
Tổng quan
Máy chủ Dell EMC PowerEdge R7525 hỗ trợ Bộ tăng tốc GPU AMD MI100 . Máy chủ là máy chủ dựa trên giá đỡ 2U, hai ổ cắm, được thiết kế để chạy các khối lượng công việc phức tạp bằng cách sử dụng bộ nhớ, dung lượng I/O và các tùy chọn mạng có khả năng mở rộng cao. Hệ thống này dựa trên bộ xử lý AMD EPYC thế hệ thứ 2 (tối đa 64 lõi), có tới 32 DIMM và có khe cắm mở rộng hỗ trợ PCI Express (PCIe) 4.0. Máy chủ hỗ trợ các ổ đĩa SATA, SAS và NVMe và tối đa ba bộ tăng tốc 300 W rộng gấp đôi.
Hình dưới đây cho thấy giao diện phía trước của máy chủ:

Hình 1. Máy chủ Dell EMC PowerEdge R7525
Bộ tăng tốc AMD Instinct™ MI100 là một trong những GPU HPC nhanh nhất thế giới hiện có trên thị trường. Nó cung cấp những cải tiến để đạt được hiệu suất cao hơn cho các ứng dụng HPC với các công nghệ chính sau:
- AMD Điện toán DNA ( CDNA )—Kiến trúc được tối ưu hóa cho khối lượng công việc thiên về tính toán
- AMD ROCm —Nền tảng phần mềm mở bao gồm trình điều khiển GPU, trình biên dịch, trình biên dịch, thư viện toán học và giao tiếp cũng như các công cụ quản lý tài nguyên hệ thống
- Giao diện điện toán không đồng nhất cho tính di động ( HIP )—Giao diện cho phép các nhà phát triển chuyển mã CUDA sang C++ di động để cùng một mã nguồn có thể chạy trên GPU AMD
Blog này tập trung vào các đặc tính hiệu suất của một máy chủ PowerEdge R7525 duy nhất có GPU AMD MI100-32G. Chúng tôi trình bày kết quả từ các điểm chuẩn vi mô của phép nhân ma trận chung (GEMM), điểm chuẩn LAMMPS và điểm chuẩn NAMD để thể hiện hiệu suất và khả năng mở rộng.
Bảng sau đây cung cấp chi tiết cấu hình của hệ thống PowerEdge R7525 đang được thử nghiệm (SUT):
Bảng 1. Cấu hình phần cứng và phần mềm SUT
| Thành phần | Sự miêu tả |
| Bộ xử lý | Bộ xử lý AMD EPYC 7502 32 nhân |
| Ký ức | 512 GB (32 GB 3200 MT/s * 16) |
| Đĩa cục bộ | SSD 2 x 1,8 TB (Không có RAID) |
| Hệ điều hành | Máy chủ Linux doanh nghiệp Red Hat 8.2 |
| GPU | 3 x AMD MI100-PCIe-32G |
| Phiên bản trình điều khiển | 3204 |
| Phiên bản ROCm | 3,9 |
| Cài đặt bộ xử lý > Bộ xử lý logic | Tàn tật |
| Hồ sơ hệ thống | Hiệu suất |
| Nút NUMA trên mỗi ổ cắm | 4 |
| điểm chuẩn NAMD | Phiên bản: NAMD 3.0 ALPHA 6 |
| Điểm chuẩn LAMMPS (KOKKOS) | Phiên bản: Bản vá LAMMPS_18Sep2020+Bản vá AMD |
Bảng sau liệt kê các thông số kỹ thuật GPU AMD MI100:
Bảng 2. Thông số GPU AMD MI100 PCIe
| Thành phần | |
| kiến trúc GPU | MI100 |
| Đồng hồ động cơ đỉnh (MHz) | 1502 |
| Bộ xử lý luồng | 7680 |
| Đỉnh FP64 (TFLOPS) | 11,5 |
| Đỉnh FP64 Tensor DGEMM (TFLOPS) | 11,5 |
| Đỉnh FP32 (TFLOPS) | 23.1 |
| SGEMM Tensor đỉnh FP32 (TFLOPS) | 46,1 |
| Kích thước bộ nhớ (GB) | 32 |
| Hỗ trợ bộ nhớ ECC | Đúng |
| TDP (Watt) | 300 |
Điểm chuẩn vi mô GEMM
Điểm chuẩn GEMM là điểm chuẩn nhân ma trận với ma trận dày đặc, đa luồng, đơn giản, có thể được sử dụng để kiểm tra hiệu suất của GEMM trên một GPU. Tệp nhị phân rocblas-bench được biên soạn từ https://github.com/ROCmSoftwarePlatform/rocBLAS đã được sử dụng để thu thập kết quả DGEMM và SGEMM. Kết quả của các thử nghiệm này phản ánh hiệu suất của một ứng dụng lý tưởng chỉ chạy phép nhân ma trận dưới dạng TFLOPS cao nhất mà GPU có thể cung cấp. Mặc dù kết quả điểm chuẩn GEMM có thể không thể hiện hiệu suất ứng dụng trong thế giới thực nhưng đây vẫn là điểm chuẩn tốt để chứng minh khả năng hiệu suất của các GPU khác nhau.
Hình dưới đây cho thấy số lượng DGEMM và SGEMM được quan sát:
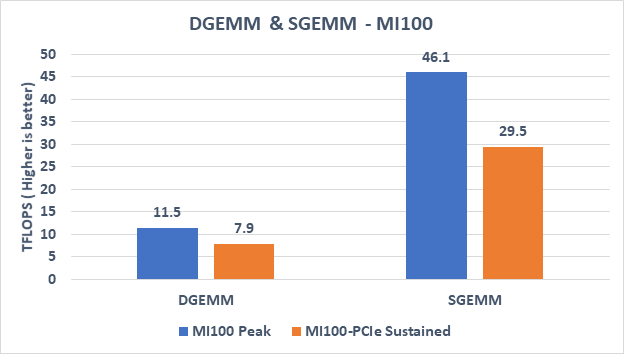
Hình 2. DGEMM và SGEMM cho cả AMD MI100 đỉnh cao và AMD-PCIe được duy trì
Kết quả chỉ ra:
- Trong điểm chuẩn DGEMM ( GEMM chính xác kép ) , hiệu suất cao nhất về mặt lý thuyết của GPU AMD MI100 là 11,5 TFLOPS và hiệu suất duy trì đo được là 7,9 TFLOPS . Như được hiển thị trong Bảng 2 , đỉnh lý thuyết có độ chính xác kép tiêu chuẩn ( FP64 ) và hiệu suất đỉnh DGEMM của tensor FP64 đều ở mức 11,5 TFLOPS . Bởi vì hầu hết các ứng dụng HPC trong thế giới thực thường không được triển khai nhiều với D GEMM hoặc các phép toán ma trận khác , nên khả năng giới hạn FP64 tiêu chuẩn cao giúp tăng hiệu suất trên các phép tính toán có độ chính xác kép không ma trận khác .
- Đối với các hoạt động Tensor FP32 trong điểm chuẩn SGEMM ( GEMM độ chính xác đơn ) , hiệu suất cao nhất về mặt lý thuyết của GPU AMD MI100 là 46,1 TFLOPS và hiệu suất duy trì đo được là khoảng 30 TFLOPS.
Điểm chuẩn LAMMPS
Bộ mô phỏng song song khối lượng lớn nguyên tử/phân tử quy mô lớn ( LAMMPS ) chạy các luồng song song bằng cách sử dụng các kỹ thuật truyền thông điệp. Điểm chuẩn này đo lường khả năng mở rộng và hiệu suất của các hệ thống lớn, song song gồm nhiều GPU.
Hình dưới đây cho thấy việc triển khai LAMMPS của KOKKOS được chia tỷ lệ tương đối tuyến tính khi GPU AMD MI100 được thêm vào trên bốn bộ dữ liệu: EAM, LJ, Tersoff và ReaxFF/C.
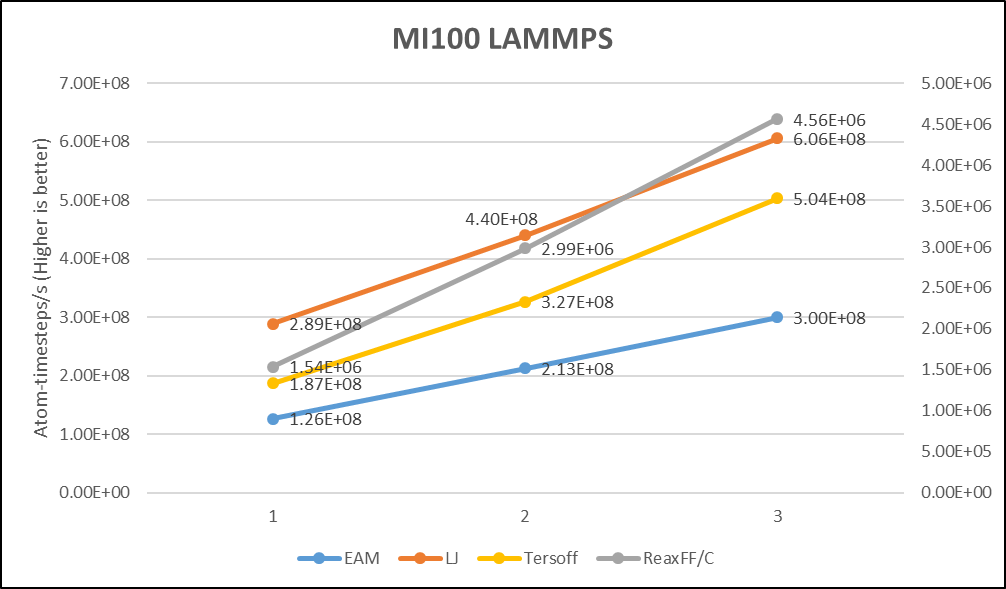
Hình 3. Điểm chuẩn LAMMPS hiển thị tỷ lệ của nhiều GPU AMD MI100
Điểm chuẩn NAMD
Động lực phân tử quy mô nano ( NAMD ) là một hệ thống động lực phân tử song song được thiết kế để mô phỏng các hệ thống phân tử sinh học lớn. Điểm chuẩn NAMD nhấn mạnh đến khía cạnh mở rộng và hiệu suất của cấu hình máy chủ và GPU.
Hình dưới đây biểu thị kết quả của microbenchmark NAMD:
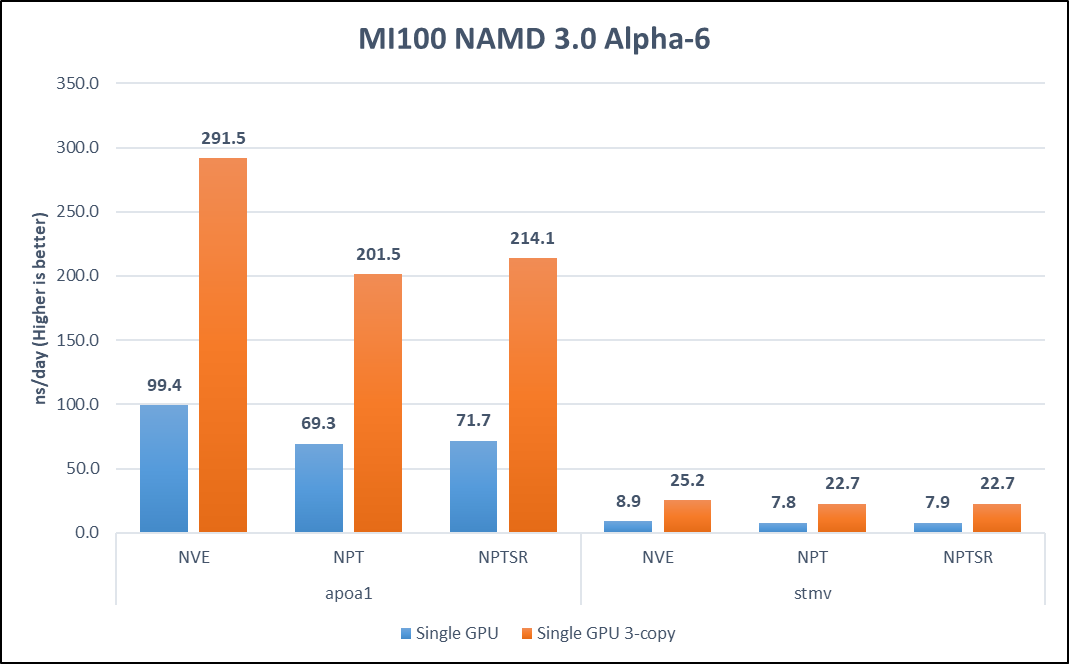
Hình 4. Hiệu suất benchmark NAMD
Dữ liệu tổng hợp của nhiều thẻ GPU được ưu tiên vì các bản dựng Alpha của nhị phân NAMD 3.0 không mở rộng ra ngoài một bộ tăng tốc duy nhất. Ba mô phỏng bản sao đã được khởi chạy song song trên cùng một máy chủ, một mô phỏng trên mỗi GPU. NAMD bị giới hạn CPU trong các phiên bản trước. Phiên bản 3.0 mới đã giảm bớt sự phụ thuộc vào CPU. Kết quả là mô phỏng ba bản sao tạo ra tỷ lệ tuyến tính hoạt động nhanh hơn ba lần trên tất cả các tập dữ liệu.
Là một phần của quá trình tối ưu hóa, các số điểm chuẩn NAMD trong hình sau cho thấy sự khác biệt về hiệu suất tương đối khi sử dụng số lượng lõi CPU khác nhau cho tập dữ liệu STMV:
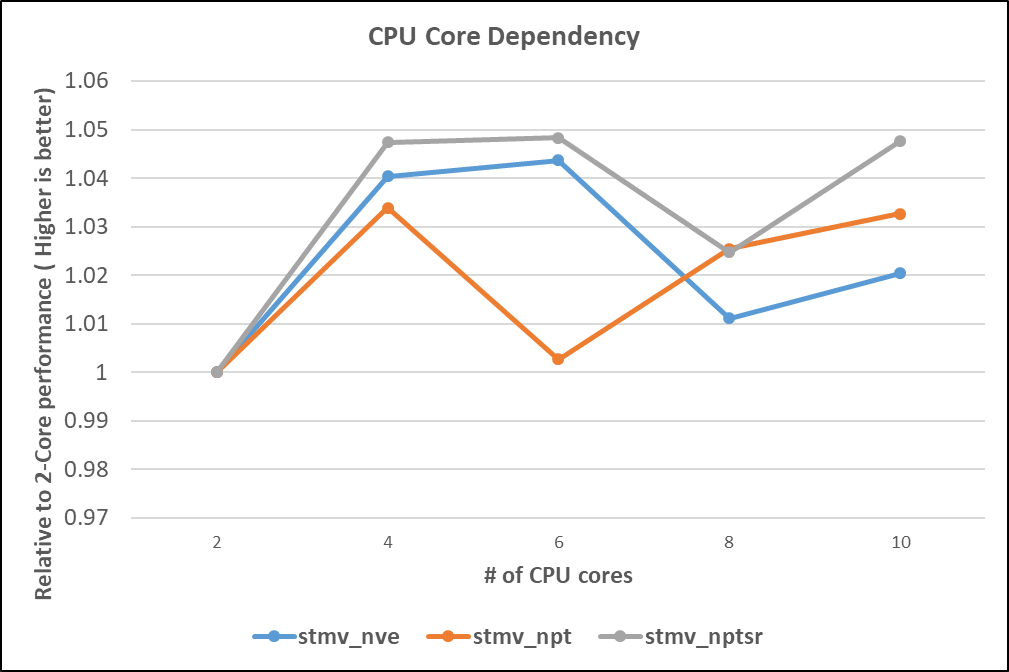
Hình 5. Sự phụ thuộc lõi CPU vào NAMD
GPU AMD MI100 thể hiện cấu hình tối ưu gồm bốn lõi CPU trên mỗi GPU.
Phần kết luận
Bộ tăng tốc AMD MI100 mang lại hiệu suất hàng đầu trong ngành và đây là GPU có hiệu suất trên mỗi đô la được định vị tốt cho cả mã song song FP32 và FP64 HPC.
- Các ứng dụng FP32 hoạt động tốt khi sử dụng GPU AMD MI100 dựa trên hiệu suất điểm chuẩn SGEMM, LAMMPS và NAMD bằng cách sử dụng lõi tensor và lõi tính toán FP32 gốc.
- Các ứng dụng FP64 hoạt động tốt khi sử dụng GPU AMD MI100 bằng cách sử dụng lõi tính toán FP64 gốc.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...