
Tin tức
Hiệu suất Deep Learning với MLPerf Inference v0.7 Benchmark
Bản tóm tắt
MLPerf là bộ điểm chuẩn đo lường hiệu suất của khối lượng công việc Học máy (ML). Nó tập trung vào các khía cạnh quan trọng nhất của vòng đời ML:
- Đào tạo —Bộ điểm chuẩn đào tạo MLPerf đo tốc độ hệ thống có thể đào tạo các mô hình ML.
- Suy luận —Điểm chuẩn suy luận MLPerf đo tốc độ một hệ thống có thể thực hiện suy luận ML bằng cách sử dụng một mô hình được đào tạo trong các tình huống triển khai khác nhau.
Blog này phác thảo các kết quả đã đóng của trung tâm dữ liệu suy luận MLPerf v0.7 trên các máy chủ Dell EMC PowerEdge R7525 và DSS8440 với GPU NVIDIA chạy các tiêu chuẩn suy luận MLPerf . Kết quả của chúng tôi cho thấy hiệu suất suy luận tối ưu cho các hệ thống và cấu hình mà chúng tôi đã chọn để chạy điểm chuẩn suy luận.
Trong khung đánh giá suy luận MLPerf, trình tạo tải LoadGen gửi các truy vấn suy luận đến hệ thống đang được kiểm tra (SUT). Trong trường hợp của chúng tôi, các SUT được lựa chọn cẩn thận các máy chủ PowerEdge R7525 và DSS8440 với các cấu hình GPU khác nhau. SUT sử dụng chương trình phụ trợ (ví dụ: TensorRT, TensorFlow hoặc PyTorch) để thực hiện suy luận và gửi kết quả trở lại LoadGen.
MLPerf đã xác định bốn kịch bản khác nhau cho phép thử nghiệm đại diện cho nhiều nền tảng suy luận và trường hợp sử dụng khác nhau . Sự khác biệt chính giữa các kịch bản này dựa trên cách gửi và nhận truy vấn:
- Ngoại tuyến —Một truy vấn với tất cả các mẫu được gửi đến SUT. SUT có thể gửi lại kết quả một lần hoặc nhiều lần theo bất kỳ thứ tự nào. Số liệu hiệu suất là mẫu mỗi giây.
- Máy chủ —Các truy vấn được gửi đến SUT theo phân phối Poisson (để lập mô hình các sự kiện ngẫu nhiên trong thế giới thực). Một truy vấn có một mẫu. Chỉ số hiệu suất là số truy vấn mỗi giây (QPS) trong giới hạn độ trễ.
- Single-stream —Một mẫu cho mỗi truy vấn được gửi đến SUT. Truy vấn tiếp theo không được gửi cho đến khi nhận được phản hồi trước đó. Chỉ số hiệu suất là độ trễ phân vị thứ 90.
- Đa luồng —Một truy vấn có N mẫu được gửi với một khoảng thời gian cố định. Chỉ số hiệu suất là N tối đa khi độ trễ của tất cả truy vấn nằm trong giới hạn độ trễ.
Quy tắc suy luận MLPerf mô tả các quy tắc suy luận chi tiết và các ràng buộc về độ trễ. Blog này chỉ tập trung vào các kịch bản Ngoại tuyến và Máy chủ, được thiết kế cho môi trường trung tâm dữ liệu. Các kịch bản đơn luồng và đa luồng được thiết kế cho cài đặt không phải trung tâm dữ liệu (cạnh và IoT).
Kết quả suy luận MLPerf có thể được gửi theo một trong các bộ phận sau:
- Bộ phận đóng —Bộ phận đóng nhằm mục đích cung cấp sự so sánh “táo với táo” về nền tảng phần cứng hoặc khung phần mềm. Nó yêu cầu sử dụng cùng một mô hình và trình tối ưu hóa như triển khai tham chiếu.
Bộ phận Đóng yêu cầu sử dụng tiền xử lý, hậu xử lý và mô hình tương đương với triển khai tham chiếu hoặc thay thế. Nó cho phép hiệu chuẩn để lượng tử hóa và không cho phép đào tạo lại. MLPerf cung cấp triển khai tham chiếu cho từng điểm chuẩn. Việc triển khai điểm chuẩn phải sử dụng một mô hình tương đương, như được định nghĩa trong Quy tắc suy luận MLPerf , với mô hình được sử dụng trong quá trình triển khai tham chiếu.
- Bộ phận mở —Bộ phận mở nhằm thúc đẩy các mô hình và trình tối ưu hóa nhanh hơn, đồng thời cho phép mọi phương pháp ML có thể đạt được chất lượng mục tiêu. Nó cho phép sử dụng tiền xử lý hoặc hậu xử lý tùy ý và mô hình, bao gồm đào tạo lại. Việc triển khai điểm chuẩn có thể sử dụng một mô hình khác để thực hiện cùng một nhiệm vụ.
Để cho phép so sánh toàn diện các kết quả của Dell EMC và cho phép khách hàng cũng như đối tác của chúng tôi lặp lại kết quả của chúng tôi, chúng tôi đã chọn tiến hành thử nghiệm trong bộ phận Đóng, như thể hiện trong các kết quả trong blog này.
Tiêu chí gửi kết quả điểm chuẩn MLPerf Inference v0.7
Bảng sau đây mô tả các kỳ vọng về điểm chuẩn MLPerf:
Bảng 1: Các điểm chuẩn có sẵn trong bộ phận Đóng dành cho suy luận MLPerf v0.7 cùng với kỳ vọng của chúng.
| Diện tích | Nhiệm vụ | Người mẫu | tập dữ liệu | kích thước QSL | chất lượng yêu cầu | Giới hạn độ trễ bắt buộc của máy chủ |
| Tầm nhìn | phân loại hình ảnh | Resnet50-v1.5 | Bộ dữ liệu hình ảnh tiêu chuẩn (224 x 224 x 3) | 1024 | 99% của FP32 (76,46%) | 15 mili giây |
| Tầm nhìn | Phát hiện đối tượng (lớn) | SSD-ResNet34 | COCO (1200×1200) | 64 | 99% của FP32 (0,20 mAP) | 100 mili giây |
| Tầm nhìn | Phân vùng hình ảnh y tế | UNET 3D | Áo ngực 2019 (224x224x160) | 16 | 99% của FP32 và 99,9% của FP32 (điểm DICE trung bình là 0,85300) | không áp dụng |
| Lời nói | Chuyển giọng nói thành văn bản | RNNT | Librispeech dev-clean (mẫu < 15 giây) | 2513 | 99% của FP32 (1 – WER, trong đó WER=7,452253714852645%) | 1000 mili giây |
| Ngôn ngữ | xử lý ngôn ngữ | BERT | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% của FP32 và 99,9% của FP32 (f1_score=90,874%) | 130 mili giây |
| thương mại | sự giới thiệu | DLRM | Nhật ký lần nhấp 1 TB | 204800 | 99% của FP32 và 99,9% của FP32 (AUC=80,25%) | 30 mili giây |
Đối với bất kỳ điểm chuẩn nào, điều cần thiết là kết quả gửi phải đáp ứng tất cả các thông số kỹ thuật trong bảng này. Ví dụ: nếu chúng tôi chọn mô hình Resnet50 thì nội dung gửi phải đáp ứng độ chính xác mục tiêu là 76,46 phần trăm và độ trễ phải nằm trong khoảng 15 mili giây đối với tập dữ liệu hình ảnh tiêu chuẩn có kích thước 224 x 224 x 3.
Mỗi điểm chuẩn của trung tâm dữ liệu yêu cầu các kịch bản trong bảng sau:
Bảng 2: Nhiệm vụ và các kịch bản yêu cầu tương ứng cho bộ điểm chuẩn trung tâm dữ liệu trong suy luận MLPerf v0.7.
| Diện tích | Nhiệm vụ | kịch bản bắt buộc |
| Tầm nhìn | phân loại hình ảnh | Bộ trợ giúp không kết nối |
| Tầm nhìn | Phát hiện đối tượng (lớn) | Bộ trợ giúp không kết nối |
| Tầm nhìn | Phân vùng hình ảnh y tế | ngoại tuyến |
| Lời nói | Chuyển giọng nói thành văn bản | Bộ trợ giúp không kết nối |
| Ngôn ngữ | xử lý ngôn ngữ | Bộ trợ giúp không kết nối |
| thương mại | sự giới thiệu | Bộ trợ giúp không kết nối |
cấu hình SUT
Chúng tôi đã chọn các máy chủ sau với các loại GPU NVIDIA khác nhau làm SUT của mình để tiến hành các điểm chuẩn suy luận trung tâm dữ liệu:
Kết quả
Phần sau đây cung cấp kết quả của điểm chuẩn MLPerf Inference v0.7.
Đối với kịch bản Ngoại tuyến, chỉ số hiệu suất là Mẫu ngoại tuyến mỗi giây. Đối với kịch bản Máy chủ, chỉ số hiệu suất là số truy vấn mỗi giây (QPS). Nói chung, các số liệu đại diện cho thông lượng.
Các biểu đồ sau bao gồm các chỉ số hiệu suất cho các kịch bản Ngoại tuyến và Máy chủ. Một thông lượng cao hơn là một kết quả tốt hơn.
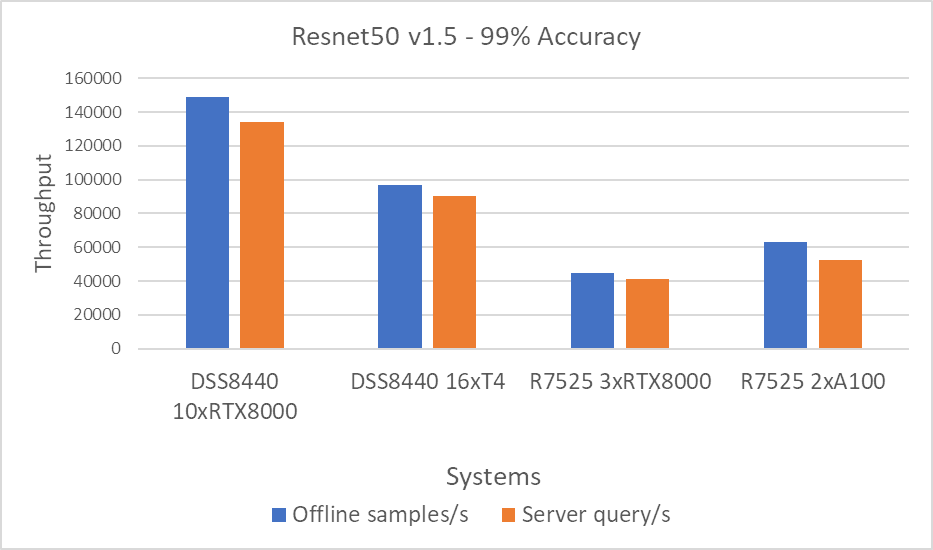
Hình 1: Kịch bản máy chủ và ngoại tuyến Resnet50 v1.5 với mục tiêu chính xác 99 phần trăm
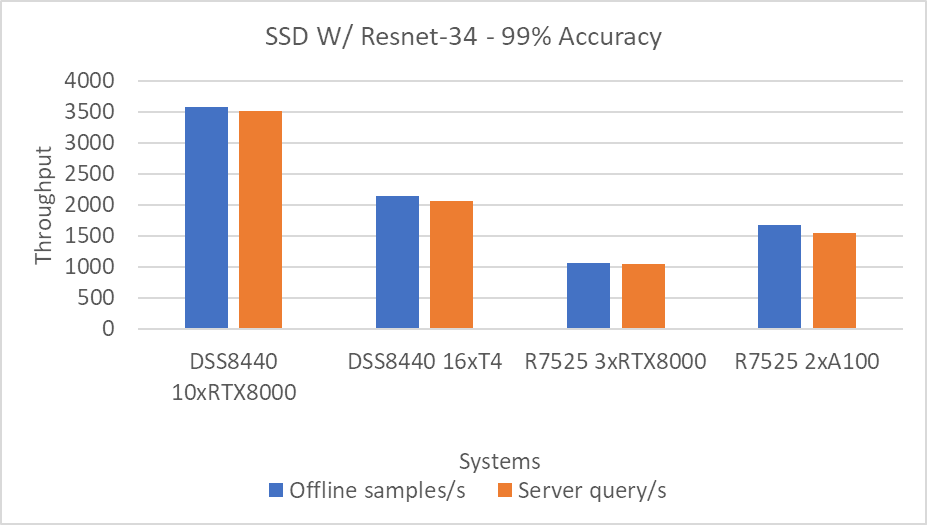
Hình 2: Kịch bản SSD w/Resnet34 Offline và Máy chủ với mục tiêu chính xác 99 phần trăm
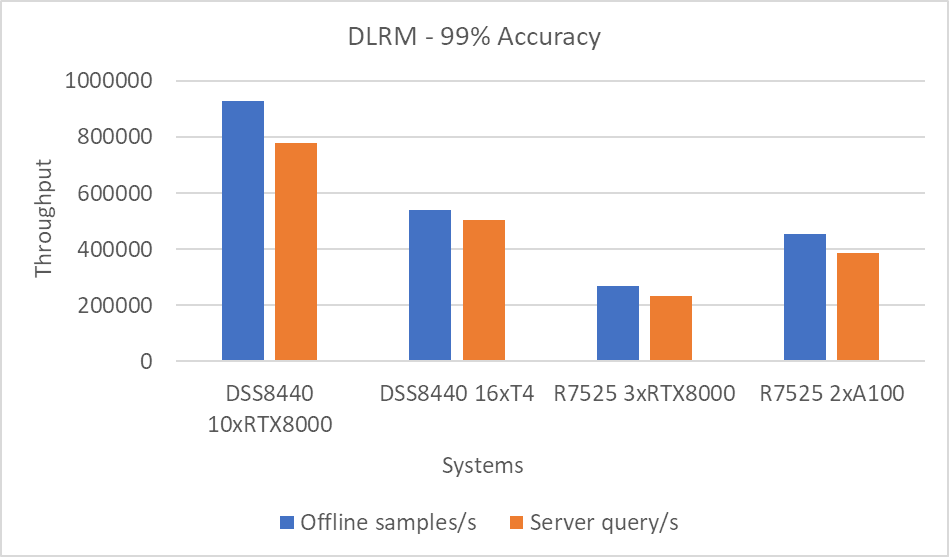
Hình 3: Kịch bản máy chủ và ngoại tuyến DLRM với mục tiêu chính xác 99 phần trăm

Hình 4: Kịch bản Máy chủ và Ngoại tuyến DLRM với mục tiêu chính xác 99,9 phần trăm
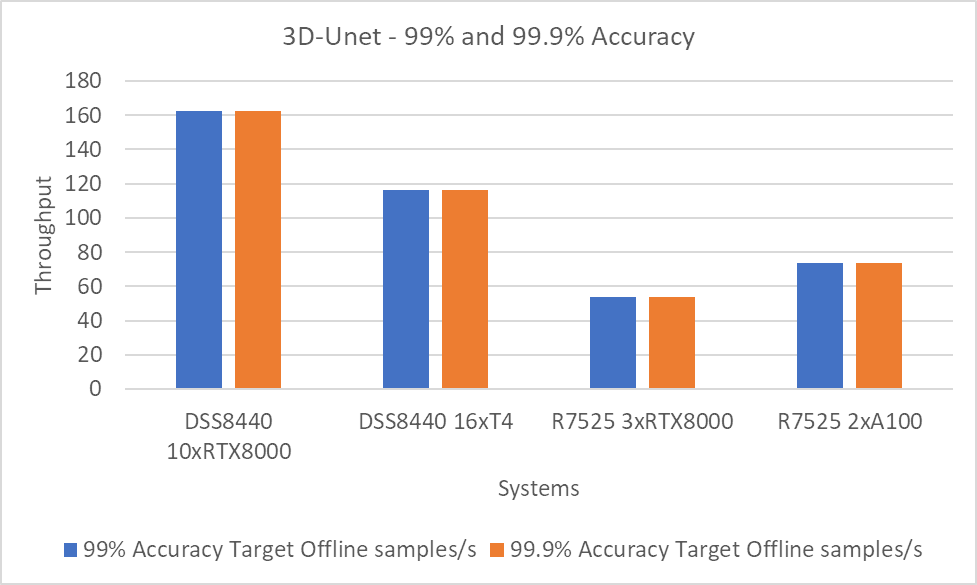
Hình 5: 3D-Unet sử dụng các mục tiêu có độ chính xác 99 và 99,9 phần trăm.
Lưu ý : Các mục tiêu về độ chính xác 99 và 99,9 phần trăm với DLRM và 3D-Unet cho thấy hiệu suất giống nhau vì các mục tiêu về độ chính xác đã được đáp ứng sớm.
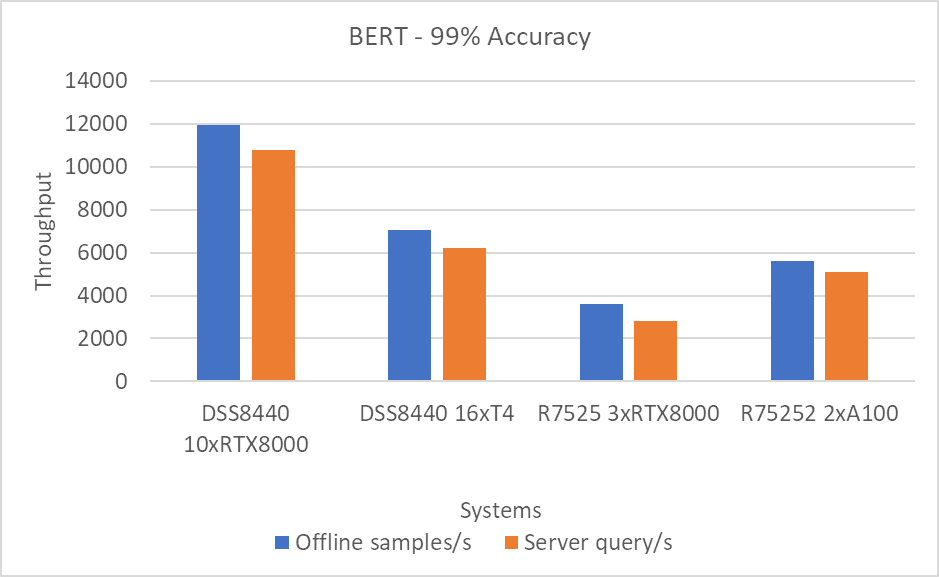
Hình 6: Kịch bản BERT Offline và Server với mục tiêu chính xác 99 phần trăm
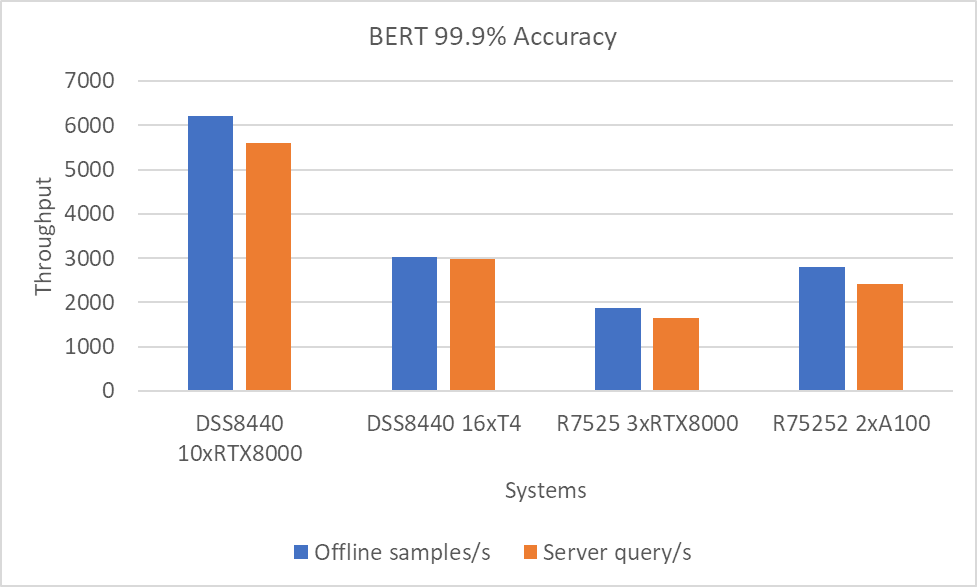
Hình 7: Kịch bản Máy chủ và Ngoại tuyến BERT với mục tiêu chính xác 99,9 phần trăm.
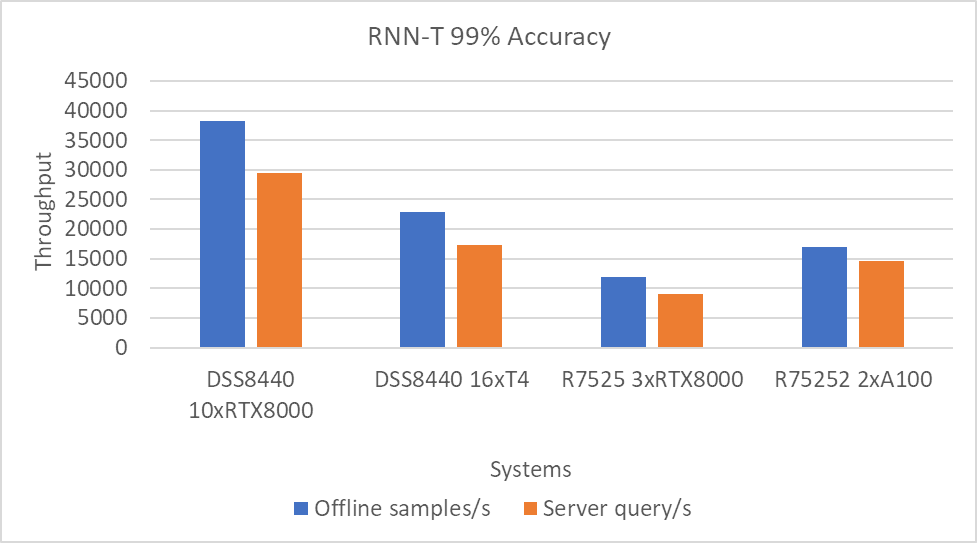
Hình 8: Kịch bản máy chủ và ngoại tuyến RNN-T với mục tiêu chính xác 99 phần trăm
Hiệu suất trên mỗi GPU
Để ước tính hiệu suất trên mỗi GPU, chúng tôi đã chia kết quả trong phần trước cho số lượng GPU trên hệ thống. Chúng tôi quan sát thấy rằng hiệu suất tăng tỷ lệ tuyến tính khi chúng tôi tăng số lượng GPU. Nghĩa là, khi chúng tôi thêm nhiều thẻ hơn, hiệu suất của hệ thống được nhân với số lượng thẻ nhân với hiệu suất trên mỗi thẻ. Chúng tôi sẽ cung cấp thông tin này trong một bài đăng blog tiếp theo.
Hình dưới đây cho thấy hiệu suất gần đúng trên mỗi GPU:
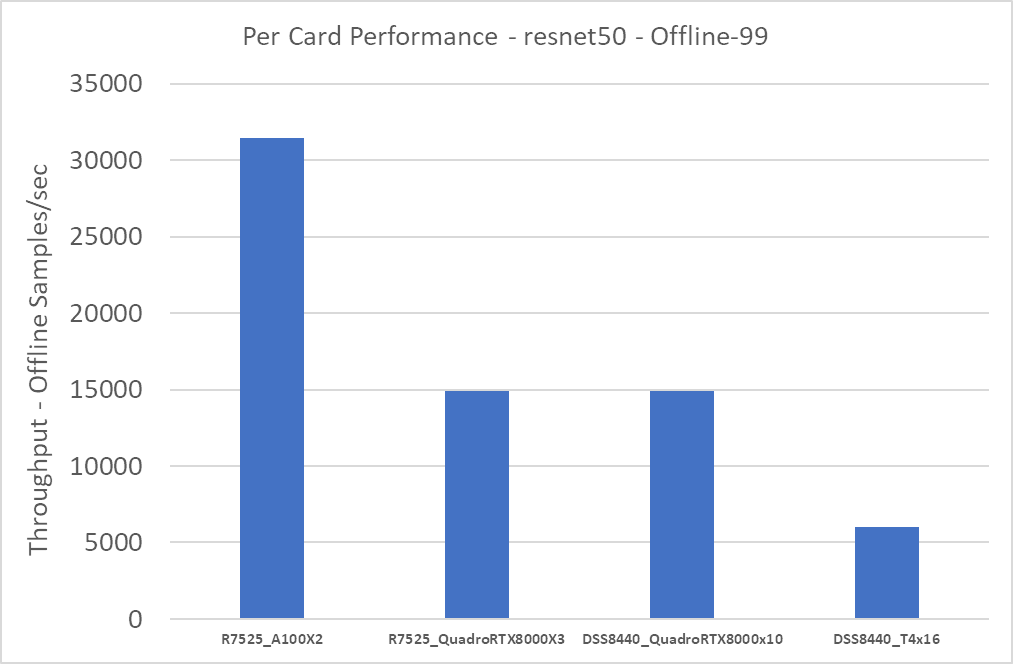
Hình 9: Hiệu suất xấp xỉ trên mỗi thẻ cho kịch bản Resnet50 Offline
Cả hai hệ thống R7525_QuadroRTX8000x3 và DSS8440_QuadroRTX8000x10 đều sử dụng thẻ RTX8000. Do đó, hiệu suất trên mỗi thẻ của hai hệ thống này là như nhau. Thẻ A100 mang lại hiệu suất cao nhất; thẻ T4 mang lại hiệu suất thấp nhất.
Sự kết luận
Trong blog này, chúng tôi đã định lượng hiệu suất suy luận MLPerf v0.7 trên máy chủ Dell EMC DSS8440 và PowerEdge R7525 với GPU NVIDIA A100, RTX8000 và T4 với Resnet50, SSD w/Resnet34, DLRM, BERT, RNN-T và 3D-Unet điểm chuẩn. Các điểm chuẩn này mở rộng các nhiệm vụ từ tầm nhìn đến đề xuất. Các máy chủ Dell EMC mang lại hiệu suất suy luận hàng đầu được chuẩn hóa theo số lượng bộ xử lý trong số các kết quả có sẵn trên thị trường. Chúng tôi nhận thấy rằng GPU A100 mang lại hiệu suất tổng thể tốt nhất và hiệu suất trên mỗi watt tốt nhất trong khi GPU RTX mang lại hiệu suất trên mỗi đô la tốt nhất. Nếu bị hạn chế trong môi trường năng lượng hạn chế, GPU T4 mang lại hiệu suất trên mỗi watt tốt nhất.
Bước tiếp theo
Trong các blog trong tương lai, chúng tôi dự định mô tả cách:
- Chạy và điều chỉnh hiệu năng suy luận MLPerf v0.7
- Kích thước hệ thống (cấu hình máy chủ và GPU) một cách chính xác dựa trên loại khối lượng công việc (khu vực và nhiệm vụ)
- Hiểu các số liệu về mỗi thẻ, mỗi watt và mỗi đô la để xác định nhu cầu cơ sở hạ tầng của bạn
- Hiểu kết quả đào tạo MLPerf trên các máy chủ R7525 PowerEdge được phát hành gần đây với GPU NVIDIA A100
Bài viết mới cập nhật
PowerFlex và PowerProtect: Giữ cho Vương quốc CNTT của bạn không có Ransomware
“Tồn tại hay không tồn tại? Đó là câu hỏi.” Đáng ...
Giới thiệu về nền tảng Unified PowerFlex Manager
Chúng ta đều đã nghe câu nói nổi tiếng rằng “Thay ...
Giới thiệu NVMe qua TCP (NVMe/TCP) trong PowerFlex 4.0
Bất kỳ ai đã sử dụng hoặc quản lý PowerFlex đều ...
Khả năng dịch vụ tập tin mới của PowerFlex 4.0
“Chỉ cần lưu trữ”, họ nói, và câu hỏi hiển nhiên ...