
Các kỹ thuật máy học có thể giúp biến dữ liệu thô thành các mô hình có thể được áp dụng để tạo ra những hiểu biết có ý nghĩa.
________________________

Trong bài viết đầu tiên của loạt bài này, chúng tôi đã nêu bật một số động cơ thúc đẩy việc sử dụng trí tuệ nhân tạo trong doanh nghiệp để hiểu rõ hơn về hiện tại và dự đoán tương lai. 1 Trong bài viết thứ hai , chúng tôi đã cung cấp các mô tả về phân tích dữ liệu, khoa học dữ liệu, học máy và học sâu. 2 Trong bài viết này, chúng tôi tiếp tục mô tả thực tế về học máy và trong bài viết tiếp theo, chúng tôi sẽ làm điều tương tự cho học sâu, một tập hợp con của học máy.
Học máy là gì?
Học máy là một cách tiếp cận AI — không phải là cách tiếp cận duy nhất, nhưng hiện tại là cách dễ thành công nhất trong các ứng dụng doanh nghiệp và hơn thế nữa. Các phương pháp tiếp cận máy học trong AI khác với các phương pháp tiếp cận AI rõ ràng, dựa trên quy tắc, chẳng hạn như các hệ thống chuyên gia, ở chỗ chúng được thiết kế để học hỏi từ dữ liệu. Các thuật toán cốt lõi của các ứng dụng máy học sử dụng dữ liệu để tạo và tinh chỉnh các quy tắc (trái ngược với việc lập trình viên xác định rõ ràng các quy tắc). Sau đó, máy tính sẽ quyết định cách phản hồi dựa trên những gì nó đã học được từ dữ liệu.
Vì vậy, làm thế nào để làm việc này? Ở cấp độ cao nhất và đơn giản nhất, tất cả các phương pháp học máy đều có hai giai đoạn: đào tạo và suy luận.
Đào tạo
Trong giai đoạn đầu tiên, thuật toán hoặc mô hình được đào tạo để nhận dạng các đặc điểm trong tập dữ liệu, chẳng hạn như các đặc điểm phổ biến đối với giá nhà đất, giao dịch mua của người tiêu dùng hoặc hình ảnh của các đồ vật thông thường. Nếu mô hình thấy đủ dữ liệu nhất quán và được gắn nhãn tốt, thì mô hình có thể tìm thấy các mẫu và “tìm hiểu” các tính năng trong dữ liệu nhất quán với các nhãn. Ví dụ: nó có thể được sử dụng để hiểu tính năng nào dự đoán giá mua nhà chính xác nhất, nỗ lực mua nào là gian lận và đối tượng nào dưới máy quét là táo, cam hoặc chuối. Tất nhiên, bạn cần dữ liệu tuyệt vời để đào tạo một mô hình chính xác. Nhưng làm thế nào để bạn biết mô hình của bạn là chính xác? Bạn xác thực mô hình của mình dựa trên một tập hợp con dữ liệu không được sử dụng để đào tạo và chấm điểm độ chính xác. Đây là một quá trình lặp đi lặp lại, với các vòng đào tạo và xác nhận liên tiếp.
Đối với một ứng dụng đơn giản, bạn có thể đào tạo mô hình của mình trên 70 phần trăm dữ liệu trong tập dữ liệu và xác thực nó trên 30 phần trăm còn lại. Với một ứng dụng phức tạp hơn, bạn có thể sử dụng 60 phần trăm dữ liệu để đào tạo, 20 phần trăm để xác thực và 20 phần trăm cho thử nghiệm cuối cùng. Các tỷ lệ này không phải là quy tắc khó và nhanh và các tỷ lệ thích hợp cho từng giai đoạn có thể khác nhau tùy theo tập dữ liệu. Công việc của nhà khoa học dữ liệu là xem xét tập dữ liệu và xác định các tỷ lệ sẽ hoạt động tốt nhất — đồng thời xác định thời điểm mô hình được đào tạo đủ chính xác để triển khai.
Sự suy luận
Trong bước thứ hai này của quy trình máy học, cao su chạm đường. Bạn đặt mô hình được đào tạo để làm việc với dữ liệu trong thế giới thực và để nó suy ra câu trả lời dựa trên dữ liệu đó. Sau đó, bạn theo dõi hiệu suất của mô hình theo thời gian. Nếu nó không đáp ứng các mục tiêu về độ chính xác của bạn, bạn có thể gửi nó trở lại chương trình đào tạo để đào tạo thêm, thường là với dữ liệu bổ sung/mới đã được thu thập.
Giải các bài toán đơn giản với hồi quy tuyến tính
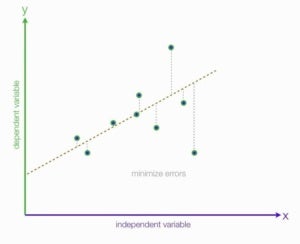
Học máy đã có từ rất lâu dưới nhiều hình thức khác nhau. Ví dụ, hồi quy tuyến tính là một kỹ thuật thống kê, là một hình thức học máy rất cơ bản. Hồi quy tuyến tính được sử dụng để hiển thị mối quan hệ giữa các biến, thường được biểu thị bằng độ dốc và tung độ gốc Y trong biểu đồ.
Hãy lấy một ví dụ đơn giản có chủ ý, để minh họa. Giả sử bạn muốn hiểu mối quan hệ giữa giá bán nhà ở một phân khu cụ thể và diện tích của những ngôi nhà đó. Với các kỹ thuật hồi quy tuyến tính, bạn có thể lấy các điểm dữ liệu này cho hàng chục lần bán hàng và vẽ chúng trên biểu đồ XY. Kết quả là đường dốc lên trên biểu đồ sẽ cho bạn thấy rằng giá là một chức năng của kích thước của ngôi nhà – khi diện tích vuông tăng lên, giá thường tăng lên.
Sự hiểu biết về mối quan hệ giữa hai biến số này sẽ cho phép mô hình máy học sử dụng dữ liệu để đưa ra dự đoán thống kê về tương lai và giá bán nhà. Nói cách khác, hồi quy tuyến tính cho phép bạn sử dụng dữ liệu đã nhìn thấy để xác định một hàm suy luận dựa trên dữ liệu chưa nhìn thấy . Hồi quy là công cụ đầu tiên trong hộp công cụ của nhà khoa học dữ liệu.
 DellEMC
DellEMCHình 1. Xem xét phân tích hồi quy tuyến tính, từ “ Giới thiệu về phân tích hồi quy tuyến tính ” của nhà khoa học dữ liệu David Longstreet.
Giải các bài toán khó hơn với cây quyết định
Tất nhiên, dữ liệu trong thế giới thực không đơn giản như trong ví dụ trước. Luôn có sự phức tạp và sắc thái đối với dữ liệu. Để phù hợp với ví dụ về thị trường nhà ở của chúng tôi, giá trị của những ngôi nhà cũng có thể bị ảnh hưởng bởi loại nhà ở, kích thước lô đất, những lần nâng cấp gần đây, khoảng cách gần với công viên khu phố và các biến số vô hình như sức hấp dẫn của lề đường. Và, trong thế giới thực, không phải tất cả các ngôi nhà đều ở trong cùng một khu phố, vì vậy, mô hình học máy của bạn cũng phải xem xét mã ZIP của tài sản.
Để xem xét phạm vi biến rộng hơn này, chúng ta cần tìm hiểu sâu hơn về hộp công cụ của nhà khoa học dữ liệu và rút ra một số phương pháp học máy tinh vi hơn, bao gồm rừng ngẫu nhiên và tăng cường độ dốc . Những khả năng này giúp bạn đào tạo các mô hình có thể đưa ra dự đoán chính xác hơn dựa trên dữ liệu quá phức tạp để có thể hiểu được bằng các công cụ hồi quy tuyến tính đơn giản.
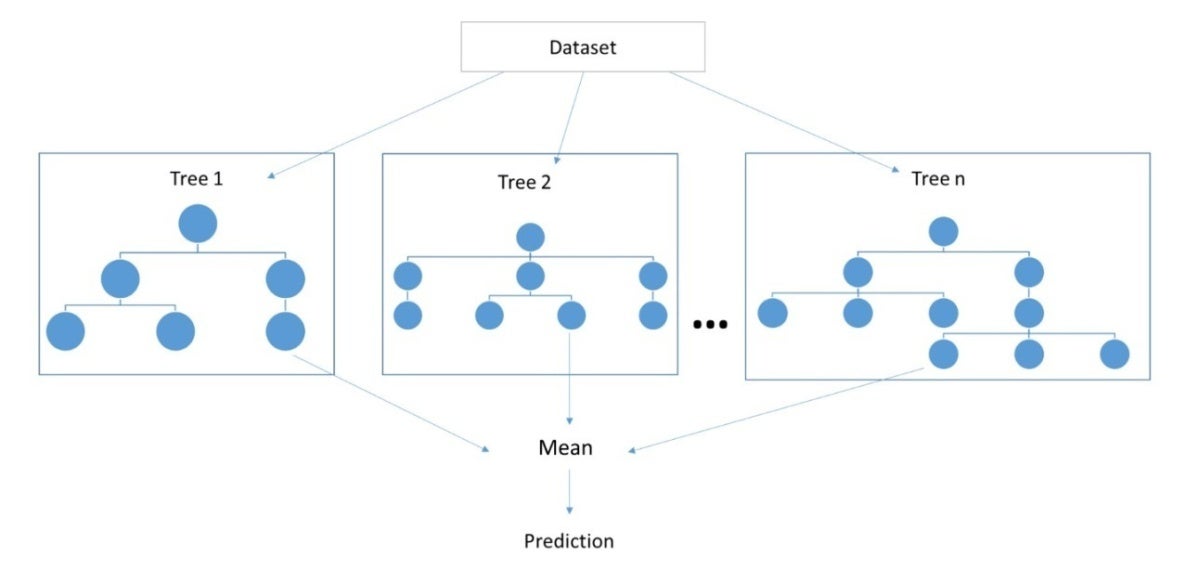
Rừng ngẫu nhiên là một kỹ thuật để tạo cây quyết định. Cây quyết định đưa ra dự đoán dựa trên các mối quan hệ phức tạp hơn trong dữ liệu. Trong trường hợp này, thuật toán học máy được đào tạo trên một tập hợp dữ liệu. Khi nó hoạt động với dữ liệu đào tạo, thuật toán tạo ngẫu nhiên các cây quyết định và khám phá các nhánh if-this/then-that khác nhau trong cây. Ý tưởng là, khi một điều gì đó xảy ra, sẽ có những hậu quả dẫn đến nhánh này hay nhánh khác.
Tăng cường độ dốc là một kỹ thuật giúp xử lý dữ liệu ồn ào hơn hoặc dữ liệu dường như ở khắp mọi nơi. Tăng cường độ dốc giúp bạn xác định các tính năng được mô tả bằng dữ liệu nên được đưa vào cây quyết định và những tính năng nên loại trừ vì chúng thực sự không quan trọng.
Vì vậy, làm thế nào để bạn đạt được điều đó?
Với kỹ thuật rừng ngẫu nhiên, bạn cung cấp một lượng lớn dữ liệu vào thuật toán và thuật toán sẽ chạy dữ liệu theo các đường dẫn (cây) khác nhau, tìm kiếm các mẫu trong dữ liệu. Nó lặp đi lặp lại để cải thiện khả năng dự đoán của nó. Sau rất nhiều quá trình đào tạo, thuật toán học máy sẽ giải quyết các cây quyết định hoạt động tốt nhất. Trong một số trường hợp, nó có thể lấy trung bình nhiều cây quyết định. Trên đường đi, không có con người nào tham gia vào việc tạo ra các cây quyết định. Thuật toán học máy tự làm tất cả. Cuối cùng, mô hình được đào tạo dựa trên cây quyết định có thể được sử dụng để phân loại và dự đoán với độ chính xác rất cao cho nhiều loại dữ liệu doanh nghiệp.
 DellEMC
DellEMCHình 2. Xem xét kỹ thuật rừng ngẫu nhiên, từ “ Rừng ngẫu nhiên và cây quyết định từ đầu trong trăn ” của Vaibhav Kumar, được xuất bản trong Hướng tới Khoa học Dữ liệu .
Tại thời điểm này, các nhà khoa học dữ liệu và lãnh đạo doanh nghiệp quay trở lại cuộc chơi. Họ đưa ra quyết định về thời điểm một mô hình được đào tạo sẵn sàng để được xác thực với dữ liệu mới mà nó chưa từng thấy trước đây. Khi quá trình đó thành công, những người ra quyết định con người sẽ xác định khi nào mô hình đã sẵn sàng để đưa vào sản xuất. Họ đặt ra các ngưỡng cho quyết định này. Ví dụ: họ có thể ra lệnh rằng khả năng dự đoán của mô hình phải chính xác ít nhất 95% trước khi nó đi vào hoạt động.
Và, tất nhiên, quá trình không kết thúc ở đó. Khi đưa một mô hình máy học đã qua đào tạo vào hoạt động, bạn cần theo dõi mô hình đó theo thời gian để xác minh rằng các dự đoán của mô hình đó là chính xác và hữu ích. Điều này giống như có một nhân viên thực sự trong công việc. Bạn thực hiện đánh giá hiệu suất định kỳ để đảm bảo nhân viên đáp ứng tất cả các kỳ vọng đi kèm với một chức danh công việc cụ thể. Nếu vậy, tuyệt vời! Nếu không, bạn cung cấp đào tạo bổ sung để giúp cải thiện hiệu suất và đạt được các mục tiêu kinh doanh.
Học có giám sát so với học không giám sát
Có một sắc thái bổ sung cần lưu ý ở đây: sự khác biệt giữa học tập có giám sát và không giám sát . Với phương pháp được giám sát, dữ liệu được gắn nhãn, vì vậy mô hình có cả tính năng và câu trả lời để huấn luyện. Ví dụ, ngoài việc biết các yếu tố đầu vào (chẳng hạn như diện tích và vị trí của một ngôi nhà), nó còn biết câu trả lời mong đợi (giá bán). Đối với bài viết này, chúng tôi tập trung vào phương pháp được giám sát, được sử dụng trong phần lớn các ứng dụng học máy của doanh nghiệp.
Với cách tiếp cận không giám sát, dữ liệu không được gắn nhãn và mô hình phải tự tìm hiểu mọi thứ. Chúng tôi sẽ đề cập đến chủ đề đào tạo không giám sát trong các bài viết tiếp theo, trong đó chúng tôi nói về các kỹ thuật học máy, chẳng hạn như sử dụng các kỹ thuật phân cụm để tìm các nhóm mục tự nhiên trong một lượng lớn dữ liệu chưa được gắn nhãn. Với các quy trình học tập không giám sát này, thuật toán sẽ tự phân tích dữ liệu và xác định các nhóm — ví dụ: nhóm khách hàng chứa các loại người mua sắm khác nhau.
điểm chính
Trong các bài viết tiếp theo của loạt bài này, chúng ta sẽ nói về một số trường hợp sử dụng cho các kỹ thuật máy học được giới thiệu ở đây. Hiện tại, một điểm quan trọng cần ghi nhớ đơn giản là: máy học có thể giúp bạn biến dữ liệu thô thành các mô hình có thể áp dụng để tạo ra những hiểu biết có ý nghĩa. Với những kỹ thuật này, bạn có thể sử dụng nhiều loại dữ liệu khác nhau, bao gồm cả dữ liệu phi cấu trúc và bán cấu trúc, để hiểu rõ hơn, từ đó dẫn đến các hành động và quyết định do hệ thống tạo ra trong các ứng dụng AI.
Tiếp theo: đi sâu vào học sâu
Trong phần tiếp theo của loạt bài này , chúng ta sẽ thảo luận về học sâu, là một loại học máy được xây dựng trên một hệ thống phân cấp sâu gồm các lớp “mạng lưới thần kinh” được kết nối với nhau. Chúng tôi sẽ giải thích cách các kỹ thuật học sâu lấy lượng dữ liệu khổng lồ và xác định các quy tắc cũng như tính năng phổ biến liên quan đến dữ liệu — mà không cần bất kỳ sự trợ giúp nào từ con người. Và, nhìn xa hơn một chút, trong các bài viết tiếp theo, chúng tôi sẽ chia sẻ các ví dụ về trường hợp sử dụng trong thế giới thực từ các tổ chức khác nhau đang tận dụng sức mạnh của AI.
Chúng tôi rất vui khi có bạn tham gia và hy vọng bạn sẽ tiếp tục theo dõi loạt bài của chúng tôi khi chúng tôi khám phá cách AI sẽ biến đổi doanh nghiệp mãi mãi và tạo ra các sản phẩm, dịch vụ và công việc mới.
Jay Boisseau, Ph.D., là nhà chiến lược công nghệ máy tính hiệu năng cao và trí tuệ nhân tạo tại Dell EMC.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...