
Trong bối cảnh phát triển nhanh chóng của AI, năm vừa qua không thể phủ nhận được đánh dấu là kỷ nguyên của Mô hình ngôn ngữ lớn (LLM), đặc biệt là trong lĩnh vực Generative AI (GenAI). Các mẫu như GPT-4 và Falcon đã thu hút trí tưởng tượng của chúng tôi, cho thấy tiềm năng vượt trội của những chiếc LLM này. Tuy nhiên, bên dưới khả năng biến đổi của họ là một thách thức đáng kể: cơn đói vô độ về tài nguyên tính toán.
Nhu cầu về điện toán: thúc đẩy đổi mới bằng sức mạnh tính toán
Các ứng dụng GenAI trải dài từ ngành truyền thông đến phát triển phần mềm, thúc đẩy sự đổi mới trong các ngành. Việc OpenAI phát hành GPT-3 là một bước ngoặt, thể hiện khả năng của các mô hình ngôn ngữ và tiềm năng cách mạng hóa mọi lĩnh vực của chúng. Một mặt, các công ty khởi nghiệp và gã khổng lồ công nghệ đã giới thiệu các mô hình nguồn đóng, cung cấp API để họ sử dụng, ví dụ như OpenAI và GPT-4 . Mặt khác, một cộng đồng nguồn mở tích cực đã xuất hiện, phát hành các mô hình mạnh mẽ như Falcon và Llama 2 . Những mô hình này, cả nguồn đóng và nguồn mở, đã thúc đẩy một làn sóng quan tâm, khiến các công ty chạy đua để sử dụng tiềm năng của chúng.
Mặc dù hứa hẹn của LLM là rất lớn nhưng chúng lại đi kèm với một thách thức đáng kể—việc tiếp cận các GPU hiệu suất cao. Các doanh nghiệp muốn triển khai các mô hình này trong trung tâm dữ liệu riêng tư hoặc môi trường đám mây của họ phải đối mặt với nhu cầu về sức mạnh GPU đáng kể. Những lo ngại về bảo mật càng thúc đẩy ưu tiên triển khai nội bộ, khiến khả năng truy cập GPU trở nên quan trọng.
Cơ sở hạ tầng cần thiết để hỗ trợ LLM thường bao gồm các GPU cao cấp được kết nối thông qua các giải pháp lưu trữ và kết nối nhanh. Những tài nguyên này không chỉ đắt và khan hiếm mà còn có nhu cầu cao, dẫn đến tắc nghẽn trong quá trình phát triển và triển khai máy học (ML). Việc điều phối các tài nguyên này một cách hiệu quả và cung cấp cho các nhóm khoa học dữ liệu và ML khả năng truy cập dễ dàng và có thể mở rộng trở thành một nhiệm vụ của Herculean.
Những thách thức với việc phân bổ GPU
Trong bối cảnh này, GPU là xương sống của sức mạnh tính toán thúc đẩy các mô hình ngôn ngữ khổng lồ này. Do nguồn tài nguyên tại chỗ và đám mây có sẵn hạn chế, cộng đồng nguồn mở đã thực hiện các bước để giải quyết thách thức này. Các thư viện như bit và byte (của Tim Dettmers) và ggml (của Georgi Gerganov) đã xuất hiện, sử dụng nhiều kỹ thuật tối ưu hóa khác nhau như lượng tử hóa để tinh chỉnh và triển khai các mô hình này trên các thiết bị cục bộ.
Tuy nhiên, những thách thức không chỉ giới hạn ở việc phát triển và triển khai mô hình. Các LLM này yêu cầu dung lượng GPU đáng kể để duy trì độ trễ thấp trong quá trình suy luận và thông lượng cao trong quá trình tinh chỉnh. Trong thế giới thực, nhu cầu về năng lực có nghĩa là phải có cơ sở hạ tầng phân bổ động tài nguyên GPU để xử lý các hoạt động tinh chỉnh và suy luận LLM, đồng thời đảm bảo hiệu quả và giảm thiểu lãng phí công suất.
Ví dụ: hãy cân nhắc tải LLama-7B với độ chính xác một nửa (float16). Mô hình như vậy yêu cầu bộ nhớ GPU khoảng 12GB ─ con số này thậm chí có thể thấp hơn khi sử dụng độ chính xác thấp hơn. Trong trường hợp GPU cao cấp, như GPU NVIDIA A100 có bộ nhớ 40 GB (hoặc 80 GB), chỉ dành riêng cho một kiểu máy duy nhất, sẽ dẫn đến lãng phí tài nguyên nghiêm trọng, đặc biệt là khi thực hiện ở quy mô lớn. Tài nguyên bị lãng phí không chỉ dẫn đến thiếu hiệu quả tài chính mà còn làm giảm năng suất của các nhóm khoa học dữ liệu và tăng lượng khí thải carbon do sử dụng không đúng mức các tài nguyên đang hoạt động trong thời gian dài.
Một số LLM lớn đến mức chúng phải được phân phối trên nhiều GPU hoặc nhiều máy chủ GPU. Hãy xem xét Falcon-180B với độ chính xác hoàn toàn. Một mô hình như vậy yêu cầu khoảng 720 GB và sử dụng hơn 16 GPU NVIDIA A100 với 40 GB mỗi GPU. Tinh chỉnh các mô hình như vậy và chạy chúng trong sản xuất đòi hỏi sức mạnh tính toán cực lớn cũng như những thách thức đáng kể về lập kế hoạch và điều phối . Những khối lượng công việc như vậy không chỉ yêu cầu cơ sở hạ tầng điện toán cao cấp mà còn cả bộ phần mềm hiệu năng cao cấp có thể phân phối những khối lượng công việc này một cách hiệu quả mà không bị tắc nghẽn.
Ngoài công việc đào tạo, việc phục vụ các mô hình này còn yêu cầu khả năng tự động hóa quy mô hiệu quả trên phần cứng. Khi có nhu cầu cao, các ứng dụng này phải có khả năng mở rộng quy mô lên tới hàng trăm bản sao một cách nhanh chóng, trong khi trong trường hợp nhu cầu thấp, chúng có thể được thu nhỏ xuống 0 để tiết kiệm chi phí.
Việc tối ưu hóa việc quản lý LLM cho tất cả các nhu cầu cụ thể này đòi hỏi phải có cái nhìn chi tiết về việc sử dụng và hiệu suất GPU cũng như chế độ xem lập lịch cấp cao cho khối lượng công việc tính toán chuyên sâu. Ví dụ: thật lãng phí nếu một model như LLama-7B (12 GB) chạy trên NVIDIA A100 (40 GB) với gần 60% dung lượng dự phòng thay vì sử dụng dung lượng còn lại này cho khối lượng công việc suy luận.
Tính đồng thời và khả năng mở rộng là rất cần thiết, cả khi xử lý nhiều mô hình tại chỗ tương đối nhỏ, mỗi mô hình đều được tinh chỉnh và điều chỉnh cho phù hợp với các trường hợp sử dụng cụ thể cũng như khi xử lý các mô hình có hiệu suất lớn cần sự phối hợp cẩn thận. Những thử thách độc đáo này đòi hỏi một công cụ điều phối tài nguyên như Run:ai để hoạt động trơn tru trên phần cứng của Dell. Giải pháp như vậy trao quyền cho các tổ chức tận dụng tối đa cơ sở hạ tầng GPU của họ, đảm bảo rằng mọi sức mạnh tính toán đều được sử dụng một cách hiệu quả. Bằng cách giải quyết những thách thức này và tối ưu hóa tài nguyên GPU, các tổ chức có thể khai thác toàn bộ tiềm năng của LLM và GenAI, thúc đẩy sự đổi mới trong nhiều ngành khác nhau.
Dell Technologies và Run:ai: giải pháp chung
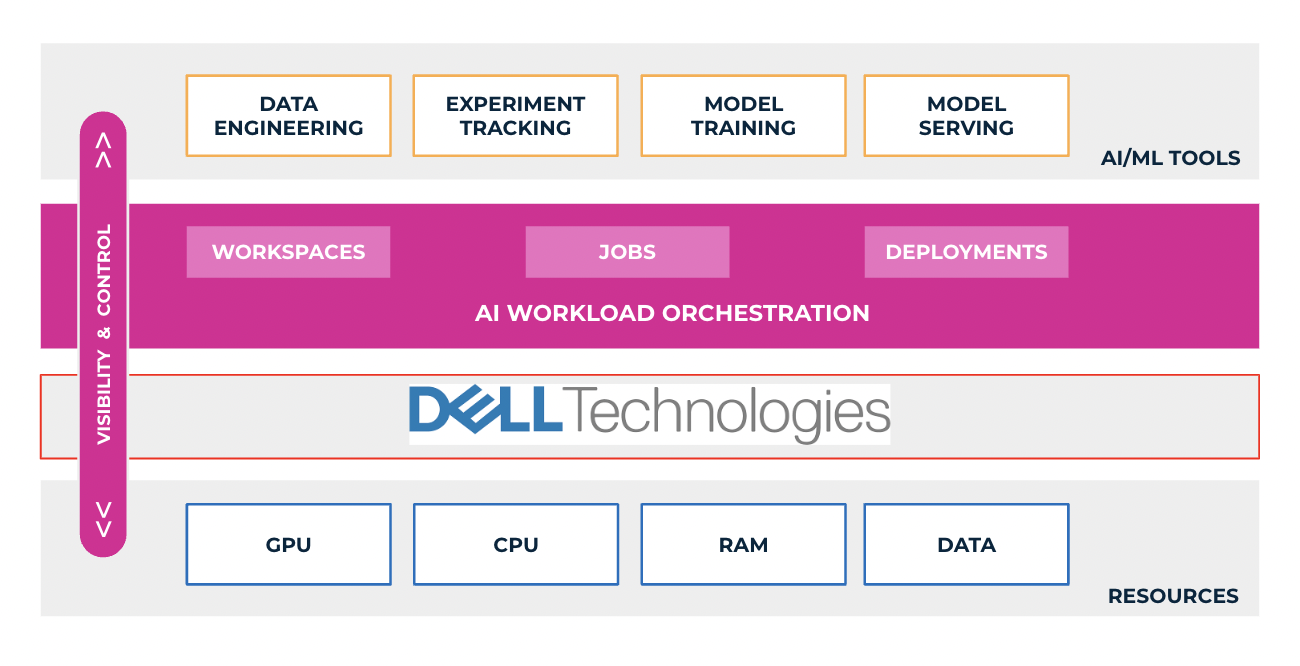
Để giải quyết những nút thắt cản trở việc áp dụng nhanh chóng GenAI trong các tổ chức, Run:ai, một giải pháp điều phối điện toán, hợp tác với Dell Technology.
Danh mục Giải pháp AI Generative của Dell, một bộ sản phẩm và dịch vụ toàn diện của Dell (máy chủ Dell PowerEdge XE9680, PowerEdge 760XA và PowerEdge XE8640) cộng tác với NVIDIA, cho phép khách hàng xây dựng các mô hình GenAI tại chỗ một cách nhanh chóng và an toàn, đẩy nhanh kết quả được cải thiện, và thúc đẩy những cấp độ trí tuệ mới. Thiết kế được xác thực của Dell cho Generative AI hiện hỗ trợ cả điều chỉnh và suy luận mô hình, cho phép người dùng triển khai các mô hình GenAI một cách nhanh chóng với cơ sở hạ tầng, phần mềm và dịch vụ của Dell đã được kiểm tra trước và đã được chứng minh để mang lại kết quả kinh doanh mang tính chuyển đổi với GenAI. Các thiết kế được xác thực tích hợp các giải pháp AI toàn diện bao gồm tất cả các thành phần quan trọng (máy chủ, mạng, bộ lưu trữ và phần mềm) cho hệ thống AI, trong khi Run:ai giới thiệu hai thành phần công nghệ chính giúp giải phóng tiềm năng thực sự của các mô hình AI này: GPU tối ưu hóa và hệ thống lập kế hoạch phức tạp cho khối lượng công việc đào tạo và suy luận. Việc mở rộng các phương pháp tiếp cận Dell GenAI với tính năng phối hợp Run:ai cho phép khách hàng tối ưu hóa các hoạt động của GenAI và AI để xây dựng và đào tạo các mô hình AI cũng như chạy suy luận với tốc độ và hiệu quả cao hơn.
Điện toán được tối ưu hóa bằng AI: tối đa hóa việc sử dụng GPU
Dell Technologies cung cấp một loạt máy chủ PowerEdge được tối ưu hóa về khả năng tăng tốc, được thiết kế dành riêng cho khối lượng công việc hiệu suất cao như AI và các trường hợp sử dụng có yêu cầu cao trong AI tổng hợp, như một phần của danh mục máy chủ mở rộng hỗ trợ nhiều GPU NVIDIA khác nhau. Máy chủ Dell PowerEdge cải tiến khả năng tính toán được tăng tốc để thúc đẩy kết quả khối lượng công việc AI nâng cao với thông tin chi tiết, suy luận, đào tạo và trực quan hóa tốt hơn. Tuy nhiên, một trong những thách thức chính trong việc đào tạo và triển khai LLM là việc sử dụng GPU. Cùng với các máy chủ Dell PowerEdge, lớp tối ưu hóa GPU của Run:ai hỗ trợ các tính năng như phân chia GPU và đăng ký vượt mức GPU. Những tính năng này đảm bảo rằng nhiều khối lượng công việc (đào tạo và suy luận), ngay cả các mô hình nhỏ, có thể chạy hiệu quả trên cùng một GPU. Bằng cách tận dụng tốt hơn các tài nguyên GPU hiện có, chi phí sẽ giảm và hạn chế tắc nghẽn.
Lập kế hoạch nâng cao: quản lý khối lượng công việc hiệu quả
Hệ thống lập lịch nâng cao của Run:ai tích hợp hoàn toàn vào môi trường Kubernetes trên máy chủ PowerEdge. Nó được thiết kế để giải quyết những vấn đề phức tạp phát sinh khi nhiều nhóm và người dùng chia sẻ một cụm GPU và khi chạy khối lượng công việc đa GPU hoặc nhiều nút lớn. Bộ lập lịch tối ưu hóa việc phân bổ tài nguyên, đảm bảo sử dụng GPU hiệu quả giữa các khối lượng công việc khác nhau, bao gồm đào tạo, tinh chỉnh và suy luận.
Tự động điều chỉnh quy mô và tối ưu hóa GPU cho khối lượng công việc suy luận
Chức năng tự động điều chỉnh quy mô của Run:ai cho phép điều chỉnh linh hoạt số lượng bản sao, cho phép mở rộng quy mô hiệu quả dựa trên nhu cầu. Trong thời điểm khối lượng công việc tăng lên, Run:ai sử dụng tối ưu GPU có sẵn, mở rộng quy mô các bản sao để đáp ứng yêu cầu về hiệu suất. Ngược lại, trong thời kỳ nhu cầu thấp, số lượng bản sao có thể giảm xuống bằng 0, giảm thiểu việc sử dụng tài nguyên và dẫn đến tiết kiệm chi phí. Mặc dù có thể có độ trễ khởi động nguội ngắn trong yêu cầu đầu tiên, nhưng phương pháp này cung cấp giải pháp linh hoạt và hiệu quả để thích ứng với nhu cầu suy luận đang thay đổi đồng thời tối ưu hóa chi phí.
Ngoài khả năng tự động điều chỉnh quy mô, việc triển khai các mô hình suy luận bằng Run:ai là một quá trình đơn giản. Người dùng nội bộ có thể dễ dàng triển khai các mô hình của họ và truy cập chúng thông qua các URL được quản lý hoặc giao diện web thân thiện với người dùng như Gradio và Streamlit. Quy trình triển khai hợp lý này tạo điều kiện thuận lợi cho việc chia sẻ và trình bày các LLM đã triển khai, thúc đẩy sự cộng tác và mang lại trải nghiệm liền mạch cho các bên liên quan.
Mạng AI
Để đạt được thông lượng cao trong quá trình đào tạo nhiều nút và độ trễ thấp khi lưu trữ một mô hình trên nhiều máy, hầu hết các mô hình GenAI đều yêu cầu khả năng kết nối mạng mạnh mẽ và hiệu suất cao trên phần cứng, đây là lúc các khả năng và dịch vụ kết nối mạng của Dell phát huy tác dụng. Mạng kết nối các nút điện toán với nhau để tạo điều kiện liên lạc trong quá trình đào tạo và hội thảo phân tán. Dell PowerSwitch Z-series là các thiết bị chuyển mạch trung tâm dữ liệu hiệu suất cao, mở và có thể mở rộng, lý tưởng cho AI tổng hợp, cũng như các thiết bị chuyển mạch NVIDIA Quantum InfiniBand để kết nối nhanh hơn.
Truy cập nhanh vào dữ liệu của bạn
Dữ liệu là thành phần quan trọng cho từng phần của các bước phát triển và triển khai. Bộ lưu trữ Dell PowerScale hỗ trợ khối lượng công việc AI đòi hỏi khắt khe nhất bằng các giải pháp lưu trữ tệp NVMe hoàn toàn flash mang lại hiệu suất và hiệu quả cao trong một kiểu dáng nhỏ gọn. PowerScale là nền tảng lưu trữ hàng đầu trong ngành được xây dựng nhằm mục đích xử lý lượng lớn dữ liệu phi cấu trúc, lý tưởng để hỗ trợ các kiểu dữ liệu cần thiết cho AI tổng hợp.
Các công cụ LLM được sắp xếp hợp lý
Để đơn giản hóa trải nghiệm cho các nhà nghiên cứu và kỹ sư ML, Run:ai cung cấp một bộ công cụ và khung. Họ loại bỏ sự phức tạp của cơ sở hạ tầng GPU bằng các giao diện như giao diện dòng lệnh, giao diện người dùng và API trên phần cứng Dell. Với những công cụ này, các mô hình đào tạo, tinh chỉnh và triển khai trở thành các quy trình đơn giản, nâng cao năng suất và giảm thời gian tiếp thị. Là một nhà khoa học dữ liệu, bạn có thể lấy các mô hình được đào tạo trước từ trung tâm mô hình Huggingface và bắt đầu làm việc với chúng bằng IDE yêu thích của bạn và thử nghiệm các công cụ quản lý trong vài phút, một minh chứng cho tính hiệu quả và dễ dàng của giải pháp Dell và Run:ai.
Lợi ích của giải pháp Dell và Run:ai đối với khách hàng
Bây giờ chúng ta đã khám phá những thách thức do LLM đặt ra và giải pháp chung của Dell Technologies và Run:ai đối với những tắc nghẽn này, hãy cùng đi sâu vào những lợi ích mà mối quan hệ hợp tác giữa Dell Technologies và Run:ai này mang lại cho khách hàng:
1. Tăng tốc thời gian đưa sản phẩm ra thị trường
Sự kết hợp giữa các giải pháp lập kế hoạch và tối ưu hóa GPU của Run:ai, cùng với cơ sở hạ tầng mạnh mẽ của Dell, giúp tăng tốc đáng kể thời gian tiếp thị các sáng kiến AI. Bằng cách hợp lý hóa việc triển khai và quản lý LLM, các tổ chức có thể nhanh chóng tận dụng khoản đầu tư AI của mình.
2. Nâng cao năng suất
Các nhóm kỹ thuật ML và khoa học dữ liệu, thường không quen với sự phức tạp của cơ sở hạ tầng AI, giờ đây có thể tập trung vào những gì họ làm tốt nhất: xây dựng và tinh chỉnh các mô hình. Các công cụ của Run:ai đơn giản hóa quy trình, giảm thời gian học tập và cải thiện năng suất.
3. Hiệu quả chi phí
Tối ưu hóa việc sử dụng GPU không chỉ mang lại hiệu suất mà còn mang lại hiệu quả về chi phí. Bằng cách chạy nhiều khối lượng công việc trên cùng một GPU, các tổ chức có thể đạt được hiệu quả chi phí tốt hơn, tận dụng tối đa cơ sở hạ tầng của mình, từ đó giúp các sáng kiến AI trở nên khả thi hơn về mặt tài chính.
4. Tăng khả năng mở rộng và tính khả dụng của GPU
Hệ thống lập kế hoạch nâng cao của Run:ai đảm bảo khối lượng công việc được quản lý hiệu quả, ngay cả khi có nhu cầu cao điểm. Khả năng mở rộng này rất quan trọng đối với các tổ chức cần cung cấp mô hình ngôn ngữ theo thời gian thực cho cơ sở người dùng ngày càng tăng. Ngoài ra, thành phần lập lịch đảm bảo phân bổ tài nguyên GPU một cách công bằng và tối ưu giữa nhiều người dùng, nhóm và nhiệm vụ, ngăn ngừa tắc nghẽn và tranh chấp tài nguyên, đồng thời tăng tính khả dụng của GPU để cho phép nhiều người dùng, nhóm và dịch vụ AI hơn có quyền truy cập và sử dụng GPU có sẵn nguồn lực một cách hiệu quả.
5. Giải phóng sự đổi mới
Giải pháp này trao quyền cho các nhóm doanh nghiệp đổi mới và thử nghiệm LLM và GenAI mà không bị cản trở bởi sự phức tạp của cơ sở hạ tầng. Các nhà nghiên cứu và kỹ sư ML có thể dễ dàng tinh chỉnh và triển khai các mô hình bằng các công cụ trừu tượng hóa, thúc đẩy sự đổi mới và khám phá trong các dự án AI.
Bản tóm tắt
Giải pháp chung do Dell Technologies và Run:ai cung cấp giải quyết những thách thức quan trọng mà các tổ chức phải đối mặt khi tăng cường GenAI cho nhu cầu kinh doanh của họ và làm việc với LLM. Bằng cách tăng cường khả năng truy cập GPU, tối ưu hóa việc lập kế hoạch, hợp lý hóa quy trình làm việc và tiết kiệm chi phí, giải pháp này cho phép các doanh nghiệp khai thác tối đa tiềm năng của LLM trong các ứng dụng GenAI đồng thời đơn giản hóa các thách thức. Với việc các sáng kiến AI ngày càng trở nên quan trọng trong thế giới ngày nay, sự hợp tác này mang đến cho các doanh nghiệp những cách thức mới để tự động hóa và đơn giản hóa chiến lược GenAI của họ cũng như thúc đẩy nhiều đổi mới kinh doanh hơn.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...