
Intel gần đây đã công bố bộ xử lý Intel Xeon Scalable thế hệ thứ 3 (tên mã là “Ice Lake”), dựa trên quy trình sản xuất 10 nm mới. Blog này cung cấp các kết quả điểm chuẩn tổng hợp của bộ xử lý Ice Lake mới và các cài đặt BIOS được đề xuất trên các máy chủ Dell EMC PowerEdge.
Bộ xử lý Ice Lake cung cấp số lượng lõi cao hơn lên tới 40 lõi với một bộ xử lý Ice Lake 8380. Bộ xử lý Ice Lake có bộ nhớ đệm dữ liệu L3, L2 và L1 lớn hơn so với bộ xử lý Cascade Lake thế hệ thứ hai của Intel. Những tính năng này dự kiến sẽ cải thiện hiệu suất của các ứng dụng phần mềm gắn với CPU. Bảng 1 cho thấy kích thước bộ đệm L1, L2 và L3 trên kiểu bộ xử lý 8380.
Ice Lake vẫn hỗ trợ hướng dẫn AVX 512 SIMD, cho phép 32 DP FLOP/chu kỳ. Tốc độ liên kết Ultra Path Interconnect (UPI) được nâng cấp là 11,2GT/s dự kiến sẽ cải thiện chuyển động dữ liệu giữa các ổ cắm. Ngoài số lượng và tần số lõi, các máy chủ Dell EMC PowerEdge dựa trên Ice Lake hỗ trợ DIMMS DDR4 – 3200 MT/s với tám kênh bộ nhớ trên mỗi bộ xử lý, dự kiến sẽ cải thiện hiệu suất của các ứng dụng giới hạn băng thông bộ nhớ. Bộ xử lý Ice Lake hiện hỗ trợ DIMM với 6 TB mỗi ổ cắm.
Các hướng dẫn như Vector CLMUL, VPMADD52, Vector AES và GFNI Extensions đã được tối ưu hóa để cải thiện việc sử dụng các thanh ghi véc tơ. Hiệu suất của các ứng dụng phần mềm trong lĩnh vực mật mã cũng sẽ được hưởng lợi. Bộ xử lý Ice Lake cũng bao gồm các cải tiến đối với Công nghệ Intel Speed Select (Intel SST). Với Intel SST, một vài lõi trong tổng số lõi khả dụng có thể được vận hành ở tần số cơ bản, tần số turbo hoặc công suất cao hơn. Blog này không đề cập đến tính năng này.
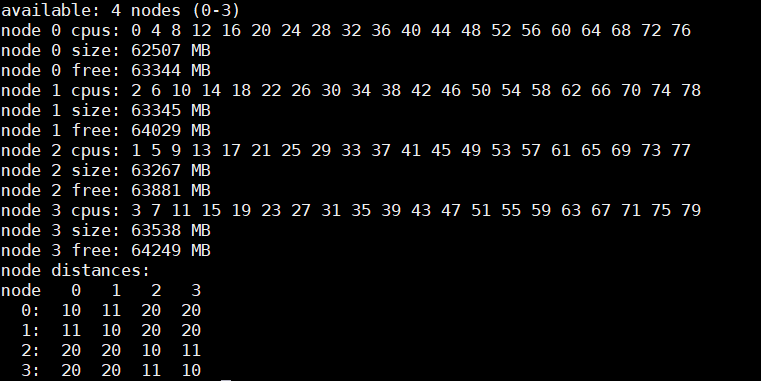
Bảng 1: đầu ra lệnh hwloc-ls và numactl -H trên máy chủ dựa trên kiểu bộ xử lý Intel 8380 với phép liệt kê lõi Round Robin (MadtCoreEnumeration) và SubNumaCuster(Cụm NUMA phụ) được đặt thành 2 chiều
| hwloc-ls | numactl -H |
| Máy (tổng 247GB)
Gói L#0 + L3 L#0 (60MB) Nhóm0 L#0 NUMANode L#0 (P#0 61GB) L2 L#0 (1280KB) + L1d L#0 (48KB) + L1i L#0 (32KB) + Lõi L#0 + PU L#0 (P#0) L2 L#1 (1280KB) + L1d L#1 (48KB) + L1i L#1 (32KB) + Lõi L#1 + PU L#1 (P#4) L2 L#2 (1280KB) + L1d L#2 (48KB) + L1i L#2 (32KB) + Lõi L#2 + PU L#2 (P#8) L2 L#3 (1280KB) + L1d L#3 (48KB) + L1i L#3 (32KB) + Lõi L#3 + PU L#3 (P#12) L2 L#4 (1280KB) + L1d L#4 (48KB) + L1i L#4 (32KB) + Lõi L#4 + PU L#4 (P#16) L2 L#5 (1280KB) + L1d L#5 (48KB) + L1i L#5 (32KB) + Lõi L#5 + PU L#5 (P#20) L2 L#6 (1280KB) + L1d L#6 (48KB) + L1i L#6 (32KB) + Lõi L#6 + PU L#6 (P#24) L2 L#7 (1280KB) + L1d L#7 (48KB) + L1i L#7 (32KB) + Lõi L#7 + PU L#7 (P#28) L2 L#8 (1280KB) + L1d L#8 (48KB) + L1i L#8 (32KB) + Lõi L#8 + PU L#8 (P#32) L2 L#9 (1280KB) + L1d L#9 (48KB) + L1i L#9 (32KB) + Lõi L#9 + PU L#9 (P#36) L2 L#10 (1280KB) + L1d L#10 (48KB) + L1i L#10 (32KB) + Lõi L#10 + PU L#10 (P#40) L2 L#11 (1280KB) + L1d L#11 (48KB) + L1i L#11 (32KB) + Lõi L#11 + PU L#11 (P#44) L2 L#12 (1280KB) + L1d L#12 (48KB) + L1i L#12 (32KB) + Lõi L#12 + PU L#12 (P#48) L2 L#13 (1280KB) + L1d L#13 (48KB) + L1i L#13 (32KB) + Lõi L#13 + PU L#13 (P#52) L2 L#14 (1280KB) + L1d L#14 (48KB) + L1i L#14 (32KB) + Lõi L#14 + PU L#14 (P#56) L2 L#15 (1280KB) + L1d L#15 (48KB) + L1i L#15 (32KB) + Lõi L#15 + PU L#15 (P#60) L2 L#16 (1280KB) + L1d L#16 (48KB) + L1i L#16 (32KB) + Lõi L#16 + PU L#16 (P#64) L2 L#17 (1280KB) + L1d L#17 (48KB) + L1i L#17 (32KB) + Lõi L#17 + PU L#17 (P#68) L2 L#18 (1280KB) + L1d L#18 (48KB) + L1i L#18 (32KB) + Lõi L#18 + PU L#18 (P#72) L2 L#19 (1280KB) + L1d L#19 (48KB) + L1i L#19 (32KB) + Lõi L#19 + PU L#19 (P#76) HostBridge. <cắt> . .
|
 |
Các tùy chọn BIOS được thử nghiệm trên bộ xử lý Ice Lake
Bảng 2 cung cấp các chi tiết máy chủ được sử dụng cho các bài kiểm tra hiệu suất. Các tùy chọn BIOS sau đây đã được khám phá trong thử nghiệm hiệu suất:
- BIOS.ProcSettings.SubNumaCluster —Chia LLC thành các cụm rời rạc dựa trên dải địa chỉ, với mỗi cụm được liên kết với một tập hợp con của bộ điều khiển bộ nhớ trong hệ thống. Nó cải thiện độ trễ trung bình cho LLC. Sub-NUMA Cluster (SNC) bị tắt nếu NVDIMM-N được cài đặt trong hệ thống.
- BIOS.ProcSettings.DeadLineLlcAlloc —Nếu được bật, hãy điền vào các dòng chết trong LLC một cách có cơ hội.
- BIOS.ProcSettings.LlcPrefetch —Bật và tắt LLC Prefetch trên tất cả các luồng.
- BIOS.ProcSettings.XptPrefetch —Nếu được bật, cho phép MS2IDI nhận yêu cầu đọc đang được gửi tới LLC và đưa ra một bản sao của yêu cầu đọc đó tới bộ điều khiển bộ nhớ.
- BIOS.ProcSettings.UpiPrefetch —Khởi động đọc sớm bộ nhớ trên bus DDR. Đường dẫn UPI Rx trực tiếp sinh MemSpecRd tới iMC.
- BIOS.ProcSettings.DcuIpPrefetcher (Trình tải trước IP của Bộ đệm dữ liệu)—Ảnh hưởng đến hiệu suất, tùy thuộc vào ứng dụng đang chạy trên máy chủ. Cài đặt này được khuyến nghị cho các ứng dụng Điện toán hiệu năng cao.
- BIOS.ProcSettings.DcuStreamerPrefetcher (Data Cache Unit Streamer Prefetcher)—Ảnh hưởng đến hiệu suất, tùy thuộc vào ứng dụng đang chạy trên máy chủ. Cài đặt này được khuyến nghị cho các ứng dụng Điện toán hiệu năng cao.
- BIOS.ProcSettings.ProcAdjCacheLine —Khi được đặt thành Đã bật , sẽ tối ưu hóa hệ thống cho các ứng dụng yêu cầu sử dụng cao quyền truy cập bộ nhớ tuần tự. Tắt tùy chọn này cho các ứng dụng yêu cầu sử dụng cao quyền truy cập bộ nhớ ngẫu nhiên.
- BIOS.SysProfileSettings.SysProfile —Đặt Cấu hình Hệ thống thành Hiệu suất trên Watt (DAPC), Hiệu suất trên Watt (OS), Hiệu suất, Hiệu suất của Máy trạm hoặc chế độ Tùy chỉnh. Khi được đặt thành một chế độ khác với Custom , BIOS sẽ đặt từng tùy chọn tương ứng. Khi được đặt thành Tùy chỉnh , bạn có thể thay đổi cài đặt của từng tùy chọn.
- BIOS.ProcSettings.LogicalProc —Báo cáo bộ xử lý logic. Mỗi lõi bộ xử lý hỗ trợ tối đa hai bộ xử lý logic. Khi được đặt thành Đã bật , BIOS sẽ báo cáo tất cả các bộ xử lý logic. Khi được đặt thành Đã tắt , BIOS chỉ báo cáo một bộ xử lý logic trên mỗi lõi. Nói chung, số lượng bộ xử lý cao hơn dẫn đến hiệu suất tăng lên đối với hầu hết các khối lượng công việc đa luồng. Khuyến nghị là giữ cho tùy chọn này được bật. Tuy nhiên, có một số khối lượng công việc khoa học và dấu phẩy động, bao gồm cả khối lượng công việc HPC, khi tắt tính năng này có thể mang lại hiệu suất cao hơn.
Bạn có thể đặt các tùy chọn DeadLineLlcAlloc , LlcPrefetch , XptPrefetch , UpiPrefetch , DcuIpPrefetcher , DcuStreamerPrefetcher , ProcAdjCacheLine và LogicalProc BIOS thành Enabled hoặc Disabled . Bạn có thể đặt SubNumaCluster thành 2-Way và Disabled . Cài đặt SysProfile có thể có năm giá trị: PerformanceOptimized, PerfPerWattOptimizedDapc, PerfPerWattOptimizedOs, PerfWorkStationOptimized và Custom.
Bảng 2: Chi tiết phần cứng và phần mềm của giường thử nghiệm
| Thành phần | Máy chủ Dell EMC PowerEdge R750 | Máy chủ Dell EMC PowerEdge C6520 | Máy chủ Dell EMC PowerEdge C6420 | Máy chủ Dell EMC PowerEdge C6420 |
| mở | 8380 | 6338 | 8280 | 6252 |
| Lõi/ổ cắm | 40 | 32 | 28 | 24 |
| Tần số (Base-Boost) |
2,30 – 3,40 GHz | 2,0 – 3,20 GHz | 2,70 – 4,0 GHz | 2,10 – 3,70 GHz |
| TDP | 270W | 205 W | 205 W | 150W |
| L3Cache | 60M | 48M | 38,5 triệu | 37.75M |
| Hệ điều hành | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | Doanh nghiệp mũ đỏ Linux 8.3
4.18.0-240.el8.x86_64 |
Doanh nghiệp mũ đỏ Linux 8.3
4.18.0-240.el8.x86_64 |
| Kỉ niệm | 16 GB x 16 (2Rx8) 3200 tấn/giây | 16 GB x 16 (2Rx8) 3200 tấn/giây | 16 GB x 12 (2Rx8)
2933 tấn/giây |
16 GB x 12 (2Rx8)
2933 tấn/giây |
| BIOS/CPLD | 1.1.2/1.0.1 | |||
| kết nối | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR100 | NVIDIA Mellanox HDR100 |
| Trình biên dịch | Studio song song Intel 2020 (bản cập nhật 4) | |||
| phần mềm điểm chuẩn |
|
|||
Tùy chọn meta BIOS cấu hình hệ thống giúp đặt một nhóm các tùy chọn BIOS (chẳng hạn như C1E, C States, v.v.), mỗi tùy chọn kiểm soát hiệu suất và cài đặt quản lý nguồn thành một giá trị cụ thể. Cũng có thể đặt riêng các nhóm tùy chọn BIOS này thành một giá trị khác bằng cách sử dụng Cấu hình hệ thống tùy chỉnh .
Kết quả thực hiện ứng dụng
Bảng 2 liệt kê chi tiết về phần mềm được sử dụng để đo điểm chuẩn cho máy chủ. Chúng tôi đã sử dụng các tệp nhị phân HPL và HPCG được biên dịch sẵn, là một phần của gói phần mềm Intel Parallel Studio 2020 cập nhật 4, cho các thử nghiệm của chúng tôi. Chúng tôi đã biên dịch ứng dụng WRF với sự hỗ trợ của AVX2. WRF và HPCG phát hành nhiều hoạt động vi mô đóng gói điểm không nổi (khoảng 73 phần trăm đến 90 phần trăm tổng số hoạt động vi mô đóng gói). Chúng là khối lượng công việc giới hạn bộ nhớ (và giới hạn băng thông DRAM). Các sự cố HPL đóng gói các hoạt động vi mô có độ chính xác gấp đôi và là khối lượng công việc bị ràng buộc bởi điện toán.
Sau khi đặt Sub-NUMA Cluster ( BIOS.ProcSettings.SubNumaCluster ) thành 2-Way , Bộ xử lý logic ( BIOS.ProcSettings.LogicalProc ) thành Disabled và các cài đặt khác ( DeadLineLlcAlloc , LlcPrefetch , XptPrefetch , UpiPrefetch , DcuIpPrefetcher , DcuStreamerPrefetcher , ProcAdjCacheLine ) thành Enabled , chúng tôi đã đo lường tác động của các tham số BIOS Hồ sơ Hệ thống ( BIOS.SysProfileSettings.SysProfile ) đối với hiệu suất của ứng dụng.
Hình 1 đến Hình 4 cho thấy hiệu suất của ứng dụng. Trong mỗi hình, các số trên các thanh thể hiện sự thay đổi tương đối trong hiệu suất của ứng dụng so với hiệu suất của ứng dụng thu được trên bộ xử lý Intel 6338 Ice Lake với Cấu hình hệ thống được đặt thành Tối ưu hóa hiệu suất (PO).
Lưu ý : Trong các số liệu, PO=PerformanceOptimized, PPWOD=PerfPerWattOptimizedDapc, PPWOO=PerfPerWattOptimizedOs và PWSO=PerfWorkStationOptimized.
Điểm chuẩn HPL
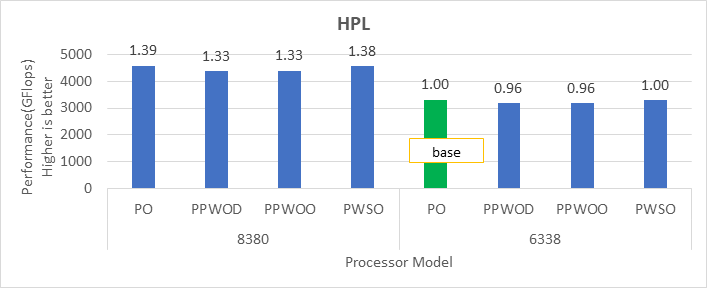
Hình 1: Sự khác biệt tương đối về hiệu suất của HPL theo bộ xử lý và cài đặt Cấu hình hệ thống
Điểm chuẩn HPCG
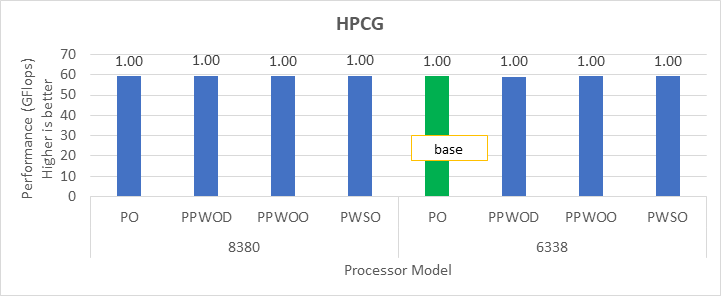
Hình 2: Sự khác biệt tương đối về hiệu suất của HPCG theo bộ xử lý và cài đặt Cấu hình hệ thống
Điểm chuẩn STREAM
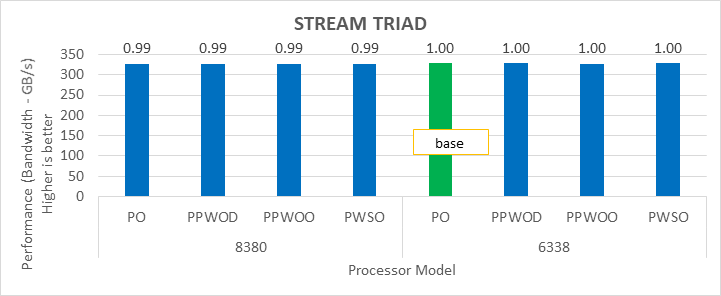
Hình 3: Sự khác biệt tương đối về hiệu suất của STREAM theo bộ xử lý và cài đặt Cấu hình hệ thống
Điểm chuẩn WRF
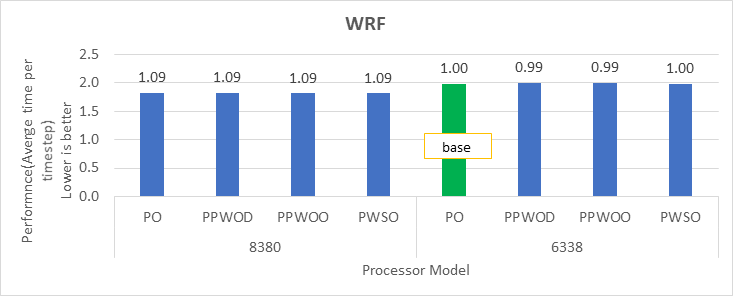 Hình 4: Sự khác biệt tương đối về hiệu suất của WRF theo bộ xử lý và cài đặt Cấu hình hệ thống
Hình 4: Sự khác biệt tương đối về hiệu suất của WRF theo bộ xử lý và cài đặt Cấu hình hệ thống
Chúng tôi đã đạt được hiệu suất cho các ứng dụng trong Hình 2 đến Hình 4 bằng cách đăng ký đầy đủ tất cả các lõi có sẵn. Tùy thuộc vào kiểu bộ xử lý, chúng tôi đã đạt được hiệu suất từ 78 phần trăm đến 80 phần trăm với các điểm chuẩn HPL và STREAM bằng cách sử dụng cấu hình Tối ưu hóa Hiệu suất.
Intel đã mở rộng TDP của bộ xử lý Ice Lake với bộ xử lý Intel 8380 cao cấp nhất ở 270 W TDP. Hình dưới đây cho thấy việc sử dụng năng lượng trên hệ thống với các ứng dụng được liệt kê trong Bảng 2.
Lưu ý : Trong hình này, PO=PerfPerWattOptimized, PPWOD=PerfPerWattOptimizedDapc, PPWOO=PerfPerWattOptimizedOs và PWSO=PerfWorkStationOptimized
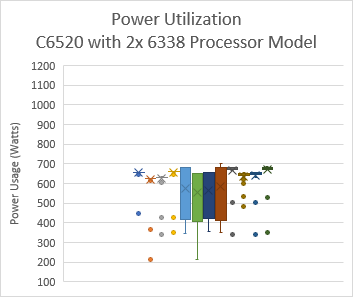
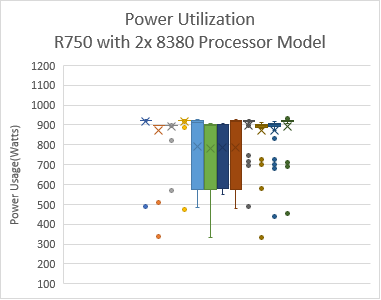

Hình 5: Mức sử dụng năng lượng theo nền tảng và loại bộ xử lý. Mức sử dụng năng lượng nhàn rỗi trung bình trên máy chủ PowerEdge C6520 (bộ xử lý Intel 6338) với khoảng 335 W và máy chủ PowerEdge R750 (bộ xử lý intel 8380) với khoảng 470 W khi sử dụng Cấu hình hệ thống được tối ưu hóa hiệu suất.
Khi SNC được đặt thành 2 Chiều , hệ thống sẽ hiển thị bốn nút NUMA. Chúng tôi đã thử nghiệm băng thông NUMA, băng thông ổ cắm từ xa và băng thông ổ cắm cục bộ bằng điểm chuẩn STREAM TRIAD. Trong Hình 6, nút NUMA của CPU được biểu thị là c và nút bộ nhớ được biểu thị là m. Như một ví dụ về băng thông NUMA, loại thử nghiệm c0m0 (thanh màu xanh lam) đại diện cho thử nghiệm STREAM TRIAD được thực hiện giữa nút NUMA 0 và nút bộ nhớ 0. Hình 6 cho thấy số lượng băng thông tốt nhất thu được khi thay đổi số lượng luồng cho mỗi loại thử nghiệm.
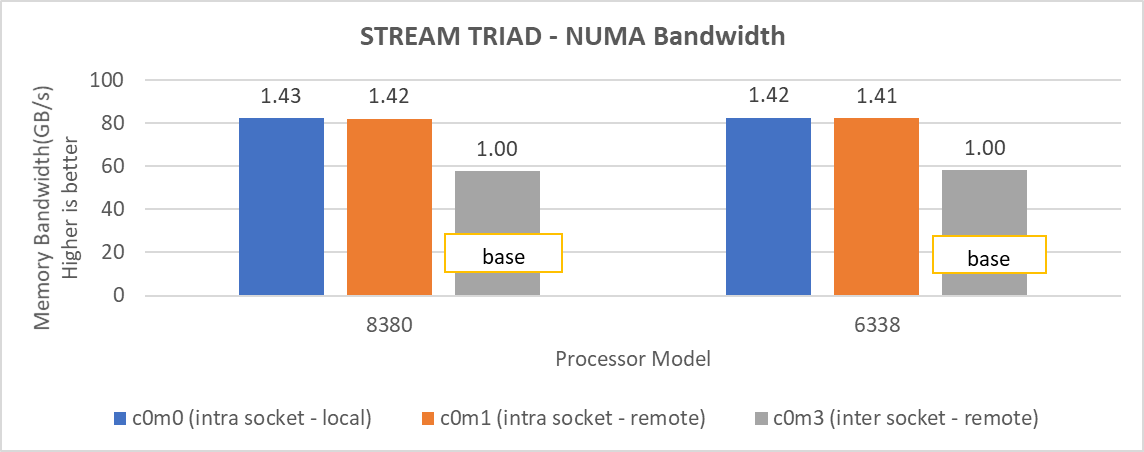
Hình 6: Băng thông bộ nhớ NUMA cục bộ và từ xa.
Số băng thông của ổ cắm từ xa được đo giữa nút CPU 0, 1 và nút bộ nhớ 2, 3. Băng thông cục bộ được đo giữa nút CPU 0, 1 và 0, 1. Hình dưới đây cho biết các số hiệu suất.
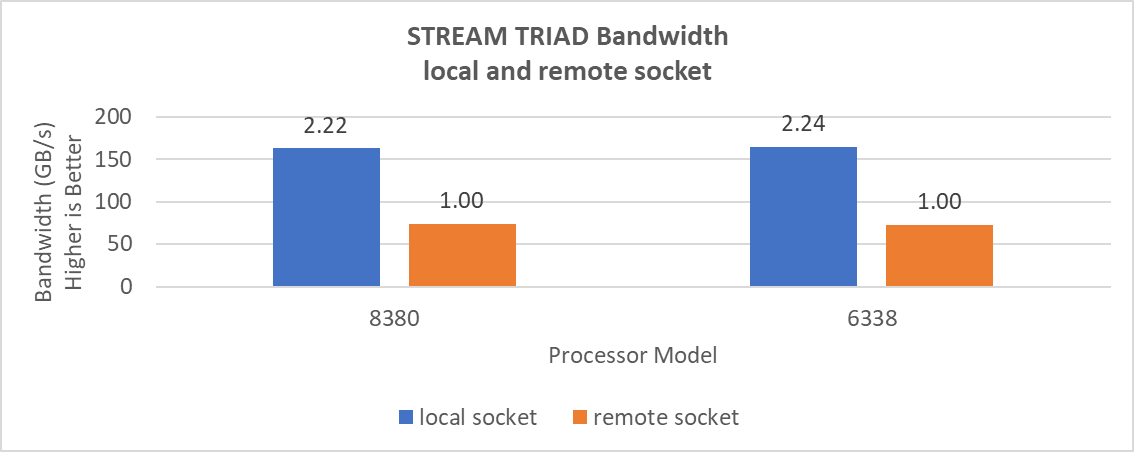
Hình 7: Băng thông bộ xử lý cục bộ và từ xa.
Tác động của các tùy chọn BIOS đối với hiệu suất ứng dụng
Chúng tôi đã thử nghiệm tác động của DeadLineLlcAlloc , LlcPrefetch , XptPrefetch , UpiPrefetch , DcuIpPrefetcher , DcuStreamerPrefetcher và ProcAdjCacheLine với cấu hình hệ thống Tối ưu hóa Hiệu suất (PO). Các tùy chọn BIOS này không có tác động đáng kể đến hiệu suất của các ứng dụng được đề cập trong blog này, do đó chúng tôi khuyên bạn nên đặt các tùy chọn này là Đã bật .
Hình 8 và Hình 9 cho thấy tác động của tùy chọn BIOS Sub-NUMA Cluster (SNC) đối với hiệu suất của ứng dụng. Trong mỗi hình, các số trên các thanh thể hiện sự thay đổi tương đối trong hiệu suất của ứng dụng so với hiệu suất của ứng dụng thu được trên bộ xử lý Intel 6338 Ice Lake với tính năng SNC được đặt thành Tắt .
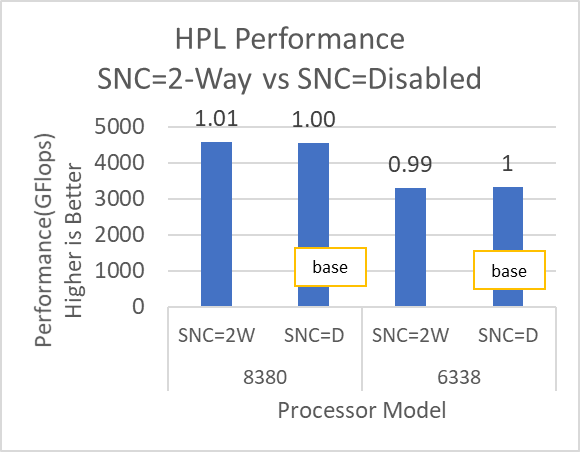
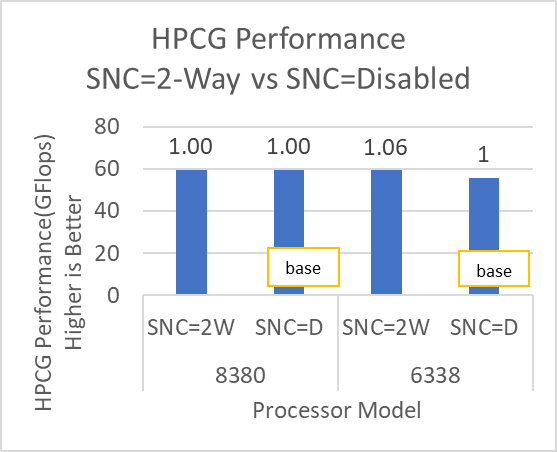
Hình 8: Biến thể hiệu suất HPL và HPCG theo kiểu bộ xử lý với Sub-NUMA Cluster được đặt thành Tắt (SNC=D) và 2 chiều (SNC=2W)
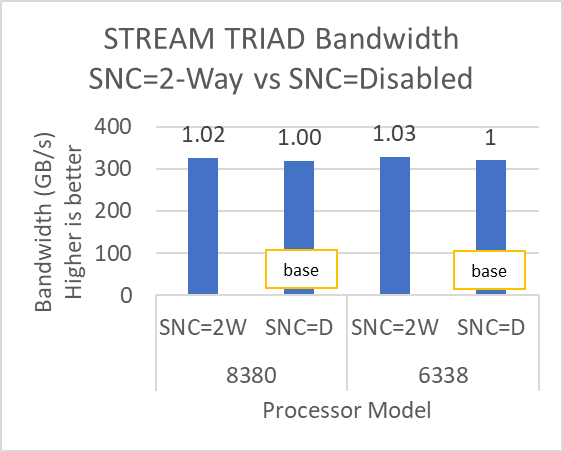
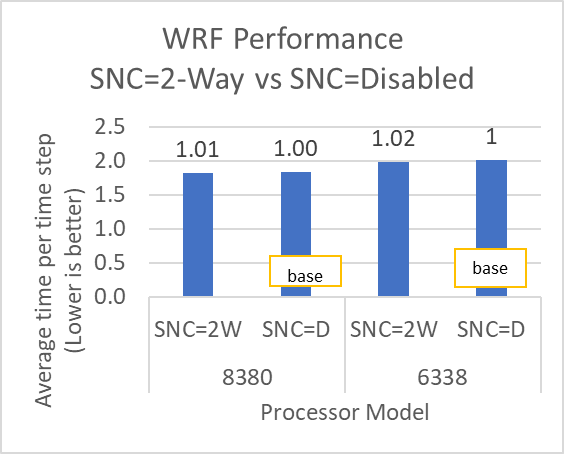
Hình 9: Biến thể hiệu suất STREAM và WRF theo kiểu bộ xử lý với Cụm Sub-NUMA được đặt thành Tắt (SNC=D) và 2 chiều (SNC=2W)
Tùy chọn SubNumaCluster có thể tác động đến các ứng dụng bị giới hạn băng thông bộ nhớ (ví dụ: STREAM, HPCG và WRF). Bạn nên đặt tùy chọn SubNumaCluster thành 2 Chiều vì tùy chọn này có thể tối ưu hóa khối lượng công việc được giải quyết trong blog này trong phạm vi từ một phần trăm đến sáu phần trăm, tùy thuộc vào kiểu bộ xử lý và ứng dụng.
Tốc độ tin nhắn và băng thông InfiniBand
Bộ xử lý dựa trên Ice Lake hiện hỗ trợ PCIe Gen 4, cho phép sử dụng thẻ bộ điều hợp NVIDIA MELLANOX HDR với máy chủ Dell EMC PowerEdge. Hình 10, Hình 11 và Hình 12 hiển thị kết quả kiểm tra băng thông InfiniBand Tốc độ tin nhắn, Một hướng và Hai hướng của bộ Điểm chuẩn OSU. Thẻ bộ điều hợp mạng được kết nối với ổ cắm thứ hai (nút NUMA 2), do đó, các bài kiểm tra băng thông cục bộ được thực hiện với các quy trình được liên kết với nút NUMA 2. Các bài kiểm tra băng thông từ xa được thực hiện với các quy trình được liên kết với nút NUMA 0. Trong Hình Trong Hình 10 và Hình 11, các số màu đỏ trên các thanh màu cam biểu thị phần trăm chênh lệch giữa các số hiệu suất băng thông cục bộ và từ xa.
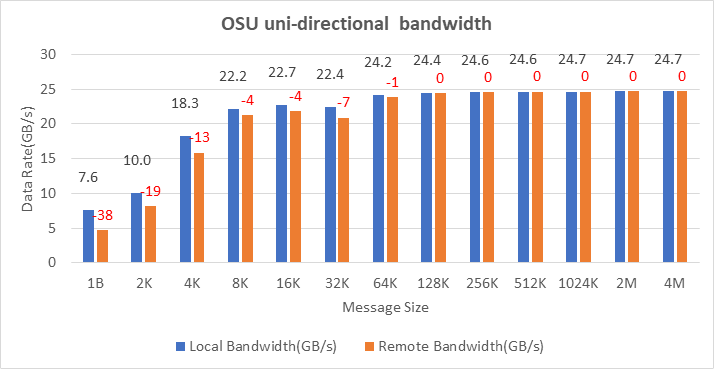 Hình 10: Kiểm tra băng thông một chiều của OSU Benchmark trên hai máy chủ với bộ xử lý Intel 8380 và NVIDIA Mellanox HDR InfiniBand
Hình 10: Kiểm tra băng thông một chiều của OSU Benchmark trên hai máy chủ với bộ xử lý Intel 8380 và NVIDIA Mellanox HDR InfiniBand
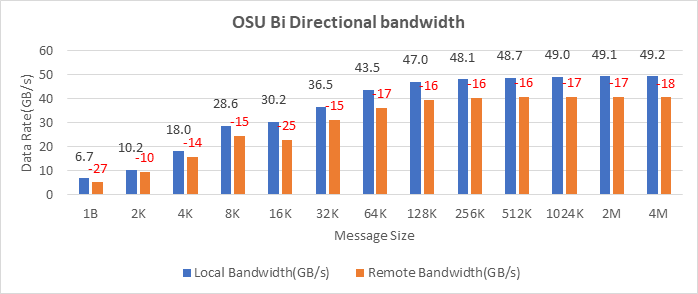 Hình 11: Kiểm tra băng thông hai chiều của OSU Benchmark trên hai máy chủ với bộ xử lý Intel 8380 và NVIDIA Mellanox HDR InfiniBand
Hình 11: Kiểm tra băng thông hai chiều của OSU Benchmark trên hai máy chủ với bộ xử lý Intel 8380 và NVIDIA Mellanox HDR InfiniBand
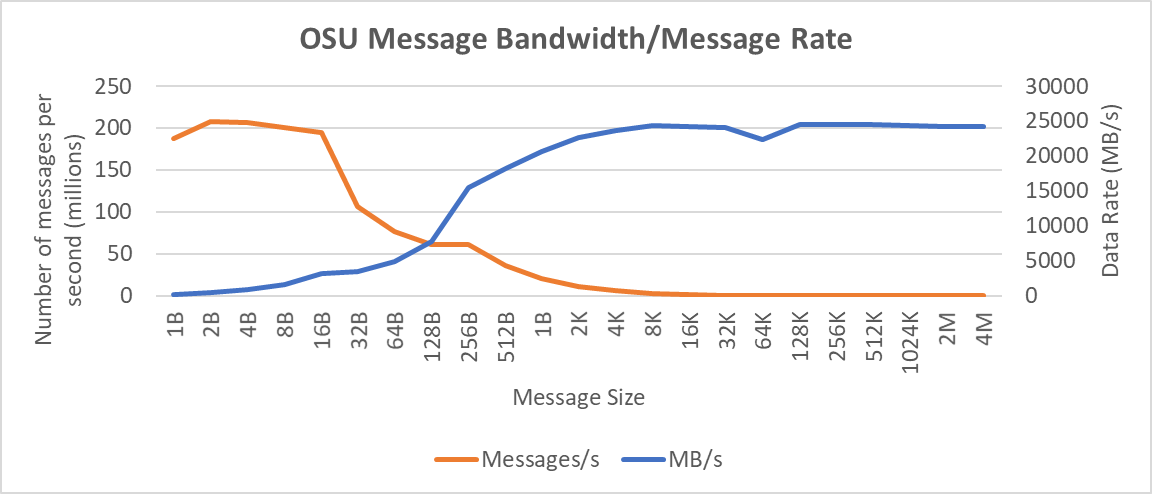
Hình 12: Kết nối băng thông và hiệu suất tốc độ tin nhắn thu được giữa hai máy chủ có bộ xử lý Intel 8380 với OSU Benchmark
Trên hai nút được kết nối bằng thẻ bộ điều hợp NVIDIA Mellanox ConnectX-6 HDR InfiniBand, chúng tôi đã đạt được băng thông một chiều khoảng 25 GB/giây và tốc độ tin nhắn khoảng 200 triệu tin nhắn/giây—gần gấp đôi con số hiệu suất thu được trên thẻ NVIDIA Mellanox HDR100.
So sánh với bộ xử lý Cascade Lake
Dựa trên tính khả dụng của tài nguyên điện toán trong Phòng thí nghiệm đổi mới trí tuệ nhân tạo và HPC của Dell EMC, chúng tôi đã chọn các máy chủ chạy trên bộ xử lý Cascade Lake và đo điểm chuẩn cho chúng bằng phần mềm được liệt kê trong Bảng 1. Hình 13 đến Hình 16 cho thấy kết quả hiệu suất từ Intel Ice Lake và Cascade Hồ xử lý. Các số trên các thanh thể hiện sự thay đổi tương đối trong hiệu suất của ứng dụng so với hiệu suất của ứng dụng đạt được trên bộ xử lý Intel 6252 Cascade Lake.
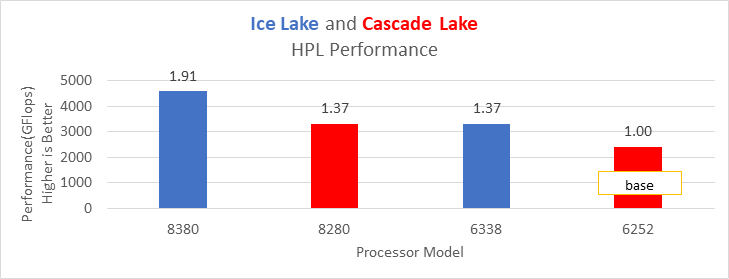 Hình 13: Hiệu suất HPL trên các bộ xử lý được liệt kê trong Bảng 2
Hình 13: Hiệu suất HPL trên các bộ xử lý được liệt kê trong Bảng 2
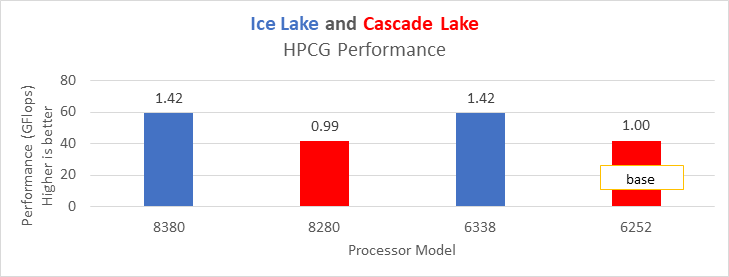 Hình 14: Hiệu suất HPCG trên các bộ xử lý được liệt kê trong Bảng 2
Hình 14: Hiệu suất HPCG trên các bộ xử lý được liệt kê trong Bảng 2
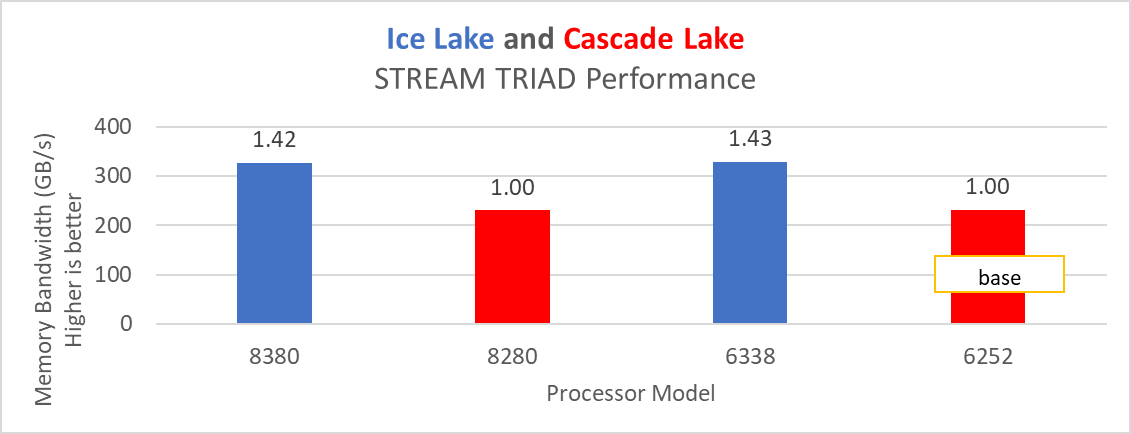 Hình 15: Hiệu suất kiểm tra STREAM TRIAD trên Bộ xử lý được liệt kê trong Bảng 2
Hình 15: Hiệu suất kiểm tra STREAM TRIAD trên Bộ xử lý được liệt kê trong Bảng 2
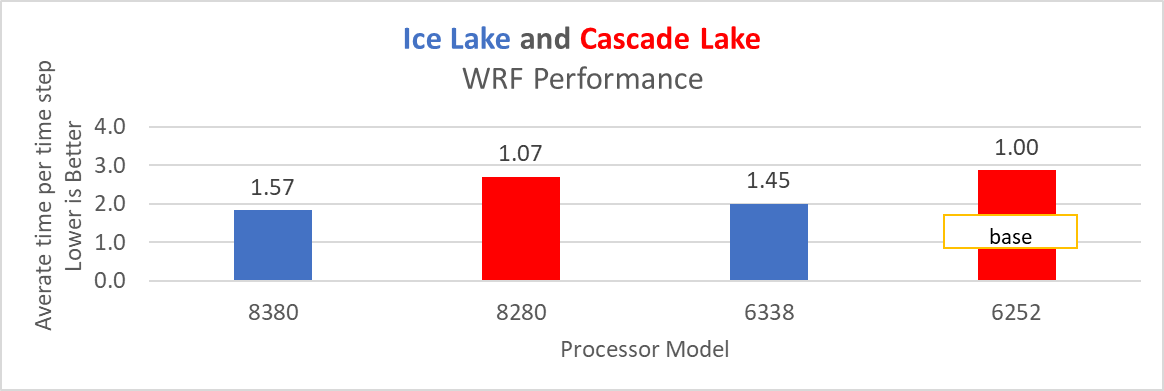 Hình 16: Hiệu suất WRF trên các Bộ xử lý được liệt kê trong Bảng 2
Hình 16: Hiệu suất WRF trên các Bộ xử lý được liệt kê trong Bảng 2
Ice Lake mang lại hiệu suất tốt hơn khoảng 38 phần trăm so với Cascade Lake với HPL trên mẫu bộ xử lý cao cấp nhất. Các điểm chuẩn giới hạn băng thông bộ nhớ như STREAM và HPCG (xem Hình 13 và Hình 14) mang lại hiệu suất cải thiện từ 42% đến 43% so với các bộ xử lý Cascade Lake cao cấp nhất được đề cập trong blog này.
Mức sử dụng năng lượng trung bình trong thời gian thực của các nền tảng Dell EMC PowerEdge (được liệt kê trong Bảng 1) được đo bằng các tiêu chuẩn tổng hợp được liệt kê trong blog này. Hình 17 so sánh dữ liệu sử dụng năng lượng từ nền tảng Cascade Lake và Ice Lake. Con số trên thanh biểu thị sự thay đổi công suất tương đối đối với công suất cơ sở (bộ xử lý Intel 6252 ở trạng thái không hoạt động) được đo.
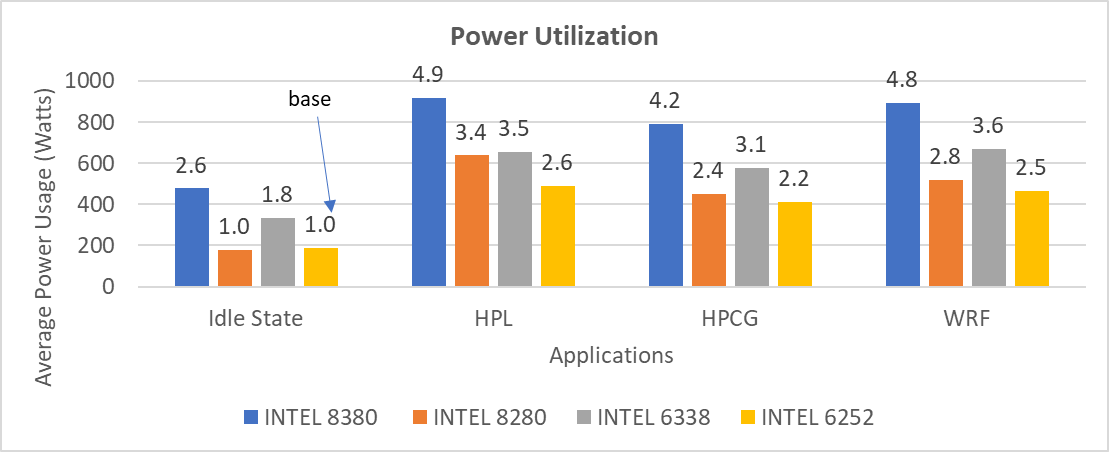
Hình 17: Mức sử dụng năng lượng trung bình trong quá trình chạy điểm chuẩn trên máy chủ Dell EMC PowerEdge (xem chi tiết trong Bảng 1)
Xem xét dữ liệu với cấu hình Tối ưu hóa hiệu suất với phép đo công suất tương ứng, các ứng dụng (tùy thuộc vào kiểu bộ xử lý) không thể mang lại hiệu suất trên mỗi watt tốt hơn trên nền tảng Ice Lake khi so sánh với nền tảng Cascade Lake.
Tóm tắt và công việc trong tương lai
Các máy chủ Dell EMC Power Edge dựa trên bộ xử lý Ice Lake, với các nâng cấp tính năng phần cứng đáng chú ý so với Cascade Lake, cho thấy mức tăng hiệu suất lên tới 47% đối với tất cả các tiêu chuẩn HPC được đề cập trong blog này. Siêu phân luồng nên được Vô hiệu hóa đối với các điểm chuẩn được đề cập trong blog này; đối với các khối lượng công việc khác, tùy chọn này phải được kiểm tra và kích hoạt khi thích hợp. Xem không gian này để biết các blog tiếp theo mô tả các nghiên cứu về hiệu suất ứng dụng trên cụm dựa trên bộ xử lý Ice Lake mới của chúng tôi.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...