
Giới thiệu
Trước khi vào blog này, tôi muốn dành một phút để cảm ơn Fabricio Bronzati vì sự trợ giúp kỹ thuật của anh ấy về chủ đề này.
Trong vài năm qua, Ôm Mặt đã trở thành nền tảng tiêu chuẩn trên thực tế để lưu trữ mọi thứ liên quan đến AI. Từ mô hình, tập dữ liệu đến tác nhân, tất cả đều có trên Ôm Mặt.
Trong khi card đồ họa NVIDIA là lựa chọn phổ biến để hỗ trợ khối lượng công việc AI, NVIDIA đã đầu tư đáng kể vào việc xây dựng hệ thống phần mềm của họ để giúp khách hàng giảm thời gian tiếp thị các ứng dụng hỗ trợ AI tổng hợp của họ. Đây là lúc mà ngăn xếp phần mềm NVIDIA AI Enterprise phát huy tác dụng. 2 thành phần lớn của ngăn xếp NVIDIA AI Enterprise là khung NeMo và máy chủ Triton Inference.
NeMo giúp việc tạo LLM và bắt đầu tương tác với nó thực sự dễ dàng. Nhược điểm được nhận thấy của NeMo là nó chỉ hỗ trợ một số lượng nhỏ LLM vì nó yêu cầu LLM phải ở định dạng cụ thể. Đối với những người muốn chạy LLM không được NeMo hỗ trợ, NVIDIA cung cấp một bộ tập lệnh và bộ chứa để chuyển đổi LLM từ định dạng Ôm mặt sang TensorRT, là khung cơ bản cho NeMo và máy chủ Triton Inference. Theo trang web của NVIDIA, được tìm thấy ở đây , TensorRT-LLM là một thư viện mã nguồn mở giúp tăng tốc và tối ưu hóa hiệu suất suy luận của các mô hình ngôn ngữ lớn (LLM) mới nhất trên nền tảng NVIDIA AI.
Thách thức với TensorRT-LLM là người ta không thể lấy mô hình từ Ôm mặt và chạy trực tiếp trên TensorRT-LLM. Một mô hình như vậy sẽ cần phải trải qua giai đoạn chuyển đổi và sau đó nó có thể tận dụng tất cả những ưu điểm của TensorRT-LLM.
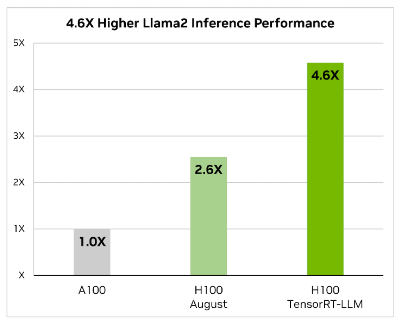
Khi nói đến việc tối ưu hóa các mô hình ngôn ngữ lớn, TensorRT-LLM chính là chìa khóa. Nó đảm bảo rằng các mô hình không chỉ mang lại hiệu suất cao mà còn duy trì hiệu quả trong các ứng dụng khác nhau.
Thư viện bao gồm các hạt nhân được tối ưu hóa, các bước xử lý trước và sau cũng như các nguyên tắc giao tiếp đa GPU/đa nút. Những tính năng này được thiết kế đặc biệt để nâng cao hiệu suất trên GPU NVIDIA.
Mục đích của blog này là trình bày các bước cần thiết để lấy mô hình trên Ôm Mặt và chuyển đổi nó sang TensorRT-LLM. Khi một mô hình đã được chuyển đổi, nó có thể được sử dụng bởi máy chủ Triton Inference. TensorRT-LLM không hỗ trợ tất cả các mô hình trên Ôm mặt, vì vậy trước khi thử chuyển đổi, tôi sẽ kiểm tra danh sách các mô hình được hỗ trợ ngày càng tăng trên trang github TensorRT-LLM .
Điều kiện tiên quyết
Trước khi đi sâu vào chuyển đổi, hãy nói ngắn gọn về các điều kiện tiên quyết. Có rất nhiều bước trong docker đòn bẩy chuyển đổi, vì vậy bạn cần: docker-composevà docker-buildx. Bạn cũng sẽ nhân bản các kho lưu trữ, vì vậy bạn cần git. Một thành phần trong gitđó là bắt buộc và không phải lúc nào cũng được cài đặt theo mặc định là hỗ trợ Lưu trữ tệp lớn. Vì vậy, bạn cần đảm bảo rằng nó git-lfsđã được cài đặt, vì chúng ta sẽ cần sao chép các tệp khá lớn (ở kích thước nhiều GB) từ git, và sử dụng git-lfslà cách hiệu quả nhất để thực hiện việc đó.
Xây dựng thư viện TensorRT LLM
Tại thời điểm viết blog này, NVIDIA vẫn chưa phát hành bộ chứa dựng sẵn với thư viện TensorRT LLM, vì vậy thật không may, điều đó có nghĩa là bất kỳ ai muốn sử dụng nó đều có trách nhiệm phải làm như vậy. Vì vậy, hãy để tôi chỉ cho bạn cách làm điều đó.
Điều đầu tiên tôi cần làm là sao chép kho thư viện TensorRT LLM:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://github.com/NVIDIA/TensorRT-LLM.git
Cloning into 'TensorRT-LLM'...
remote: Enumerating objects: 7888, done.
remote: Counting objects: 100% (1696/1696), done.
remote: Compressing objects: 100% (626/626), done.
remote: Total 7888 (delta 1145), reused 1413 (delta 1061), pack-reused 6192
Receiving objects: 100% (7888/7888), 81.67 MiB | 19.02 MiB/s, done.
Resolving deltas: 100% (5368/5368), done.
Updating files: 100% (1661/1661), done.
Sau đó, tôi cần khởi tạo tất cả các mô-đun con có trong kho lưu trữ:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git submodule update --init --recursive
Submodule '3rdparty/NVTX' (https://github.com/NVIDIA/NVTX.git) registered for path '3rdparty/NVTX'
Submodule '3rdparty/cutlass' (https://github.com/NVIDIA/cutlass.git) registered for path '3rdparty/cutlass'
Submodule '3rdparty/cxxopts' (https://github.com/jarro2783/cxxopts) registered for path '3rdparty/cxxopts'
Submodule '3rdparty/json' (https://github.com/nlohmann/json.git) registered for path '3rdparty/json'
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/NVTX'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/cutlass'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/cxxopts'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/json'...
Submodule path '3rdparty/NVTX': checked out 'a1ceb0677f67371ed29a2b1c022794f077db5fe7'
Submodule path '3rdparty/cutlass': checked out '39c6a83f231d6db2bc6b9c251e7add77d68cbfb4'
Submodule path '3rdparty/cxxopts': checked out 'eb787304d67ec22f7c3a184ee8b4c481d04357fd'
Submodule path '3rdparty/json': checked out 'bc889afb4c5bf1c0d8ee29ef35eaaf4c8bef8a5d'
và sau đó tôi cần khởi tạo git lfsvà kéo các đối tượng được lưu trữ trong git lfs:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git lfs install
Updated git hooks.
Git LFS initialized.
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git lfs pull
Tại thời điểm này, tôi đã sẵn sàng xây dựng bộ chứa docker chứa thư viện TensorRT LLM:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ make -C docker release_build
make: Entering directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'
Building docker image: tensorrt_llm/release:latest
DOCKER_BUILDKIT=1 docker build --pull \
--progress auto \
--build-arg BASE_IMAGE=nvcr.io/nvidia/pytorch \
--build-arg BASE_TAG=23.12-py3 \
--build-arg BUILD_WHEEL_ARGS="--clean --trt_root /usr/local/tensorrt --python_bindings --benchmarks" \
--build-arg TORCH_INSTALL_TYPE="skip" \
--build-arg TRT_LLM_VER="0.8.0.dev20240123" \
--build-arg GIT_COMMIT="b57221b764bc579cbb2490154916a871f620e2c4" \
--target release \
--file Dockerfile.multi \
--tag tensorrt_llm/release:latest \
[+] Building 2533.0s (41/41) FINISHED docker:default
=> [internal] load build definition from Dockerfile.multi 0.0s
=> => transferring dockerfile: 3.24kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 359B 0.0s
=> [internal] load metadata for nvcr.io/nvidia/pytorch:23.12-py3 1.0s
=> [auth] nvidia/pytorch:pull,push token for nvcr.io 0.0s
=> [internal] load build context 44.1s
=> => transferring context: 579.18MB 44.1s
=> CACHED [base 1/1] FROM nvcr.io/nvidia/pytorch:23.12-py3@sha256:da3d1b690b9dca1fbf9beb3506120a63479e0cf1dc69c9256055125460eb44f7 0.0s
=> [devel 1/14] COPY docker/common/install_base.sh install_base.sh 1.1s
=> [devel 2/14] RUN bash ./install_base.sh && rm install_base.sh 13.7s
=> [devel 3/14] COPY docker/common/install_cmake.sh install_cmake.sh 0.0s
=> [devel 4/14] RUN bash ./install_cmake.sh && rm install_cmake.sh 23.0s
=> [devel 5/14] COPY docker/common/install_ccache.sh install_ccache.sh 0.0s
=> [devel 6/14] RUN bash ./install_ccache.sh && rm install_ccache.sh 0.5s
=> [devel 7/14] COPY docker/common/install_tensorrt.sh install_tensorrt.sh 0.0s
=> [devel 8/14] RUN bash ./install_tensorrt.sh --TRT_VER=${TRT_VER} --CUDA_VER=${CUDA_VER} --CUDNN_VER=${CUDNN_VER} --NCCL_VER=${NCCL_VER} --CUBLAS_VER=${CUBLAS_VER} && 448.3s
=> [devel 9/14] COPY docker/common/install_polygraphy.sh install_polygraphy.sh 0.0s
=> [devel 10/14] RUN bash ./install_polygraphy.sh && rm install_polygraphy.sh 3.3s
=> [devel 11/14] COPY docker/common/install_mpi4py.sh install_mpi4py.sh 0.0s
=> [devel 12/14] RUN bash ./install_mpi4py.sh && rm install_mpi4py.sh 42.2s
=> [devel 13/14] COPY docker/common/install_pytorch.sh install_pytorch.sh 0.0s
=> [devel 14/14] RUN bash ./install_pytorch.sh skip && rm install_pytorch.sh 0.4s
=> [wheel 1/9] WORKDIR /src/tensorrt_llm 0.0s
=> [release 1/11] WORKDIR /app/tensorrt_llm 0.0s
=> [wheel 2/9] COPY benchmarks benchmarks 0.0s
=> [wheel 3/9] COPY cpp cpp 1.2s
=> [wheel 4/9] COPY benchmarks benchmarks 0.0s
=> [wheel 5/9] COPY scripts scripts 0.0s
=> [wheel 6/9] COPY tensorrt_llm tensorrt_llm 0.0s
=> [wheel 7/9] COPY 3rdparty 3rdparty 0.8s
=> [wheel 8/9] COPY setup.py requirements.txt requirements-dev.txt ./ 0.1s
=> [wheel 9/9] RUN python3 scripts/build_wheel.py --clean --trt_root /usr/local/tensorrt --python_bindings --benchmarks 1858.0s
=> [release 2/11] COPY --from=wheel /src/tensorrt_llm/build/tensorrt_llm*.whl . 0.2s
=> [release 3/11] RUN pip install tensorrt_llm*.whl --extra-index-url https://pypi.nvidia.com && rm tensorrt_llm*.whl 43.7s
=> [release 4/11] COPY README.md ./ 0.0s
=> [release 5/11] COPY docs docs 0.0s
=> [release 6/11] COPY cpp/include include 0.0s
=> [release 7/11] COPY --from=wheel /src/tensorrt_llm/cpp/build/tensorrt_llm/libtensorrt_llm.so /src/tensorrt_llm/cpp/build/tensorrt_llm/libtensorrt_llm_static.a lib/ 0.1s
=> [release 8/11] RUN ln -sv $(TRT_LLM_NO_LIB_INIT=1 python3 -c "import tensorrt_llm.plugin as tlp; print(tlp.plugin_lib_path())") lib/ && cp -Pv lib/libnvinfer_plugin_tensorrt_llm.so li 1.8s
=> [release 9/11] COPY --from=wheel /src/tensorrt_llm/cpp/build/benchmarks/bertBenchmark /src/tensorrt_llm/cpp/build/benchmarks/gptManagerBenchmark /src/tensorrt_llm/cpp/build 0.1s
=> [release 10/11] COPY examples examples 0.1s
=> [release 11/11] RUN chmod -R a+w examples 0.5s
=> exporting to image 40.1s
=> => exporting layers 40.1s
=> => writing image sha256:a6a65ab955b6fcf240ee19e6601244d9b1b88fd594002586933b9fd9d598c025 0.0s
=> => naming to docker.io/tensorrt_llm/release:latest 0.0s
make: Leaving directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'
Thời gian cần thiết để xây dựng vùng chứa phụ thuộc nhiều vào tài nguyên có sẵn trên máy chủ mà bạn đang chạy lệnh trên đó. Trong trường hợp của tôi, đây là trên PowerEdge XE9680, đây là máy chủ nhanh nhất trong danh mục Dell PowerEdge.
Đang tải xuống trọng lượng mô hình
Tiếp theo, tôi cần tải xuống trọng số cho mô hình mà tôi sắp chuyển đổi sang TensorRT. Mặc dù tôi đang thực hiện việc này theo trình tự này, nhưng bước này có thể đã được thực hiện trước khi sao chép kho lưu trữ TensorRT LLM.
Trọng lượng mô hình có thể được tải xuống theo 2 cách khác nhau:
- Bên ngoài vùng chứa TensorRT
- Bên trong thùng chứa TensorRT
Lợi ích của việc tải chúng xuống bên ngoài vùng chứa TensorRT là chúng có thể được sử dụng lại cho nhiều chuyển đổi, trong khi đó, nếu chúng được tải xuống bên trong vùng chứa, chúng chỉ có thể được sử dụng cho một chuyển đổi duy nhất. Trong trường hợp của tôi, tôi sẽ tải chúng xuống bên ngoài vùng chứa vì tôi cảm thấy đây sẽ là phương pháp được hầu hết mọi người sử dụng. Đây là cách thực hiện:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ cd ..
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git lfs install
Git LFS initialized.
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
Cloning into ‘Llama-2-70b-chat-hf’...
Username for ‘https://huggingface.co’: ******
Password for ‘https://bronzafa@huggingface.co’:
remote: Enumerating objects: 93, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 93 (delta 1), reused 0 (delta 0), pack-reused 87
Unpacking objects: 100% (93/93), 509.43 KiB | 260.00 KiB/s, done.
Updating files: 100% (44/44), done.
Username for ‘https://huggingface.co’: ******
Password for ‘https://bronzafa@huggingface.co’:
Filtering content: 18% (6/32), 6.30 GiB | 2.38 MiB/s
Filtering content: 100% (32/32), 32.96 GiB | 9.20 MiB/s, done.
Tùy thuộc vào thiết lập của bạn, bạn có thể thấy một số thông báo lỗi về việc tệp không được sao chép đúng cách. Những điều đó có thể được bỏ qua một cách an toàn. Một điều đáng lưu ý khi tải xuống trọng lượng là bạn cần đảm bảo rằng bạn có nhiều bộ nhớ cục bộ vì việc nhân bản mô hình cụ thể này sẽ cần trên 500GB. Dung lượng lưu trữ rõ ràng sẽ phụ thuộc vào kích thước của kiểu máy và kiểu máy được chọn, nhưng chắc chắn có điều gì đó cần lưu ý.
Khởi động vùng chứa TensorRT
Bây giờ, tôi đã sẵn sàng khởi động vùng chứa TensorRT. Điều này có thể được thực hiện bằng lệnh sau:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ make -C docker release_run LOCAL_USER=1
make: Entering directory ‘/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker’
docker build –progress –pull --progress auto –build-arg BASE_IMAGE_WITH_TAG=tensorrt_llm/release:latest –build-arg USER_ID=1003 –build-arg USER_NAME=fbronzati –build-arg GROUP_ID=1001 –build-arg GROUP_NAME=ais –file Dockerfile.user –tag tensorrt_llm/release:latest-fbronzati ..
[+] Building 0.5s (6/6) FINISHED docker:default
=> [internal] load build definition from Dockerfile.user 0.0s
=> => transferring dockerfile: 531B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 359B 0.0s
=> [internal] load metadata for docker.io/tensorrt_llm/release:latest 0.0s
=> [1/2] FROM docker.io/tensorrt_llm/release:latest 0.1s
=> [2/2] RUN (getent group 1001 || groupadd –gid 1001 ais) && (getent passwd 1003 || useradd –gid 1001 –uid 1003 –create-home –no-log-init –shell /bin/bash fbronzati) 0.3s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:1149632051753e37204a6342c1859a8a8d9068a163074ca361e55bc52f563cac 0.0s
=> => naming to docker.io/tensorrt_llm/release:latest-fbronzati 0.0s
docker run –rm -it –ipc=host –ulimit memlock=-1 –ulimit stack=67108864 \
--gpus=all \
--volume /aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM:/code/tensorrt_llm \
--env “CCACHE_DIR=/code/tensorrt_llm/cpp/.ccache” \
--env “CCACHE_BASEDIR=/code/tensorrt_llm” \
--workdir /app/tensorrt_llm \
--hostname node002-release \
--name tensorrt_llm-release-fbronzati \
--tmpfs /tmp:exec \
tensorrt_llm/release:latest-fbronzati
=============
== PyTorch ==
=============
NVIDIA Release 23.12 (build 76438008)
PyTorch Version 2.2.0a0+81ea7a4
Container image Copyright © 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyrig©(c) 2014-2023 Facebook Inc.
Copy©ht (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
C©right (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu©opyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuo©)
Copyright (c) 2011-2013 NYU (Clement F©bet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jas©Weston)
Copyright (c) 2006 Idiap Research Institute ©my Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, J©ny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Variou©iles include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
fbronzati@node002-release:/app/tensorrt_llm$
Một trong những đối số của lệnh LOCAL_USER=1là bắt buộc để đảm bảo quyền sở hữu hợp lý các tệp sẽ được tạo sau này. Nếu không có đối số đó, tất cả các tệp mới tạo sẽ thuộc về, rootdo đó có khả năng gây ra những thách thức sau này.
Như bạn có thể thấy ở dòng cuối cùng của khối mã trước đó, dấu nhắc shell đã thay đổi. Trước khi chạy lệnh thì nó fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$và sau khi chạy lệnh thì nó là fbronzati@node002-release:/app/tensorrt_llm$. Đó là bởi vì, sau khi lệnh hoàn thành, bạn sẽ ở bên trong vùng chứa TensorRT và mọi thứ tôi cần làm để chuyển đổi về sau sẽ được thực hiện từ bên trong vùng chứa đó. Đây là lý do tại sao chúng tôi xây dựng nó ngay từ đầu vì nó cho phép chúng tôi tùy chỉnh vùng chứa dựa trên LLM đang được chuyển đổi.
Chuyển đổi LLM
Bây giờ tôi đã khởi động vùng chứa TensorRT và đang ở bên trong nó, tôi đã sẵn sàng chuyển đổi LLM từ định dạng Huggingface sang định dạng máy chủ Triton Inference.
Quá trình chuyển đổi sẽ cần tải token từ Huggingface nên mình cần đảm bảo rằng mình đã đăng nhập Hugginface. Tôi có thể làm điều đó bằng cách chạy cái này:
fbronzati@node002-release:/app/tensorrt_llm$ huggingface-cli login --token ******
Token will not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.
Token is valid (permission: read).
Your token has been saved to /home/fbronzati/.cache/huggingface/token
Login successful
Thay vì ******, bạn sẽ cần nhập mã thông báo API Huggingface của mình. Bạn có thể tìm thấy nó bằng cách đăng nhập vào Hugginface rồi truy cập Settingsvà sau đó Access Tokens. Nếu đăng nhập thành công, bạn sẽ thấy thông báo ở phía dưới Login successful.
Bây giờ tôi đã sẵn sàng bắt đầu quá trình tạo các công cụ TensorRT mới. Quá trình này lấy các trọng số mà chúng tôi đã tải xuống trước đó và tạo ra các công cụ TensorRT tương ứng. Số lượng công cụ được tạo sẽ phụ thuộc vào số lượng GPU có sẵn. Trong trường hợp của tôi, tôi sẽ tạo 4 công cụ TensorRT vì tôi có 4 GPU. Một lợi thế không rõ ràng của quá trình chuyển đổi là bạn có thể thay đổi số lượng động cơ bạn muốn cho mô hình của mình. Ví dụ: phiên bản đầu tiên của Llama-2-70b-chat-hfmô hình yêu cầu 8 GPU, nhưng trong quá trình chuyển đổi, tôi đã thay đổi từ 8 thành 4.
Quá trình chuyển đổi mất bao lâu sẽ hoàn toàn phụ thuộc vào phần cứng mà bạn có, nhưng nói chung sẽ mất một khoảng thời gian. Đây là lệnh để làm điều đó:
fbronzati@node002-release:/app/tensorrt_llm$ ví dụ về python3/llama/build.py \
–model_dir /code/tensorrt_llm/Llama-2-70b-chat-hf/ \
–dtype float16 \
–use_gpt_attention_plugin float16 \
–use_gemm_plugin float16 \
–remove_input_padding \
–use_inflight_batching \
–paged_kv_cache \
–output_dir /code/tensorrt_llm/examples/llama/out \
–world_size 4 \
–tp_size 4 \
–max_batch_size 64
fatal: not a git repository (or any of the parent directories): .git
[TensorRT-LLM] TensorRT-LLM version: 0.8.0.dev20240123
[01/31/2024-13:45:14] [TRT-LLM] [W] remove_input_padding is enabled, while max_num_tokens is not set, setting to max_batch_size*max_input_len.
It may not be optimal to set max_num_tokens=max_batch_size*max_input_len when remove_input_padding is enabled, because the number of packed input tokens are very likely to be smaller, we strongly recommend to set max_num_tokens according to your workloads.
[01/31/2024-13:45:14] [TRT-LLM] [I] Serially build TensorRT engines.
[01/31/2024-13:45:14] [TRT] [I] [MemUsageChange] Init CUDA: CPU +15, GPU +0, now: CPU 141, GPU 529 (MiB)
[01/31/2024-13:45:20] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +4395, GPU +1160, now: CPU 4672, GPU 1689 (MiB)
[01/31/2024-13:45:20] [TRT-LLM] [W] Invalid timing cache, using freshly created one
[01/31/2024-13:45:20] [TRT-LLM] [I] [MemUsage] Rank 0 Engine build starts - Allocated Memory: Host 4.8372 (GiB) Device 1.6502 (GiB)
[01/31/2024-13:45:21] [TRT-LLM] [I] Loading HF LLaMA ... from /code/tensorrt_llm/Llama-2-70b-chat-hf/
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15/15 [00:00<00:00, 16.67it/s]
[01/31/2024-13:45:22] [TRT-LLM] [I] Loading weights from HF LLaMA...
[01/31/2024-13:45:34] [TRT-LLM] [I] Weights loaded. Total time: 00:00:12
[01/31/2024-13:45:34] [TRT-LLM] [I] HF LLaMA loaded. Total time: 00:00:13
[01/31/2024-13:45:35] [TRT-LLM] [I] [MemUsage] Rank 0 model weight loaded. - Allocated Memory: Host 103.0895 (GiB) Device 1.6502 (GiB)
[01/31/2024-13:45:35] [TRT-LLM] [I] Optimized Generation MHA kernels (XQA) Enabled
[01/31/2024-13:45:35] [TRT-LLM] [I] Remove Padding Enabled
[01/31/2024-13:45:35] [TRT-LLM] [I] Paged KV Cache Enabled
[01/31/2024-13:45:35] [TRT] [W] IElementWiseLayer with inputs LLaMAForCausalLM/vocab_embedding/GATHER_0_output_0 and LLaMAForCausalLM/layers/0/input_layernorm/SHUFFLE_0_output_0: first input has type Half but second input has type Float.
[01/31/2024-13:45:35] [TRT] [W] IElementWiseLayer with inputs LLaMAForCausalLM/layers/0/input_layernorm/REDUCE_AVG_0_output_0 and LLaMAForCausalLM/layers/0/input_layernorm/SHUFFLE_1_output_0: first input has type Half but second input has type Float.
.
.
.
.
[01/31/2024-13:52:56] [TRT] [I] Engine generation completed in 57.4541 seconds.
[01/31/2024-13:52:56] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 1000 MiB, GPU 33268 MiB
[01/31/2024-13:52:56] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +33268, now: CPU 0, GPU 33268 (MiB)
[01/31/2024-13:53:12] [TRT] [I] [MemUsageStats] Peak memory usage during Engine building and serialization: CPU: 141685 MiB
[01/31/2024-13:53:12] [TRT-LLM] [I] Total time of building llama_float16_tp4_rank3.engine: 00:01:13
[01/31/2024-13:53:13] [TRT] [I] Loaded engine size: 33276 MiB
[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +64, now: CPU 38537, GPU 35111 (MiB)
[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +1, GPU +64, now: CPU 38538, GPU 35175 (MiB)
[01/31/2024-13:53:17] [TRT] [W] TensorRT was linked against cuDNN 8.9.6 but loaded cuDNN 8.9.4
[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +33267, now: CPU 0, GPU 33267 (MiB)
[01/31/2024-13:53:17] [TRT-LLM] [I] Activation memory size: 34464.50 MiB
[01/31/2024-13:53:17] [TRT-LLM] [I] Weights memory size: 33276.37 MiB
[01/31/2024-13:53:17] [TRT-LLM] [I] Max KV Cache memory size: 12800.00 MiB
[01/31/2024-13:53:17] [TRT-LLM] [I] Estimated max memory usage on runtime: 80540.87 MiB
[01/31/2024-13:53:17] [TRT-LLM] [I] Serializing engine to /code/tensorrt_llm/examples/llama/out/llama_float16_tp4_rank3.engine...
[01/31/2024-13:53:48] [TRT-LLM] [I] Engine serialized. Total time: 00:00:31
[01/31/2024-13:53:49] [TRT-LLM] [I] [MemUsage] Rank 3 Engine serialized - Allocated Memory: Host 7.1568 (GiB) Device 1.6736 (GiB)
[01/31/2024-13:53:49] [TRT-LLM] [I] Rank 3 Engine build time: 00:02:05 - 125.77239561080933 (sec)
[01/31/2024-13:53:49] [TRT] [I] Serialized 59 bytes of code generator cache.
[01/31/2024-13:53:49] [TRT] [I] Serialized 242287 bytes of compilation cache.
[01/31/2024-13:53:49] [TRT] [I] Serialized 14 timing cache entries
[01/31/2024-13:53:49] [TRT-LLM] [I] Timing cache serialized to /code/tensorrt_llm/examples/llama/out/model.cache
[01/31/2024-13:53:51] [TRT-LLM] [I] Total time of building all 4 engines: 00:08:36
Tôi đã loại bỏ các dòng đầu ra dư thừa, vì vậy bạn có thể mong đợi đầu ra của mình dài hơn thế này nhiều. Trong lệnh của tôi, tôi đã đặt thư mục đầu ra thành
/code/tensorrt_llm/examples/llama/out, vậy hãy kiểm tra nội dung của thư mục đó:
fbronzati@node002-release:/app/tensorrt_llm$ ll /code/tensorrt_llm/examples/llama/out/
total 156185008
drwxr-xr-x 2 fbronzati ais 250 Jan 31 13:53 ./
drwxrwxrwx 3 fbronzati ais 268 Jan 31 13:45 ../
-rw-r--r-- 1 fbronzati ais 2188 Jan 31 13:46 config.json
-rw-r--r-- 1 fbronzati ais 34892798724 Jan 31 13:47 llama_float16_tp4_rank0.engine
-rw-r--r-- 1 fbronzati ais 34892792516 Jan 31 13:49 llama_float16_tp4_rank1.engine
-rw-r--r-- 1 fbronzati ais 34892788332 Jan 31 13:51 llama_float16_tp4_rank2.engine
-rw-r--r-- 1 fbronzati ais 34892800860 Jan 31 13:53 llama_float16_tp4_rank3.engine
-rw-r--r-- 1 fbronzati ais 243969 Jan 31 13:53 model.cache
Chắc chắn rồi, đây là 4 tập tin động cơ của tôi. Nhưng tôi có thể làm gì với những thứ đó? Những thứ đó có thể được máy chủ NVIDIA Triton Inference tận dụng để chạy suy luận. Chúng ta hãy xem làm thế nào tôi có thể làm điều đó.
Bây giờ tôi đã hoàn tất quá trình chuyển đổi, tôi có thể thoát khỏi vùng chứa TensorRT:
fbronzati@node002-release:/app/tensorrt_llm$ exit
exit
make: Leaving directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'
Triển khai các tệp công cụ đến Máy chủ suy luận Triton
Vì NVIDIA không cung cấp phiên bản bộ chứa Máy chủ suy luận Triton với LLM làm tham số cho bộ chứa nên tôi sẽ cần xây dựng nó từ đầu để nó có thể tận dụng các tệp công cụ được tạo thông qua chuyển đổi. Quá trình này khá giống với những gì tôi đã thực hiện với vùng chứa TensorRT. Từ cấp độ cao, đây là quá trình:
- Sao chép kho lưu trữ phụ trợ của Triton Inference Server
- Sao chép các tập tin động cơ vào kho lưu trữ nhân bản
- Cập nhật một số thông số cấu hình cho các mẫu
- Xây dựng bộ chứa Máy chủ suy luận Triton
Hãy sao chép kho lưu trữ phụ trợ của Triton Inference Server:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ cd ..
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://github.com/triton-inference-server/tensorrtllm_backend.git
Cloning into 'tensorrtllm_backend'...
remote: Enumerating objects: 870, done.
remote: Counting objects: 100% (348/348), done.
remote: Compressing objects: 100% (165/165), done.
remote: Total 870 (delta 229), reused 242 (delta 170), pack-reused 522
Receiving objects: 100% (870/870), 387.70 KiB | 973.00 KiB/s, done.
Resolving deltas: 100% (439/439), done.
Hãy khởi tạo tất cả các mô-đun của bên thứ 3 và hỗ trợ Lưu trữ tệp lớn cho git:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ cd tensorrtllm_backend/
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git submodule update --init --recursive
Submodule 'tensorrt_llm' (https://github.com/NVIDIA/TensorRT-LLM.git) registered for path 'tensorrt_llm'
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm'...
Submodule path 'tensorrt_llm': checked out 'b57221b764bc579cbb2490154916a871f620e2c4'
Submodule '3rdparty/NVTX' (https://github.com/NVIDIA/NVTX.git) registered for path 'tensorrt_llm/3rdparty/NVTX'
Submodule '3rdparty/cutlass' (https://github.com/NVIDIA/cutlass.git) registered for path 'tensorrt_llm/3rdparty/cutlass'
Submodule '3rdparty/cxxopts' (https://github.com/jarro2783/cxxopts) registered for path 'tensorrt_llm/3rdparty/cxxopts'
Submodule '3rdparty/json' (https://github.com/nlohmann/json.git) registered for path 'tensorrt_llm/3rdparty/json'
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/NVTX'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/cutlass'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/cxxopts'...
Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/json'...
Submodule path 'tensorrt_llm/3rdparty/NVTX': checked out 'a1ceb0677f67371ed29a2b1c022794f077db5fe7'
Submodule path 'tensorrt_llm/3rdparty/cutlass': checked out '39c6a83f231d6db2bc6b9c251e7add77d68cbfb4'
Submodule path 'tensorrt_llm/3rdparty/cxxopts': checked out 'eb787304d67ec22f7c3a184ee8b4c481d04357fd'
Submodule path 'tensorrt_llm/3rdparty/json': checked out 'bc889afb4c5bf1c0d8ee29ef35eaaf4c8bef8a5d'
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git lfs install
Updated git hooks.
Git LFS initialized.
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git lfs pull
Bây giờ tôi đã sẵn sàng sao chép các tập tin công cụ vào kho lưu trữ nhân bản:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ cp ../TensorRT-LLM/examples/llama/out/* all_models/inflight_batcher_llm/tensorrt_llm/1/
Bước tiếp theo có thể được thực hiện bằng cách sửa đổi thủ công các config.pbtxttệp trong các thư mục khác nhau hoặc bằng cách sử dụng fill_template.pytập lệnh để viết các sửa đổi cho chúng tôi. Tôi sẽ sử dụng fill_template.pykịch bản, nhưng đó là sở thích của tôi. Hãy để tôi cập nhật các thông số đó:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ export HF_LLAMA_MODEL=meta-llama/Llama-2-70b-chat-hf
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ cp all_models/inflight_batcher_llm/ llama_ifb -r
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/preprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:llama,triton_max_batch_size:64,preprocessing_instance_count:1
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/postprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:llama,triton_max_batch_size:64,postprocessing_instance_count:1
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:64,decoupled_mode:False,bls_instance_count:1,accumulate_tokens:False
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/ensemble/config.pbtxt triton_max_batch_size:64
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/tensorrt_llm/config.pbtxt triton_max_batch_size:64,decoupled_mode:False,max_beam_width:1,engine_dir:/llama_ifb/tensorrt_llm/1/,max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.5,exclude_input_in_output:True,enable_kv_cache_reuse:False,batching_strategy:inflight_batching,max_queue_delay_microseconds:600
Bây giờ tôi đã sẵn sàng xây dựng bộ chứa docker Triton Inference Server với LLM mới được chuyển đổi của mình (bước này sẽ không bắt buộc sau khi ra mắt ngày 24.02):
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ DOCKER_BUILDKIT=1 docker build -t triton_trt_llm -f dockerfile/Dockerfile.trt_llm_backend .
[+] Building 2572.9s (33/33) FINISHED docker:default
=> [internal] load build definition from Dockerfile.trt_llm_backend 0.0s
=> => transferring dockerfile: 2.45kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for nvcr.io/nvidia/tritonserver:23.12-py3 0.7s
=> [internal] load build context 47.6s
=> => transferring context: 580.29MB 47.6s
=> [base 1/6] FROM nvcr.io/nvidia/tritonserver:23.12-py3@sha256:363924e9f3b39154bf2075586145b5d15b20f6d695bd7e8de4448c3299064af0 0.0s
=> CACHED [base 2/6] RUN apt-get update && apt-get install -y --no-install-recommends rapidjson-dev python-is-python3 ccache git-lfs 0.0s
=> [base 3/6] COPY requirements.txt /tmp/ 2.0s
=> [base 4/6] RUN pip3 install -r /tmp/requirements.txt --extra-index-url https://pypi.ngc.nvidia.com 28.1s
=> [base 5/6] RUN apt-get remove --purge -y tensorrt* 1.6s
=> [base 6/6] RUN pip uninstall -y tensorrt 0.9s
=> [dev 1/10] COPY tensorrt_llm/docker/common/install_tensorrt.sh /tmp/ 0.0s
=> [dev 2/10] RUN bash /tmp/install_tensorrt.sh && rm /tmp/install_tensorrt.sh 228.0s
=> [dev 3/10] COPY tensorrt_llm/docker/common/install_polygraphy.sh /tmp/ 0.0s
=> [dev 4/10] RUN bash /tmp/install_polygraphy.sh && rm /tmp/install_polygraphy.sh 2.5s
=> [dev 5/10] COPY tensorrt_llm/docker/common/install_cmake.sh /tmp/ 0.0s
=> [dev 6/10] RUN bash /tmp/install_cmake.sh && rm /tmp/install_cmake.sh 3.0s
=> [dev 7/10] COPY tensorrt_llm/docker/common/install_mpi4py.sh /tmp/ 0.0s
=> [dev 8/10] RUN bash /tmp/install_mpi4py.sh && rm /tmp/install_mpi4py.sh 38.7s
=> [dev 9/10] COPY tensorrt_llm/docker/common/install_pytorch.sh install_pytorch.sh 0.0s
=> [dev 10/10] RUN bash ./install_pytorch.sh pypi && rm install_pytorch.sh 96.6s
=> [trt_llm_builder 1/4] WORKDIR /app 0.0s
=> [trt_llm_builder 2/4] COPY scripts scripts 0.0s
=> [trt_llm_builder 3/4] COPY tensorrt_llm tensorrt_llm 3.0s
=> [trt_llm_builder 4/4] RUN cd tensorrt_llm && python3 scripts/build_wheel.py --trt_root="/usr/local/tensorrt" -i -c && cd .. 1959.1s
=> [trt_llm_backend_builder 1/3] WORKDIR /app/ 0.0s
=> [trt_llm_backend_builder 2/3] COPY inflight_batcher_llm inflight_batcher_llm 0.0s
=> [trt_llm_backend_builder 3/3] RUN cd inflight_batcher_llm && bash scripts/build.sh && cd .. 68.3s
=> [final 1/5] WORKDIR /app/ 0.0s
=> [final 2/5] COPY --from=trt_llm_builder /app/tensorrt_llm/build /app/tensorrt_llm/build 0.1s
=> [final 3/5] RUN cd /app/tensorrt_llm/build && pip3 install *.whl 22.8s
=> [final 4/5] RUN mkdir /opt/tritonserver/backends/tensorrtllm 0.4s
=> [final 5/5] COPY --from=trt_llm_backend_builder /app/inflight_batcher_llm/build/libtriton_tensorrtllm.so /opt/tritonserver/backends/tensorrtllm 0.0s
=> exporting to image 69.3s
=> => exporting layers 69.3s
=> => writing image sha256:03f4164551998d04aefa2817ea4ba9f53737874fc3604e284faa8f75bc99180c 0.0s
=> => naming to docker.io/library/triton_trt_llm
Nếu tôi kiểm tra hình ảnh docker của mình, tôi có thể thấy rằng hiện tại tôi đã có một hình ảnh mới cho máy chủ Triton Inference (bước này sẽ không được yêu cầu sau khi ra mắt ngày 24.02 vì sẽ không cần phải xây dựng Máy chủ suy luận Triton tùy chỉnh thùng chứa nữa):
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
triton_trt_llm latest 03f416455199 2 hours ago 53.1GB
Bây giờ tôi có thể khởi động vùng chứa docker mới được tạo:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $(pwd)/llama_ifb:/llama_ifb -v $(pwd)/scripts:/opt/scripts triton_trt_llm:latest bash
=============================
== Triton Inference Server ==
=============================
NVIDIA Release 23.12 (build 77457706)
Triton Server Version 2.41.0
Copyright (c) 2018-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
root@node002:/app#
Sau khi ra mắt phiên bản 24.02, tên của vùng chứa ở triton_trt_llmđây sẽ thay đổi, vì vậy bạn cần chú ý đến tên mới. Tôi sẽ cập nhật blog này với những thay đổi sau khi ra mắt.
Sau khi vùng chứa được khởi động, tôi sẽ quay lại dấu nhắc shell bên trong vùng chứa. Tôi cần đăng nhập lại vào Hugginface:
root@node002:/app# huggingface-cli login --token ******
Token will not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.
Token is valid (permission: read).
Your token has been saved to /root/.cache/huggingface/token
Login successful
Và bây giờ tôi có thể chạy máy chủ Triton Inference:
root@node002:/app# python /opt/scripts/launch_triton_server.py --model_repo /llama_ifb/ --world_size 4
root@node002:/app# I0131 16:54:40.234909 135 pinned_memory_manager.cc:241] Pinned memory pool is created at '0x7ffd8c000000' with size 268435456
I0131 16:54:40.243088 133 pinned_memory_manager.cc:241] Pinned memory pool is created at '0x7ffd8c000000' with size 268435456
I0131 16:54:40.252026 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 0 with size 67108864
I0131 16:54:40.252033 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 1 with size 67108864
I0131 16:54:40.252035 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 2 with size 67108864
I0131 16:54:40.252037 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 3 with size 67108864
I0131 16:54:40.252040 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 4 with size 67108864
I0131 16:54:40.252042 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 5 with size 67108864
I0131 16:54:40.252044 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 6 with size 67108864
I0131 16:54:40.252046 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 7 with size 67108864
.
.
.
.
.
I0131 16:57:04.101557 132 server.cc:676]
+------------------+---------+--------+
| Model | Version | Status |
+------------------+---------+--------+
| ensemble | 1 | READY |
| postprocessing | 1 | READY |
| preprocessing | 1 | READY |
| tensorrt_llm | 1 | READY |
| tensorrt_llm_bls | 1 | READY |
+------------------+---------+--------+
I0131 16:57:04.691252 132 metrics.cc:817] Collecting metrics for GPU 0: NVIDIA H100 80GB HBM3
I0131 16:57:04.691303 132 metrics.cc:817] Collecting metrics for GPU 1: NVIDIA H100 80GB HBM3
I0131 16:57:04.691315 132 metrics.cc:817] Collecting metrics for GPU 2: NVIDIA H100 80GB HBM3
I0131 16:57:04.691325 132 metrics.cc:817] Collecting metrics for GPU 3: NVIDIA H100 80GB HBM3
I0131 16:57:04.691335 132 metrics.cc:817] Collecting metrics for GPU 4: NVIDIA H100 80GB HBM3
I0131 16:57:04.691342 132 metrics.cc:817] Collecting metrics for GPU 5: NVIDIA H100 80GB HBM3
I0131 16:57:04.691350 132 metrics.cc:817] Collecting metrics for GPU 6: NVIDIA H100 80GB HBM3
I0131 16:57:04.691358 132 metrics.cc:817] Collecting metrics for GPU 7: NVIDIA H100 80GB HBM3
I0131 16:57:04.728148 132 metrics.cc:710] Collecting CPU metrics
I0131 16:57:04.728434 132 tritonserver.cc:2483]
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.41.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_ |
| | tensor_data parameters statistics trace logging |
| model_repository_path[0] | /llama_ifb/ |
| model_control_mode | MODE_NONE |
| strict_model_config | 1 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| cuda_memory_pool_byte_size{1} | 67108864 |
| cuda_memory_pool_byte_size{2} | 67108864 |
| cuda_memory_pool_byte_size{3} | 67108864 |
| cuda_memory_pool_byte_size{4} | 67108864 |
| cuda_memory_pool_byte_size{5} | 67108864 |
| cuda_memory_pool_byte_size{6} | 67108864 |
| cuda_memory_pool_byte_size{7} | 67108864 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
| cache_enabled | 0 |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0131 16:57:04.738042 132 grpc_server.cc:2495] Started GRPCInferenceService at 0.0.0.0:8001
I0131 16:57:04.738303 132 http_server.cc:4619] Started HTTPService at 0.0.0.0:8000
I0131 16:57:04.779541 132 http_server.cc:282] Started Metrics Service at 0.0.0.0:8002
Một lần nữa, tôi đã loại bỏ một số dòng đầu ra để giữ mọi thứ ở kích thước hợp lý. Khi trình tự bắt đầu đã hoàn tất, tôi có thể thấy máy chủ Triton Inference đang lắng nghe trên cổng 8000, vậy hãy kiểm tra nó nhé?
Hãy hỏi mô hình LLama 2 chạy trong Máy chủ suy luận Triton thủ đô của Texas ở Hoa Kỳ là gì:
root@node002:/app# curl -X POST localhost:8000/v2/models/ensemble/generate -d '{
"text_input": " <s>[INST] <<SYS>> You are a helpful assistant <</SYS>> What is the capital of Texas?[/INST]",
"parameters": {
"max_tokens": 100,
"bad_words":[""],
"stop_words":[""],
"temperature":0.2,
"top_p":0.7
}
}'
Vì tôi đang chạy curllệnh trực tiếp từ bên trong vùng chứa chạy máy chủ Triton Inference nên tôi đang sử dụng localhostlàm điểm cuối. Nếu bạn đang chạy curllệnh từ bên ngoài vùng chứa thì localhostsẽ cần phải thay thế bằng tên máy chủ thích hợp. Đây là phản hồi tôi nhận được:
{"context_logits":0.0,"cum_log_probs":0.0,"generation_logits":0.0,"model_name":"ensemble","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],"sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":" Sure, I'd be happy to help! The capital of Texas is Austin."}
Đúng! Nó hoạt động và tôi đã nhận được câu trả lời đúng từ LLM.
Phần kết luận
Nếu bạn đã đạt đến điểm này trong blog, cảm ơn bạn đã ở lại với tôi. Lấy một mô hình ngôn ngữ lớn từ Huggingface (nằm trong một trong các mô hình được hỗ trợ) và chạy nó trong máy chủ NVIDIA Triton Inference cho phép khách hàng tận dụng khả năng tự động hóa và tính đơn giản được tích hợp trong máy chủ NVIDIA Triton Inference. Tất cả đều đồng thời duy trì sự linh hoạt để lựa chọn mô hình ngôn ngữ lớn đáp ứng tốt nhất nhu cầu của họ. Nó gần giống như có chiếc bánh của bạn và ăn nó.
Cho đến lần sau, cảm ơn bạn đã đọc.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...