
Giới thiệu
Gần đây, Meta đã cung cấp nguồn mở cho các mô hình chuyển văn bản thành văn bản Meta Llama 3 với kích thước 8B và 70B, đây là những LLM có điểm số cao nhất cho đến nay về phạm vi kích thước của chúng, xét về chất lượng phản hồi [1 ] . Trong blog này, chúng tôi sẽ chạy các mô hình đó trên máy chủ Dell PowerEdge XE9680 để thể hiện hiệu suất và sự cải tiến của chúng bằng cách so sánh chúng với các mô hình Llama 2.
Việc cung cấp nguồn mở cho các Mô hình ngôn ngữ lớn (LLM) cho phép dễ dàng truy cập vào công nghệ tiên tiến này và đã thúc đẩy các đổi mới trong lĩnh vực này cũng như việc áp dụng cho các ứng dụng khác nhau. Như được hiển thị trong Bảng 1, đợt phát hành Llama 3 này bao gồm tổng cộng năm mô hình sau, bao gồm hai mô hình được đào tạo trước với kích thước 8B và 70B và các phiên bản được điều chỉnh theo hướng dẫn của chúng, cùng với phiên bản bảo vệ cho mô hình 8B [2] .
Bảng 1: Các mẫu Llama 3 đã được phát hành
| Kích thước mô hình (Thông số) | Tên mẫu | Độ dài ngữ cảnh |
Mã thông báo đào tạo | Độ dài từ vựng |
| 8B |
|
8K |
15T |
128K |
| 70B |
|
Llama 3 được đào tạo trên 15 nghìn tỷ mã thông báo, gấp 7,5 lần số lượng mã thông báo mà Llama 2 đã được đào tạo. Việc đào tạo với các bộ dữ liệu lớn, chất lượng cao và các quy trình sau đào tạo được tinh chỉnh đã cải thiện các khả năng của mô hình Llama 3, chẳng hạn như lý luận, tạo mã và làm theo hướng dẫn. Được đánh giá dựa trên các điểm chuẩn về độ chính xác chính, mô hình Llama 3 không chỉ vượt xa tiền lệ mà còn dẫn đầu so với các mô hình nguồn mở chính khác với tỷ suất lợi nhuận đáng kể. Mô hình hướng dẫn Llama 3 70B cho kết quả gần bằng hoặc thậm chí tốt hơn so với các mô hình nguồn đóng thương mại như Gemini Pro[1].
Kiến trúc mô hình của Llama 3 8B tương tự như của Llama 2 7B nhưng có một điểm khác biệt đáng kể. Bên cạnh kích thước tham số lớn hơn, mô hình Llama 3 8B sử dụng cơ chế chú ý truy vấn nhóm (GQA) thay vì cơ chế chú ý nhiều đầu (MHA) được sử dụng trong mô hình Llama 2 7B. Không giống như MHA có cùng số lượng ma trận Q (truy vấn), K (khóa) và V (giá trị), GQA giảm số lượng ma trận K và V được yêu cầu bằng cách chia sẻ cùng một ma trận KV trên các ma trận Q được nhóm. Điều này làm giảm bộ nhớ cần thiết và cải thiện hiệu quả tính toán trong quá trình suy luận [3] . Ngoài ra, các mô hình Llama 3 đã cải thiện độ dài cửa sổ ngữ cảnh tối đa lên 8192 so với 4096 của các mô hình Llama 2. Llama 3 sử dụng một mã thông báo mới có tên là mã thông báo tik giúp mở rộng kích thước từ vựng lên 128K khi so sánh với 32K được sử dụng trong Llama 2. Sơ đồ mã thông báo mới mang lại hiệu quả mã thông báo được cải thiện, mang lại số mã thông báo ít hơn tới 15% so với Llama 2 dựa trên điểm chuẩn của Meta[ 1].
Blog này tập trung vào các bài kiểm tra hiệu năng suy luận của các model Llama 3 chạy trên máy chủ Dell PowerEdge XE9680, đặc biệt là so sánh với các model Llama 2, để cho thấy những cải tiến của thế hệ model mới.
Thiết lập thử nghiệm
Máy chủ mà chúng tôi sử dụng để đánh giá hiệu năng là PowerEdge XE9680 với GPU H100 8x [4] . Cấu hình máy chủ chi tiết được thể hiện trong Bảng 2.
Bảng 2: Cấu hình máy chủ XE9680
| Tên hệ thống | PowerEdge XE9680 |
| Trạng thái | Có sẵn |
| Loại hệ thống | Trung tâm dữ liệu |
| Số nút | 1 |
| Mô hình bộ xử lý máy chủ | Bộ xử lý có khả năng mở rộng Intel® Xeon® thế hệ thứ 4 |
| Tên quy trình máy chủ | Intel® Xeon® Bạch Kim 8470 |
| Bộ xử lý máy chủ trên mỗi nút | 2 |
| Số lượng lõi của bộ xử lý máy chủ | 52 |
| Tần số bộ xử lý máy chủ | Tăng tốc Turbo 2,0 GHz, 3,8 GHz |
| Dung lượng và loại bộ nhớ máy chủ | DIMM 2TB, 32×64 GB, DDR5 4800 MT/s |
| Dung lượng lưu trữ máy chủ | 1,8 TB, NVME |
| Số và tên GPU | 8x H100 |
| Dung lượng và loại bộ nhớ GPU | 80GB, HBM3 |
| Giao diện tốc độ cao GPU | PCIe Gen5 / NVLink Gen4 |
XE9680 là máy chủ lý tưởng, được tối ưu hóa cho khối lượng công việc AI với GPU H100 kết nối NVSwitch 8x. Kết nối NVLink tốc độ cao cho phép triển khai các mô hình lớn như Llama 3 70B cần kết nối nhiều GPU để có hiệu suất tốt nhất và yêu cầu dung lượng bộ nhớ. Với 10 khe cắm PCIe, XE9680 cũng cung cấp kiến trúc PCIe linh hoạt cho phép nhiều tùy chọn kết cấu AI khác nhau.
Đối với các thử nghiệm này, chúng tôi đã triển khai các mô hình Llama 3 Meta-Llama-3-8B và Meta-Llama-3-70B cũng như các mô hình Llama 2 Llama-2-7b-hf và Llama-2-70b-hf. Những mô hình này có sẵn để tải xuống từ Ôm mặt sau khi được Meta phê duyệt. Để so sánh công bằng giữa các mô hình Llama 2 và Llama 3, chúng tôi đã chạy các mô hình với độ chính xác gốc (float16 cho mô hình Llama 2 và bfloat16 cho mô hình Llama 3) thay vì bất kỳ độ chính xác lượng tử hóa nào.
Vì nó có kiến trúc mô hình cơ bản giống như Llama 2, nên Llama 3 có thể dễ dàng được tích hợp vào bất kỳ hệ sinh thái phần mềm sẵn có nào hiện hỗ trợ mô hình Llama 2. Đối với các thử nghiệm trong blog này, chúng tôi đã chọn bản phát hành mới nhất của NVIDIA TensorRT-LLM (phiên bản 0.9.0) làm khung suy luận. Phiên bản NVIDIA CUDA là 12.4; phiên bản trình điều khiển là 550.54.15. Hệ điều hành cho thử nghiệm là Rocky Linux 9.1.
Biết rằng Llama 3 đã cải thiện độ chính xác đáng kể nên trước tiên chúng tôi tập trung vào các bài kiểm tra tốc độ suy luận. Cụ thể hơn, chúng tôi đã thử nghiệm Thời gian tạo mã thông báo đầu tiên (TTFT) và thông lượng trên các kích cỡ lô khác nhau cho cả hai mô hình Llama 2 và Llama 3, như được hiển thị trong phần Kết quả. Để làm cho việc so sánh giữa hai thế hệ mô hình trở nên dễ dàng và bắt chước nhiệm vụ tóm tắt, chúng tôi đã giữ độ dài mã thông báo đầu vào và độ dài mã thông báo đầu ra lần lượt là 2048 và 128 cho hầu hết các thử nghiệm. Chúng tôi cũng đã đo thông lượng của Llama 3 với độ dài mã thông báo đầu vào dài (8192), đây là một trong những cải tiến quan trọng nhất. Vì GPU H100 hỗ trợ định dạng dữ liệu fp8 cho các mô hình có độ chính xác không đáng kể nên chúng tôi đã đo thông lượng theo độ dài mã thông báo đầu vào dài cho mô hình Llama 3 ở độ chính xác fp8.
Kết quả
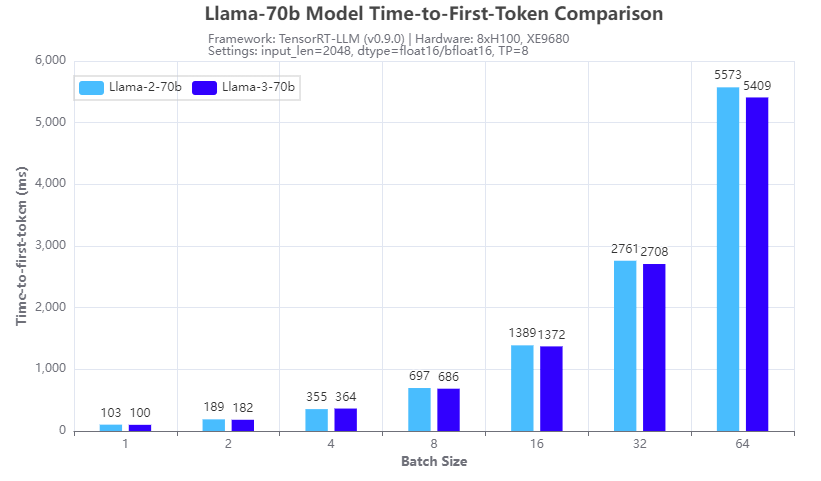
Hình 1. So sánh tốc độ suy luận: Llama-3-70b và Llama-2-70b: Thời gian đến mã thông báo đầu tiên
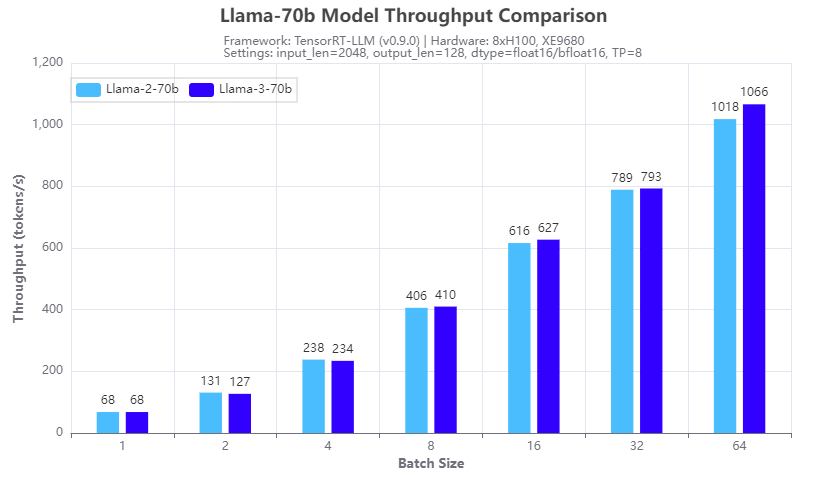
Hình 2: So sánh tốc độ suy luận: Llama-3-70b và Llama-2-70b: Thông lượng
Hình 1 và 2 cho thấy sự so sánh tốc độ suy luận với các mô hình 70b Llama 2 (Llama-2-70b) và Llama 3 (Llama-3-70b) chạy trên tám GPU H100 theo kiểu song song tensor (TP=8) trên XE9680 máy chủ. Từ kết quả thử nghiệm, chúng ta có thể thấy rằng đối với cả TTFT (Hình 1) và thông lượng (Hình 2), mô hình Llama 3 70B có tốc độ suy luận tương tự như mô hình Llama 2 70b. Điều này được mong đợi do có cùng kích thước và kiến trúc của hai mô hình. Vì vậy, bằng cách triển khai Llama 3 thay vì Llama 2 trên XE9680, các tổ chức có thể thấy ngay sự cải thiện đáng kể về độ chính xác và chất lượng của phản hồi, sử dụng cùng một cơ sở hạ tầng phần mềm mà không có bất kỳ tác động nào đến độ trễ hoặc thông lượng của phản hồi.
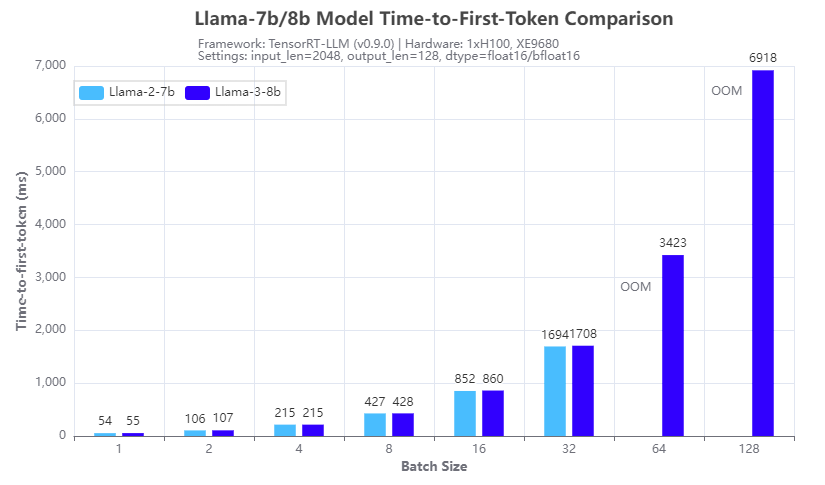
Hình 3. So sánh tốc độ suy luận: Llama-3-8b và Llama-2-7b: Thời gian đến mã thông báo đầu tiên
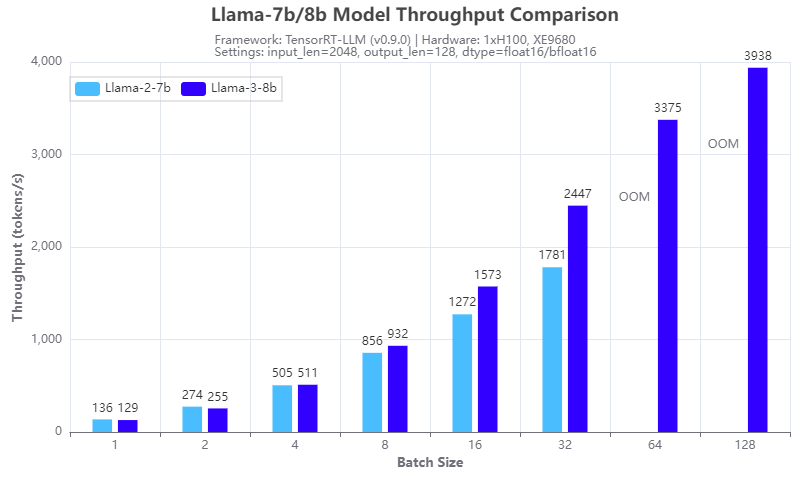
Hình 4: So sánh tốc độ suy luận: Llama-3-8b và Llama-2-7b: Thông lượng
Hình 3 và 4 cho thấy sự so sánh tốc độ suy luận với các mô hình 7b Llama 2 (Llama-2-7b) và 8b Llama 3 (Llama-3-8b) chạy trên một GPU H100 duy nhất trên máy chủ XE9680. Từ kết quả, chúng ta có thể thấy lợi ích của việc sử dụng chú ý truy vấn nhóm (GQA) trong kiến trúc Llama 3 8B, về mặt giảm dung lượng bộ nhớ GPU trong giai đoạn điền trước và tăng tốc tính toán trong giai đoạn giải mã của suy luận LLM . Hình 3 cho thấy Llama 3 8B có thời gian phản hồi tương tự khi tạo mã thông báo đầu tiên mặc dù đây là mô hình lớn hơn 15% so với Llama-2-7b. Hình 4 cho thấy Llama-3-8b có thông lượng cao hơn Llama-2-7b khi kích thước lô từ 4 trở lên. Lợi ích của GQA tăng lên khi quy mô lô tăng lên. Qua thí nghiệm chúng ta có thể thấy rằng:
- Llama-2-7b không thể chạy ở kích thước lô 64 hoặc lớn hơn với độ chính xác 16 bit và độ dài mã thông báo đầu vào/đầu ra nhất định do lỗi OOM (hết bộ nhớ)
- Llama-3-8b có thể chạy ở kích thước lô 128, mang lại thông lượng gấp hơn 2 lần với cùng cấu hình phần cứng
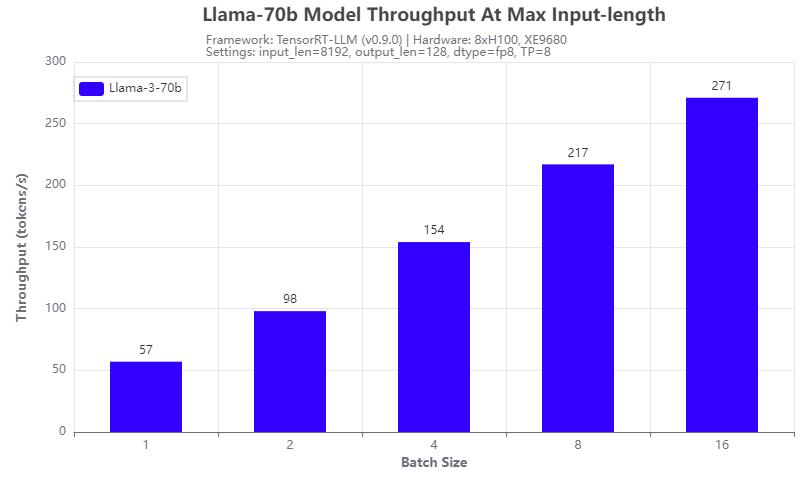
Hình 5: Thông lượng Llama-3-70b dưới độ dài mã thông báo đầu vào 8192
Một cải tiến khác của mô hình Llama 3: nó hỗ trợ độ dài mã thông báo đầu vào tối đa là 8192, gấp 2 lần so với mô hình Llama 2. Chúng tôi đã thử nghiệm nó với mẫu Llama-3-70b chạy trên 8 GPU H100 của máy chủ XE9680. Kết quả được hiển thị trong Hình 5. Thông lượng tỷ lệ tuyến tính với kích thước lô được thử nghiệm và có thể đạt được 271 mã thông báo/giây ở kích thước lô 16, cho thấy các kỹ thuật lượng tử hóa tích cực hơn có thể cải thiện thông lượng hơn nữa.
Phần kết luận
Trong blog này, chúng tôi đã nghiên cứu các mẫu Llama 3 được phát hành gần đây bằng cách so sánh tốc độ suy luận của chúng với tốc độ suy luận của các mẫu Llama 2 chạy trên máy chủ Dell PowerEdge XE9680. Với những con số thu thập được qua thử nghiệm, chúng tôi đã cho thấy rằng dòng mô hình Llama 3 không chỉ là một bước nhảy vọt lớn về chất lượng phản hồi mà còn có lợi thế suy luận lớn về thông lượng cao với kích thước lô lớn có thể đạt được và thời gian đầu vào dài. chiều dài mã thông báo. Điều này làm cho mô hình Llama 3 trở thành ứng cử viên tuyệt vời cho các ứng dụng xử lý ngoại tuyến và ngữ cảnh dài.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...