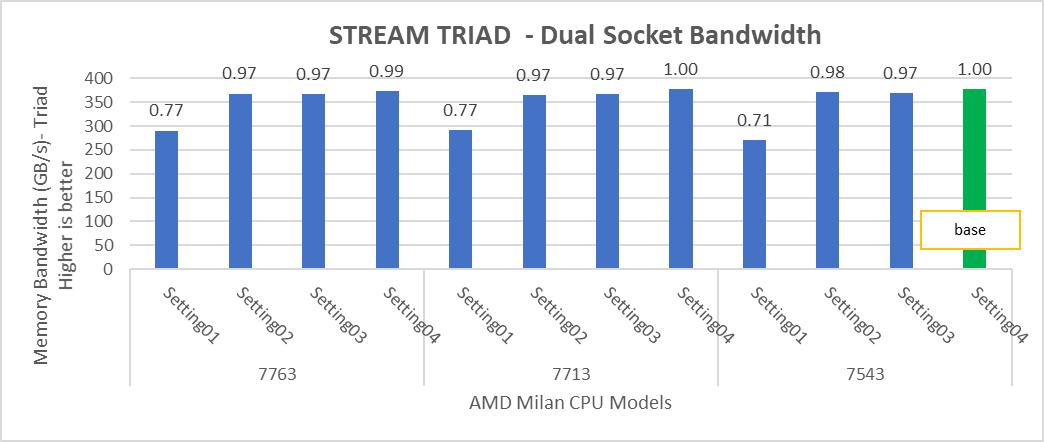
Hình 4: Sự khác biệt tương đối về hiệu suất của STREAM theo bộ xử lý và cài đặt BIOS được đề cập trong Bảng 1 và Bảng 2.
HPL mang lại các con số hiệu suất tốt nhất trên cài đặt02 với hiệu suất 82-93% tùy thuộc vào Kiểu bộ xử lý, trong khi STREAM và HPCG mang lại hiệu suất tốt hơn với cài đặt04.
Các thử nghiệm STREAM TRIAD tạo ra các con số hiệu suất tốt nhất ở băng thông bộ nhớ ~378 GB/giây trên tất cả các Mô hình bộ xử lý 64 và 32 lõi được đề cập trong Bảng 1 với hiệu suất lên tới 90%.
Trong Hình 4, số hiệu suất STREAM TRIAD được đo bằng cách đăng ký dưới mức máy chủ bằng cách chỉ sử dụng 16 lõi trên máy chủ. Việc so sánh các con số hiệu suất bằng cách sử dụng tất cả các lõi có sẵn và 16 lõi cho mỗi hệ thống đã được hiển thị trong Hình 5. Các con số trên đầu các thanh màu cam cho thấy sự khác biệt tương đối.
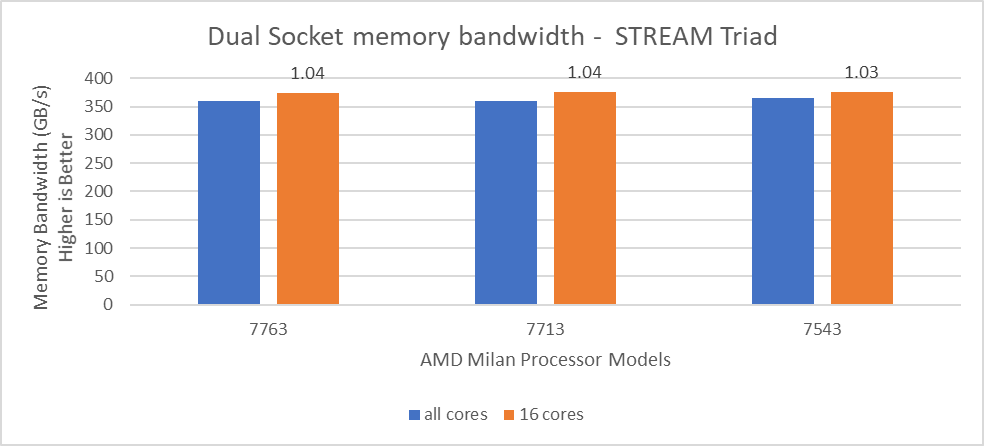
Hình 5: Sự khác biệt tương đối về băng thông bộ nhớ.
Từ Hình 5, chúng tôi quan sát thấy rằng bằng cách sử dụng 16 lõi, số hiệu suất của thử nghiệm STREAM TRIAD cao hơn khoảng 3-4% so với số hiệu suất được đo bằng cách đăng ký tất cả các lõi có sẵn.
Chúng tôi đã tiến hành kiểm tra băng thông NUMA bằng cách sử dụng cài đặt02 và cài đặt04 được đề cập trong Bảng01. Với cài đặt02, hệ thống hiển thị tổng cộng 8 nút NUMA trong khi với cài đặt04, hệ thống hiển thị tổng cộng 16 nút NUMA với 8 lõi trên mỗi nút NUMA. Trong Hình 6 và 7, nút NUMA được hiển thị là “c” và nút bộ nhớ là “m”. Ví dụ: c0m0 đại diện cho nút NUMA 0 và nút bộ nhớ 0. Số lượng băng thông tốt nhất thu được khi thay đổi số lượng luồng
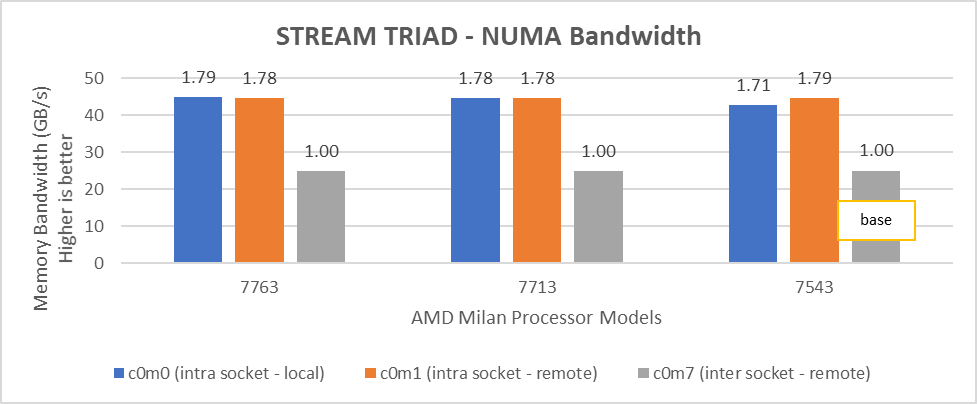
Hình 6: Băng thông bộ nhớ NUMA cục bộ và từ xa với CCXasNUMADomain=Disabled
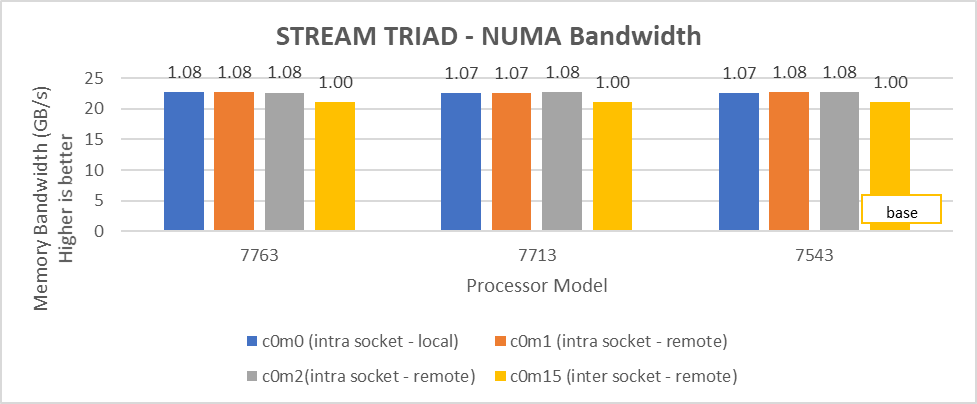
Hình 7: Băng thông bộ nhớ NUMA cục bộ và từ xa với CCXasNUMADomain=ENabled
Chúng tôi quan sát thấy rằng số lượng băng thông bộ nhớ cục bộ trong ổ cắm tối ưu thu được với 2 luồng trên mỗi nút NUMA với cài đặt2 trên cả hai mẫu bộ xử lý 64 lõi và 32 lõi. Trong Hình 6 với cài đặt02 (Bảng 2), băng thông bộ nhớ cục bộ trong ổ cắm, ở 2 luồng trên mỗi nút NUMA, có thể nhiều hơn tới 79% so với băng thông bộ nhớ từ xa. Với setting02 (Hình 6), chúng tôi nhận được ít nhất 96% băng thông bộ nhớ cục bộ trong ổ cắm trên mỗi miền NUMA so với setting04 (Hình 7).
Tác động của các tùy chọn Tìm nạp trước mới
Milan giới thiệu hai trình tải trước mới cho bộ đệm L1 và một cho Bộ đệm L2 với tổng cộng năm tùy chọn trình tải trước có thể được định cấu hình bằng BIOS. Chúng tôi đã thử nghiệm các kết hợp được liệt kê trong Bảng 5 bằng cách giữ cho trình tìm nạp trước L1 Stream và L2 Stream là Đã bật.
Bảng 5: Trình tải trước bộ đệm
| L1StrideTrình tải trước | Trình tải trước L1Vùng | L2UpDownTrình tìm nạp trước | |
| cài đặt01 | Vô hiệu hóa | Đã bật | Đã bật |
| cài đặt02 | Đã bật | Vô hiệu hóa | Đã bật |
| cài đặt03 | Đã bật | Đã bật | Vô hiệu hóa |
| cài đặt04 | Vô hiệu hóa | Vô hiệu hóa | Vô hiệu hóa |
Chúng tôi nhận thấy rằng những trình tìm nạp trước mới này không có tác động đáng kể đến hiệu suất của các điểm chuẩn tổng hợp được đề cập trong blog này.
Băng thông, tốc độ tin nhắn và khả năng mở rộng của InfiniBand
Đối với các thử nghiệm Đa nút, giường thử nghiệm được định cấu hình với kết nối Mellanox HDR chạy ở tốc độ 200 Gbps với mỗi máy chủ có Kiểu bộ xử lý AMD 7713 và cài đặt IO ưa thích được đặt thành Đã bật từ BIOS. Cùng với cài đặt02 (Bảng 2) và Trình tải trước (L1Region, L1Stream, L1Stride,L2Stream, L2UpDown) được đặt thành “Đã bật”, chúng tôi có thể đạt được khả năng mở rộng hiệu suất tuyến tính dự kiến cho Điểm chuẩn HPL và HPCG.
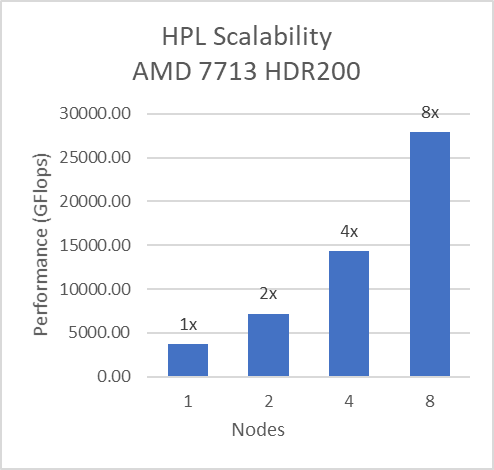
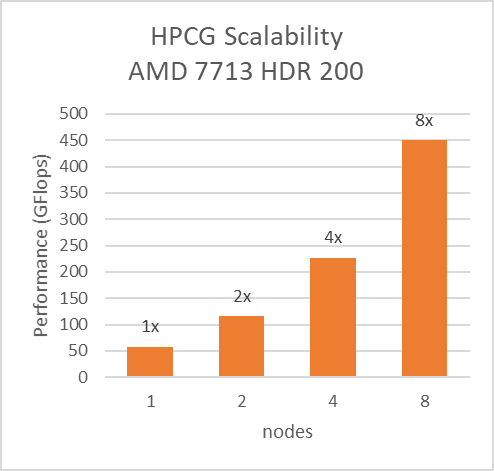
Hình 8: Khả năng mở rộng đa nút của HPL và HPCG với cài đặt02 (Bảng 2) với mẫu Bộ xử lý 7713, HDR200 Infiniband
Chúng tôi đã kiểm tra tốc độ tin nhắn, băng thông một chiều và hai chiều InfiniBand bằng cách sử dụng Điểm chuẩn OSU và kết quả nằm trong Hình 9, Hình 10 và Hình 11. Ngoại trừ cài đặt Nút Numa trên mỗi ổ cắm, tất cả các cài đặt BIOS khác cho các kiểm tra này đều giống như đã đề cập ở trên. Các thử nghiệm OSU Băng thông hai chiều và OSU Đơn hướng được thực hiện với Nút Numa trên mỗi ổ cắm được đặt thành 2 và thử nghiệm Tốc độ tin nhắn được thực hiện với Nút Numa trên mỗi ổ cắm được đặt thành 4. Trong Hình 9 và Hình 10, các số ở trên cùng của màu cam các thanh biểu thị phần trăm chênh lệch giữa số hiệu suất băng thông Cục bộ và Từ xa.
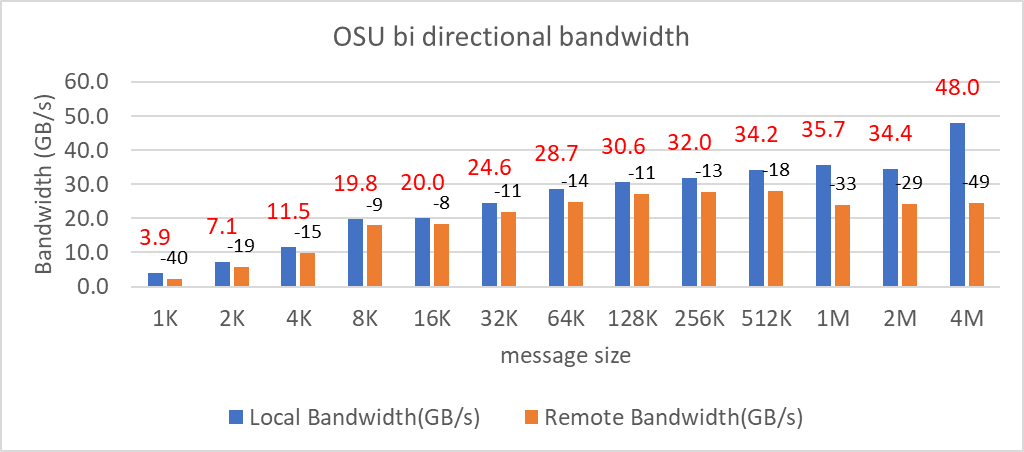
Hình 9: Kiểm tra băng thông hai chiều OSU trên AMD 7713, HDR 200 InfiniBand
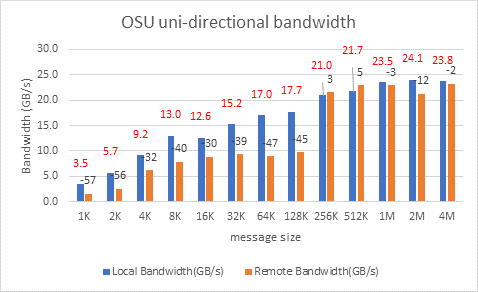 Hình 10: Kiểm tra băng thông một chiều OSU trên AMD 7713, HDR 200 Infiniband
Hình 10: Kiểm tra băng thông một chiều OSU trên AMD 7713, HDR 200 Infiniband
Đối với các số hiệu suất Độ trễ cục bộ và Băng thông, quy trình MPI được ghim vào nút NUMA 1 (gần HCA nhất). Đối với các bài kiểm tra Độ trễ và Băng thông từ xa, các quy trình đã được ghim vào nút NUMA 6.
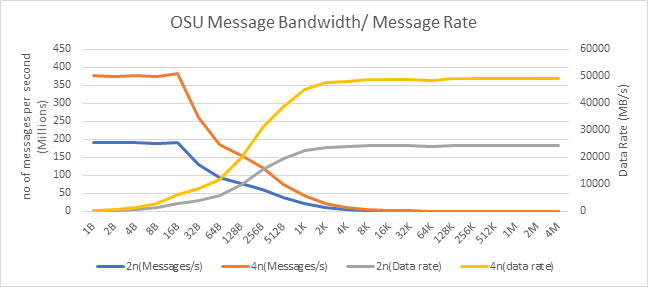
Hình 11: Tốc độ tin nhắn OSU và hiệu suất băng thông trên 2 và 4 nút của mô hình Bộ xử lý 7713
Trên 2 nút sử dụng HDR200, chúng tôi có thể đạt được băng thông đơn hướng ~24 GB/giây và tốc độ gửi tin nhắn là 192 Triệu tin nhắn/giây – gần gấp đôi con số hiệu suất đạt được trên HDR100 .
So sánh với Rome SKU
Để đưa ra các so sánh cải thiện hiệu suất, chúng tôi đã chọn các SKU Rome gần nhất với các đối tác Milan của họ về các tính năng phần cứng như Kích thước bộ đệm, giá trị TDP và Tần số cơ sở/Turbo của bộ xử lý.
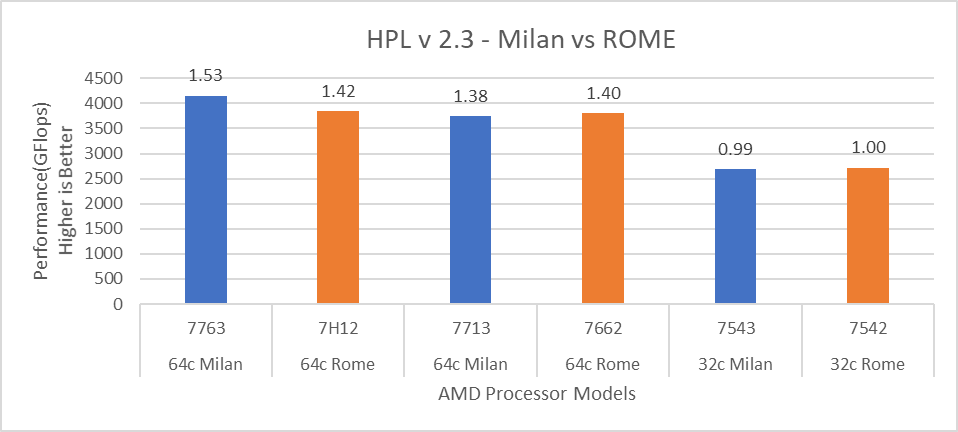
Hình 12: So sánh hiệu suất HPL với các Mô hình Bộ xử lý Rome
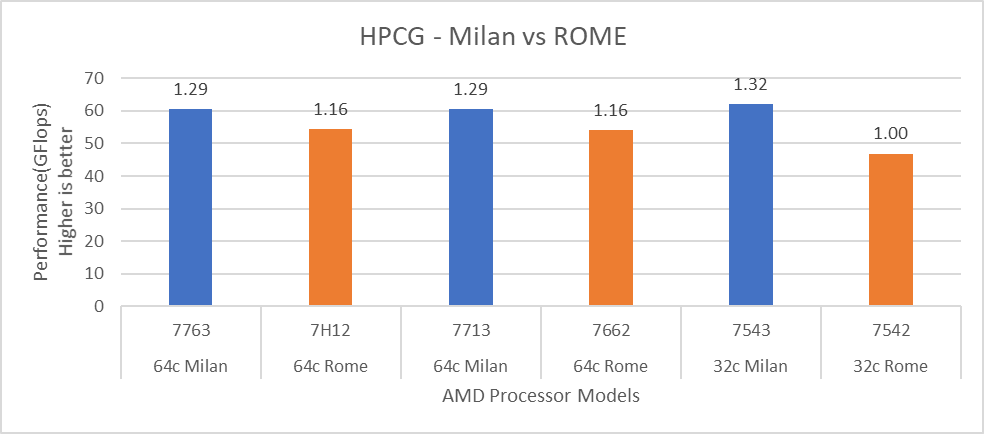
Hình 13: So sánh hiệu suất HPCG với các Mô hình Bộ xử lý Rome
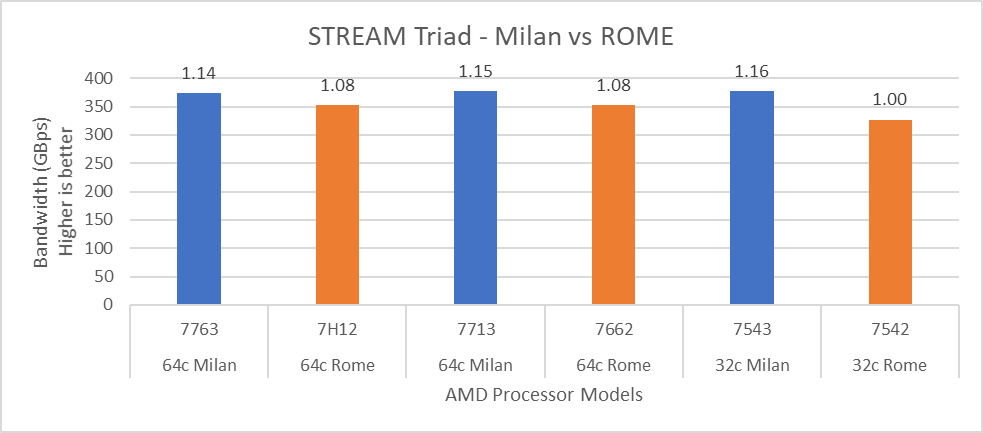
Hình 14: So sánh hiệu suất STREAM với các Mô hình Bộ xử lý Rome
Đối với HPL (Hình 12), chúng tôi quan sát thấy rằng, trên các Mẫu bộ xử lý cao cấp hơn, Milan mang lại hiệu suất tốt hơn 10% so với Rome. Đúng như mong đợi, trên nền tảng Milan, các ứng dụng giới hạn băng thông bộ nhớ như STREAM và HPCG (Hình 13 và Hình 14) đạt hiệu suất lần lượt là 6-16 % và 13-32% so với các Mô hình bộ xử lý Rome được đề cập trong blog này.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...