

Tăng tốc khối lượng công việc HPC với NVIDIA A100 NVLink trên Dell PowerEdge XE8545
GPU NVIDIA A100
Ba năm sau khi ra mắt GPU Tesla V100, NVIDIA mới đây đã công bố GPU A100 dành cho trung tâm dữ liệu mới nhất của mình , được xây dựng trên kiến trúc Ampere. A100 có sẵn ở hai yếu tố hình thức, PCIe và SXM4, cho phép giao tiếp giữa GPU với GPU qua PCIe hoặc NVLink. Phiên bản NVLink còn được gọi là GPU A100 SXM4 và có sẵn trên bo mạch máy chủ HGX A100 .
Như bạn mong đợi, Phòng thí nghiệm Đổi mới đã kiểm tra hiệu suất của GPU A100 trong một nền tảng mới. Máy chủ PowerEdge XE8545 4U mới của Dell Technologies hỗ trợ các GPU này với hệ số dạng NVLink SXM4 và CPU EPYC thế hệ thứ 3 của AMD ổ cắm kép ( tên mã Milan ). Nền tảng này hỗ trợ tốc độ PCIe Gen 4, tối đa 10 ổ đĩa cục bộ và tối đa 16 khe cắm DIMM chạy ở tốc độ 3200 MT/s. CPU Milan có sẵn với tối đa 64 lõi vật lý trên mỗi CPU.
Phiên bản PCIe của A100 có thể được đặt trong PowerEdge R7525, cũng hỗ trợ CPU AMD EPYC, tối đa 24 ổ đĩa và tối đa 16 khe cắm DIMM chạy ở tốc độ 3200MT/s. Blog này so sánh hiệu suất của hệ thống A100-PCIe với hệ thống A100-SXM4.

Hình 1: Máy chủ PowerEdge XE8545
Một blog trước đây đã thảo luận về hiệu suất của GPU NVIDIA A100-PCIe so với GPU NVIDIA Tesla V100-PCIe tiền nhiệm của nó trong nền tảng PowerEdge R7525.
Bảng sau đây cho biết thông số kỹ thuật của GPU NVIDIA A100 và V100.
Bảng 1: GPU NVIDIA A100 và V100 với hệ số dạng PCIe và SXM4
| Yếu tố hình thức | PCIe | SXM (NVIDIA NVLink) | ||
| Loại NVIDIA | A100 | v100 | A100 | v100 |
| kiến trúc GPU | Ampe | Volta | Ampe | Volta |
| bộ nhớ GPU | 40 GB | 32 GB | 40 GB | 32 GB |
| Băng thông bộ nhớ GPU | 1555GB/giây | 900 GB/giây | 1555GB/giây | 900 GB/giây |
| Đỉnh FP64 | 9.7 TFLOP | 7 TFLOPS | 9.7 TFLOP | 7.8 TFLOP |
| Lõi Tenor đỉnh FP64 | 19,5 TFLOP | không áp dụng | 19,5 TFLOP | không áp dụng |
| Đồng hồ cơ sở GPU | 765 MHz | 1230 MHz | 1095 MHz | 1290 MHz |
| Đồng hồ tăng cường GPU | 1410 MHz | 1380 MHz | 1410 MHz | 1530 MHz |
| Tốc độ NVLink | 600GB/giây | không áp dụng | 600GB/giây | 300GB/giây |
| Tiêu thụ điện tối đa | 250W | 250W | 400W | 300 W |
Từ Bảng 1, chúng tôi thấy rằng A100 cung cấp băng thông bộ nhớ được cải thiện 42 phần trăm và FLOPS có độ chính xác kép cao hơn từ 20 đến 30 phần trăm khi so sánh với GPU Tesla V100. Mặc dù GPU A100-PCIe tiêu thụ cùng một lượng điện năng như GPU V100-PCIe, phiên bản NVLink của GPU A100 tiêu thụ nhiều điện năng hơn 25% so với GPU V100.
Các GPU được kết nối như thế nào trong các máy chủ PowerEdge?
Sự hiểu biết về kiến trúc máy chủ rất hữu ích trong việc xác định hành vi của bất kỳ ứng dụng nào. Máy chủ PowerEdge XE8545 là một máy chủ được tối ưu hóa cho máy gia tốc với bốn GPU A100-SMX4 được kết nối với NVLink thế hệ thứ ba, như thể hiện trong hình dưới đây.
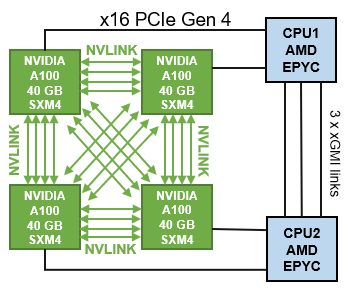
Hình 2: Kết nối CPU-GPU PowerEdge XE8545
Trong GPU A100, mỗi làn NVLink hỗ trợ tốc độ dữ liệu 50x 4 Gbit/s theo mỗi hướng. Tổng số làn NVLink tăng từ 6 làn trong GPU V100 lên 12 làn trong GPU A100, hiện mang lại tổng tốc độ 600 GB/giây. Khối lượng công việc có thể tận dụng băng thông giao tiếp giữa GPU với GPU cao hơn có thể được hưởng lợi từ các liên kết NVLink trong Máy chủ PowerEdge XE8545.
Như thể hiện trong hình dưới đây, máy chủ PowerEdge R7525 có thể chứa tối đa ba GPU dựa trên PCIe; tuy nhiên, cấu hình được chọn cho đánh giá này đã sử dụng hai GPU A100-PCIe. Với tùy chọn này, giao tiếp giữa GPU với GPU phải đi qua các liên kết giữa các CPU của AMD Infinity Fabric.
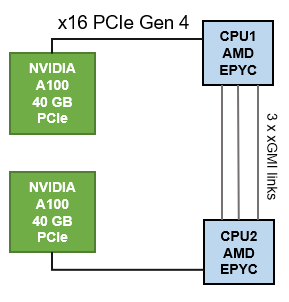
Hình 3: Kết nối CPU-GPU PowerEdge R7525
chi tiết thử nghiệm
Bảng sau hiển thị chi tiết cấu hình đã thử nghiệm:
Bảng 2: Chi tiết cấu hình giường thử nghiệm
| Người phục vụ | PowerEdge XE8545 | PowerEdge R7525 |
| bộ vi xử lý | AMD EPYC kép 7713, 64C, 2,8 GHz | |
| Kỉ niệm | 512GB
(16 x 32 GB @ 3200 tấn/giây) |
1024 GB
(16 x 64 GB @ 3200 tấn/giây) |
| Chiều cao của hệ thống | 4U | 2U |
| GPU | 4 x NVIDIA A100 SXM4 40 GB | 2 x NVIDIA A100 PCIe 40 GB |
| Hệ điều hành
hạt nhân |
Bản phát hành Red Hat Enterprise Linux 8.3 (Ootpa)
4.18.0-240.el8.x86_64 |
|
| cài đặt BIOS | Sysprofile=PerfOptimized
LogicalProcessor=Đã tắt NumaNodesPerSocket=4 |
|
| Trình điều khiển CUDA
Bộ công cụ CUDA |
450.51.05
11.1 |
|
| GCC | 9.2.0 | |
| Bộ KH&ĐT | OpenMPI – 4.0 | |
Bảng sau đây liệt kê phiên bản ứng dụng HPC được sử dụng để đánh giá điểm chuẩn:
Bảng 3: Các ứng dụng HPC được sử dụng để đánh giá
| điểm chuẩn | Thông tin chi tiết |
| HPL | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 |
| HPCG | xhpcg-3.1_cuda_11_ompi-3.1 |
| GROMACS | v2021 |
| NAMD | Git-2021-03-02_Source |
| ĐÈN | phát hành ngày 29 tháng 10 năm 2020 |
đánh giá điểm chuẩn
Linpack hiệu suất cao
High Performance Linpack (HPL) là điểm chuẩn hệ thống HPC tiêu chuẩn được sử dụng để đo sức mạnh tính toán của máy chủ hoặc cụm. Nó cũng được tổ chức TOP500 sử dụng làm tiêu chuẩn tham khảo để xếp hạng các siêu máy tính trên toàn thế giới. HPL cho GPU sử dụng các phép toán dấu phẩy động có độ chính xác gấp đôi. Có một số tham số quan trọng đối với điểm chuẩn HPL, như được liệt kê bên dưới:
- N là kích thước vấn đề được cung cấp làm đầu vào cho điểm chuẩn và xác định kích thước của ma trận tuyến tính được giải quyết bằng HPL. Đối với hệ thống GPU, hiệu suất HPL cao nhất đạt được khi kích thước sự cố sử dụng càng nhiều càng tốt bộ nhớ GPU mà không vượt quá nó. Đối với nghiên cứu này, chúng tôi đã sử dụng HPL được biên dịch với các thư viện NVIDIA như được liệt kê trong Bảng 3.
- NB là kích thước khối được sử dụng để phân phối dữ liệu. Đối với cấu hình thử nghiệm này, chúng tôi đã sử dụng NB là 288.
- PxQ là kích thước ma trận và bằng tổng số GPU trong hệ thống.
- Rpeak là đỉnh lý thuyết của hệ thống.
- Rmax là hiệu suất đo tối đa đạt được trên hệ thống.
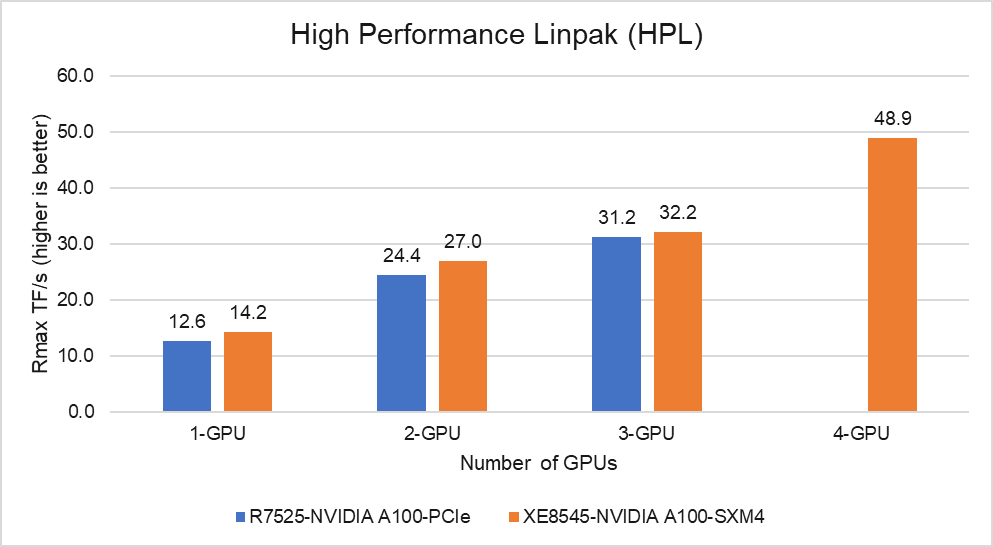
Hình 4: Hiệu suất HPL trên PowerEdge R7525 và XE8545 với NVIDIA A100-40 GB
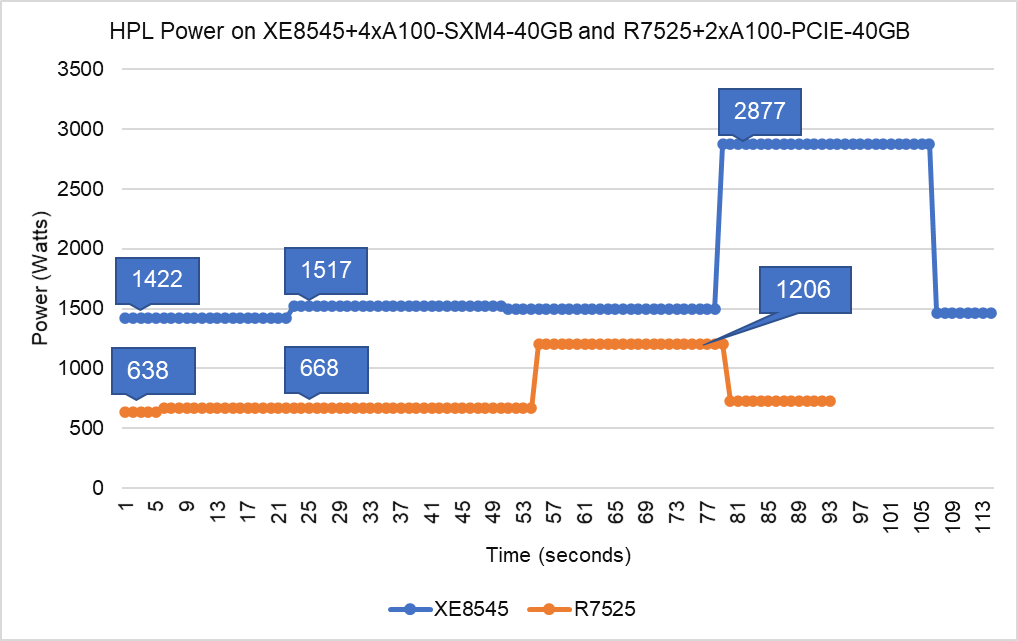
Hình 5: Sử dụng năng lượng HPL trên PowerEdge XE8545 với bốn GPU NVIDIA A100 và R7525 với hai GPU NVIDIA A100
Từ Hình 4 và Hình 5, chúng ta có thể nhận xét như sau:
- SXM4 so với PCIe: Ở 1-GPU, GPU NVIDIA A100-SXM4 vượt trội hơn A100-PCIe 11%. Tần số xung nhịp cơ bản của GPU SMX4 cao hơn là yếu tố chính góp phần vào hiệu suất bổ sung so với GPU PCIe.
- Khả năng mở rộng: Máy chủ PowerEdge XE8545 với bốn GPU NVIDIA A100-SXM4-40GB mang lại hiệu suất HPL cao hơn 3,5 lần so với một GPU NVIDIA A100-SXM4-40GB. Mặt khác, hai GPU A100-PCIe nhanh hơn 1,94 lần so với một trên nền tảng R7525. GPU A100 mở rộng tốt trên cả hai nền tảng cho điểm chuẩn HPL.
- Cao hơn Rpeak: Mã HPL trên GPU A100 sử dụng lõi Tensor có độ chính xác kép mới . Vì vậy, đỉnh lý thuyết cho mỗi thẻ sẽ là 19,5 TFlops, trái ngược với 9,7 TFlops.
- Nguồn điện : Hình 5 cho thấy mức tiêu thụ điện năng của một lần chạy HPL hoàn chỉnh với PowerEdge XE8545 sử dụng 4 GPU A100-SXM4 và PowerEdge R7525 sử dụng 2 GPU A100-PCIe. Điều này được đo bằng các lệnh iDRAC và mức tiêu thụ điện năng cao nhất của XE8545 là 2877 Watts, trong khi mức tiêu thụ điện năng cao nhất của R7525 là 1206 Watts.
Gradient liên hợp hiệu suất cao
Danh sách TOP500 đã kết hợp các kết quả Dải màu liên hợp hiệu suất cao (HPCG) làm thước đo thay thế để đánh giá hiệu suất hệ thống.
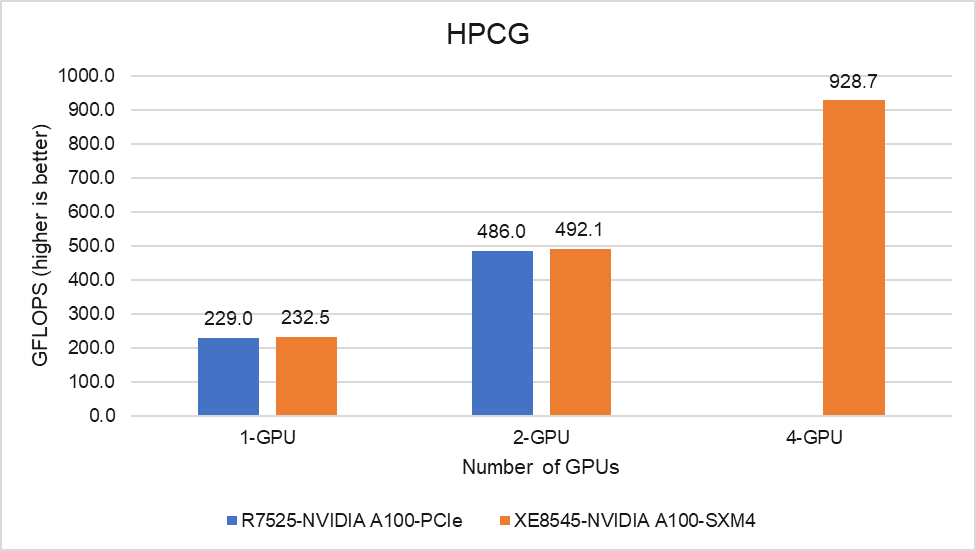
Hình 6: Hiệu suất HPCG trên Máy chủ PowerEdge R7525 và PowerEdge XE8545
Không giống như HPL, hiệu suất của HPCG phụ thuộc rất nhiều vào hệ thống bộ nhớ và hiệu suất mạng khi chúng tôi vượt ra ngoài một máy chủ. Bởi vì cả hai hệ số dạng PCIe và SXM4 của GPU A100 đều có cùng băng thông bộ nhớ, nên không có sự khác biệt về hiệu suất tại một nút duy nhất và hiệu suất HPCG cân bằng tốt trên cả hai máy chủ.
GROMACS
Hình dưới đây cho thấy kết quả hoạt động của GROMACS, một ứng dụng động lực học phân tử, trên máy chủ PowerEdge R7525 và XE8545. GROMACS 2021.0 được biên dịch với trình biên dịch CUDA và Open-MPI, như thể hiện trong Bảng 3.
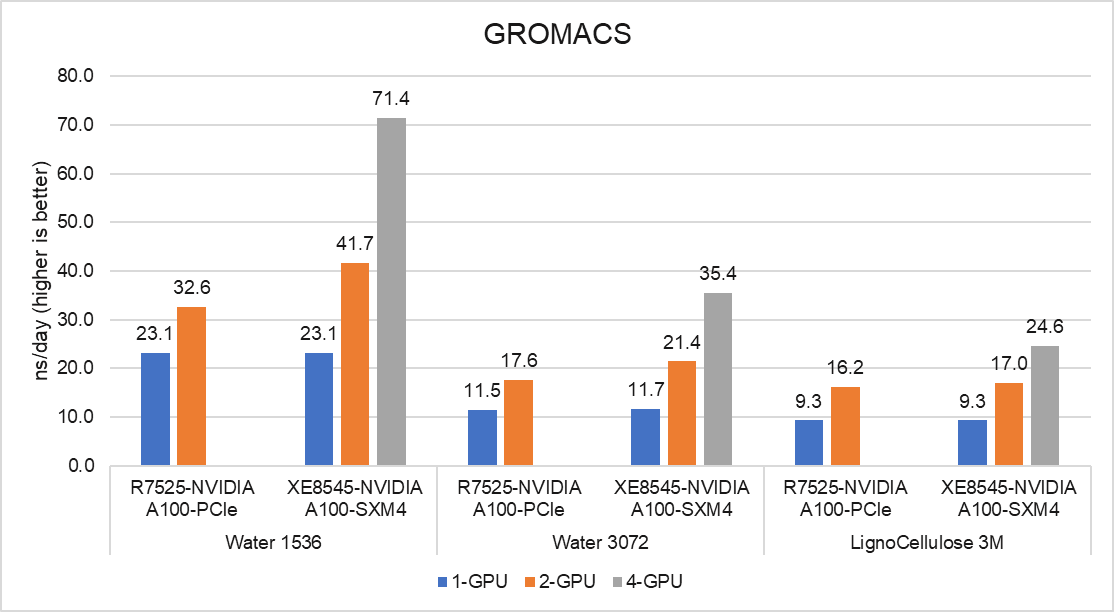
Hình 7: Hiệu suất GROMACS trên Máy chủ PowerEdge R7545 và PowerEdge XE8545
Bản dựng GROMACS bao gồm MPI luồng (được tích hợp với gói GROMACS). Kết quả hiệu suất được trình bày bằng chỉ số ns/ngày. Đối với mỗi thử nghiệm, hiệu suất được tối ưu hóa bằng cách thay đổi số thứ hạng MPI và luồng, số thứ hạng PME và các giá trị danh sách nstlist khác nhau để đạt được kết quả hiệu suất tốt nhất.
Với một GPU được thử nghiệm, hiệu suất của máy chủ SMX4 XE8545 tương tự như PCIe R7525. Với hai GPU được thử nghiệm, hiệu suất của SMX4 XE8545 tốt hơn tới 28% so với PCIe R7525. Vì hiệu suất dựa trên phân tích so sánh giữa các yếu tố hình thức NVIDIA PCIe và SXM4 dọc theo nền tảng máy chủ, các bộ dữ liệu như Water 1536 và Water 3072 yêu cầu nhiều giao tiếp GPU-GPU hơn và SXM4 hoạt động tốt hơn khoảng 28%. Mặt khác, đối với các bộ dữ liệu như LignoCellulose 3M, hai GPU R7525 đạt được hiệu suất trên mỗi GPU tương tự như XE8545, nhưng với GPU 250 W thấp hơn khiến nó trở thành giải pháp hiệu quả hơn.
ĐÈN
Hình dưới đây cho thấy kết quả hoạt động của LAMMPS, một ứng dụng động lực học phân tử, trên máy chủ PowerEdge R7525 và XE8545. Mã được biên dịch với gói KOKKOS để chạy hiệu quả trên GPU NVIDIA và Lennard Jones là tập dữ liệu đã được thử nghiệm với Dấu thời gian/s làm thước đo để so sánh.
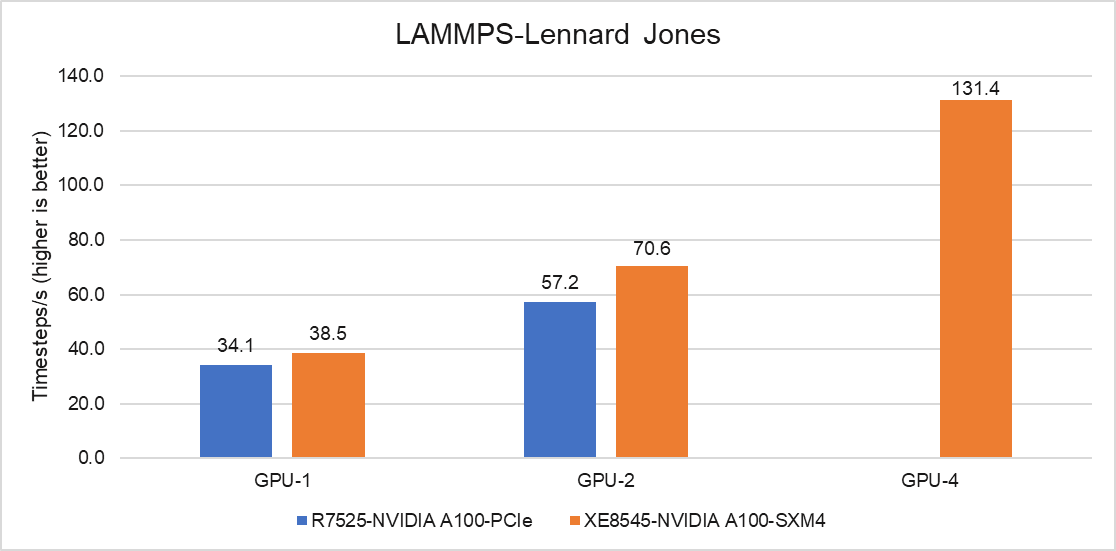
Hình 8: Hiệu suất LAMMPS trên Máy chủ PowerEdge R7545 và PowerEdge XE8545
Với một GPU trong thử nghiệm, hiệu suất của máy chủ SMX4 XE8545 cao hơn 13% so với PCIe R7525 và với hai GPU trong thử nghiệm, hiệu suất đã được cải thiện 23%. PowerEdge XE8545 có lợi thế hơn vì các GPU có thể giao tiếp với nhau qua NVLink mà không cần sự can thiệp của CPU. Máy chủ R7525 có hai GPU bị giới hạn bởi kiểu giao tiếp giữa GPU với GPU. Ngoài ra, yếu tố khác góp phần mang lại hiệu suất tốt hơn là tốc độ xung nhịp cao hơn của GPU SXM4 A100.
Sự kết luận
Trong blog này, chúng tôi đã thảo luận về hiệu suất của GPU NVIDIA A100 trên Máy chủ PowerEdge R7525 và Máy chủ PowerEdge XE8545, đây là phần bổ sung mới của Dell Technologies. GPU A100 có băng thông bộ nhớ cao hơn 42% và FLOP có độ chính xác kép cao hơn so với GPU tiền nhiệm của nó, GPU dòng V100. Đối với khối lượng công việc yêu cầu nhiều giao tiếp giữa GPU với GPU hơn, máy chủ PowerEdge XE8545 là một lựa chọn lý tưởng. Đối với các trung tâm dữ liệu có không gian và nguồn điện hạn chế, máy chủ PowerEdge R7525 có thể phù hợp. Hiệu suất tổng thể của Máy chủ PowerEdge XE8545 với bốn GPU A100-SXM4 nhanh hơn từ 1,5 đến 2,3 lần so với máy chủ PowerEdge R7525 với hai GPU A100-PCIe.
Trong tương lai, chúng tôi dự định sẽ đánh giá GPU A100-80GB và GPU NVIDIA A40 sẽ ra mắt trong năm nay. Chúng tôi cũng có kế hoạch tập trung vào nghiên cứu hiệu suất đa nút với các GPU này.






