
PowerEdge R750 Hiệu suất IOR tuần tự N máy khách thành 1 tệp
Hiệu suất của N máy khách tuần tự cho một tệp chia sẻ duy nhất được đo bằng IOR phiên bản 3.3.0, với OpenMPI 4.1.4rc1 để chạy điểm chuẩn trên 16 nút điện toán. Các thử nghiệm mà chúng tôi đã chạy đa dạng từ một luồng cho đến 512 luồng do không có đủ lõi cho 1024 luồng (16 máy khách có tổng cộng 16 x 2 x 20 = 640 lõi) và chi phí đăng ký quá mức ảnh hưởng một chút đến kết quả ở 1024 luồng.
Chúng tôi đã giảm thiểu hiệu ứng bộ nhớ đệm bằng cách đặt nhóm trang GPFS có thể điều chỉnh thành 32 GiB trên máy khách và 96 GiB trên máy chủ, đồng thời sử dụng tổng kích thước dữ liệu là 8 TiB, gấp đôi kích thước RAM từ máy chủ và máy khách cộng lại. Chúng tôi đã sử dụng kích thước truyền 16 MiB cho đặc tính hiệu suất này. Để có giải thích đầy đủ, hãy xem hiệu suất IOzone tuần tự N máy khách đến N tệp .
Các lệnh sau được sử dụng để chạy điểm chuẩn, trong đó biến Chủ đề là số lượng luồng được sử dụng (1 đến 512 tăng dần theo lũy thừa của 2) và my_hosts.$Threads là tệp tương ứng phân bổ mỗi luồng trên một nút khác nhau, sử dụng phương pháp quay vòng để trải chúng đồng nhất trên 16 nút tính toán. Biến FileSize có kết quả là 8192 (GiB)/Chủ đề để chia đều tổng kích thước dữ liệu cho tất cả các luồng được sử dụng.
mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –mca btl_openib_allow_ib 1 –mca pml ^ucx –oversubscribe –prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -w -s 1 -t 16m -b ${FileSize}G
mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –mca btl_openib_allow_ib 1 –mca pml ^ucx –oversubscribe –prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -r -s 1 -t 16m -b ${FileSize}G
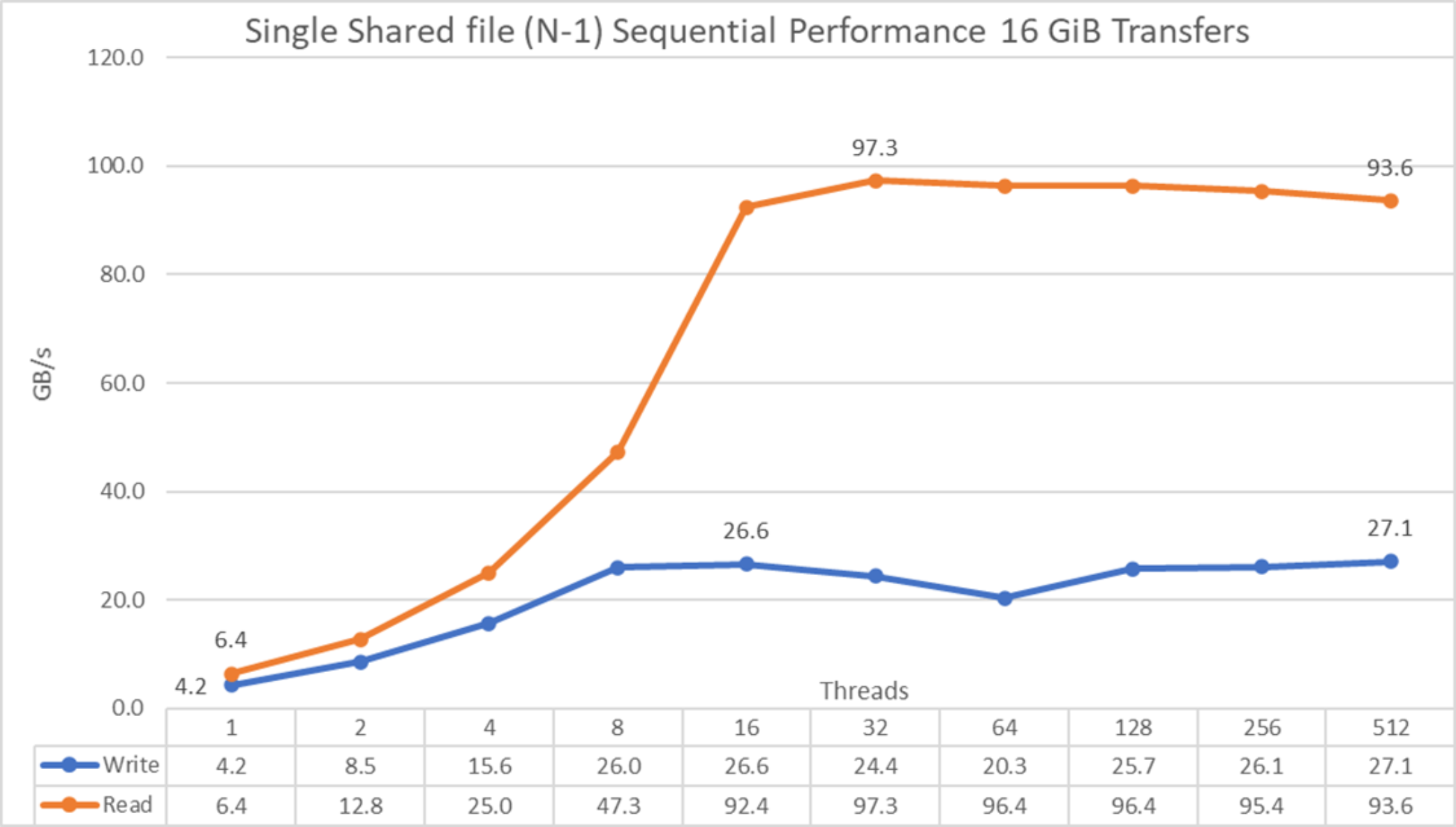
Hình 35. Hiệu suất tuần tự từ N đến 1
Từ kết quả, chúng tôi thấy rằng hiệu suất tăng lên nhanh chóng cùng với số lượng máy khách được sử dụng và sau đó đạt đến mức ổn định đối với các thao tác đọc ở khoảng 16 luồng và đối với các thao tác ghi ở 8 luồng, và chỉ còn lại một sự sụt giảm nhỏ đối với các thao tác đọc khi số lượng chủ đề tăng lên. Hiệu suất đọc tối đa là 97,3 GB/giây ở 32 luồng và để ghi là 27,1 GB/giây ở 512 luồng. Lưu ý rằng hiệu suất tăng nhanh hơn so với các thử nghiệm NN, điều này có thể là do có thêm sáu thiết bị trên mỗi máy chủ (so với máy chủ PowerEdge R650) để phân phối dữ liệu, truy cập MPI cộng với IOR hiệu quả hơn cho các thao tác ghi so với IOzone hoặc một số lý do khác điều đó không rõ ràng. Cần điều tra thêm về hành vi này.
PowerEdge R750 Các khối nhỏ ngẫu nhiên Hiệu suất IOzone N máy khách thành N tệp
Hiệu suất N máy khách ngẫu nhiên đến N tệp được đo bằng IOzone phiên bản 3.492. Các thử nghiệm mà chúng tôi đã chạy đa dạng từ 1 đến 1024 luồng, sử dụng 4 khối KiB để mô phỏng lưu lượng khối nhỏ. Chúng tôi đã giảm thiểu hiệu ứng bộ nhớ đệm bằng cách đặt nhóm trang GPFS có thể điều chỉnh thành 16 GiB trên máy khách và 32 GiB trên máy chủ và sử dụng tổng kích thước dữ liệu là 128 GiB.
Lệnh sau được sử dụng để chạy điểm chuẩn ở chế độ IO ngẫu nhiên cho cả thao tác đọc và ghi, trong đó biến Chủ đề là số lượng luồng được sử dụng (từ 1 đến 1024 tăng dần theo lũy thừa của 2) và danh sách luồng là tệp đã phân bổ mỗi luồng luồng trên một nút khác, sử dụng tính năng quay vòng để trải chúng đồng nhất trên 16 nút tính toán.
./iozone -i0 -c -e -w -r 16M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i2 -O -w -r 4K -s ${Size}G -t $Threads -+n -+m ./threadlist
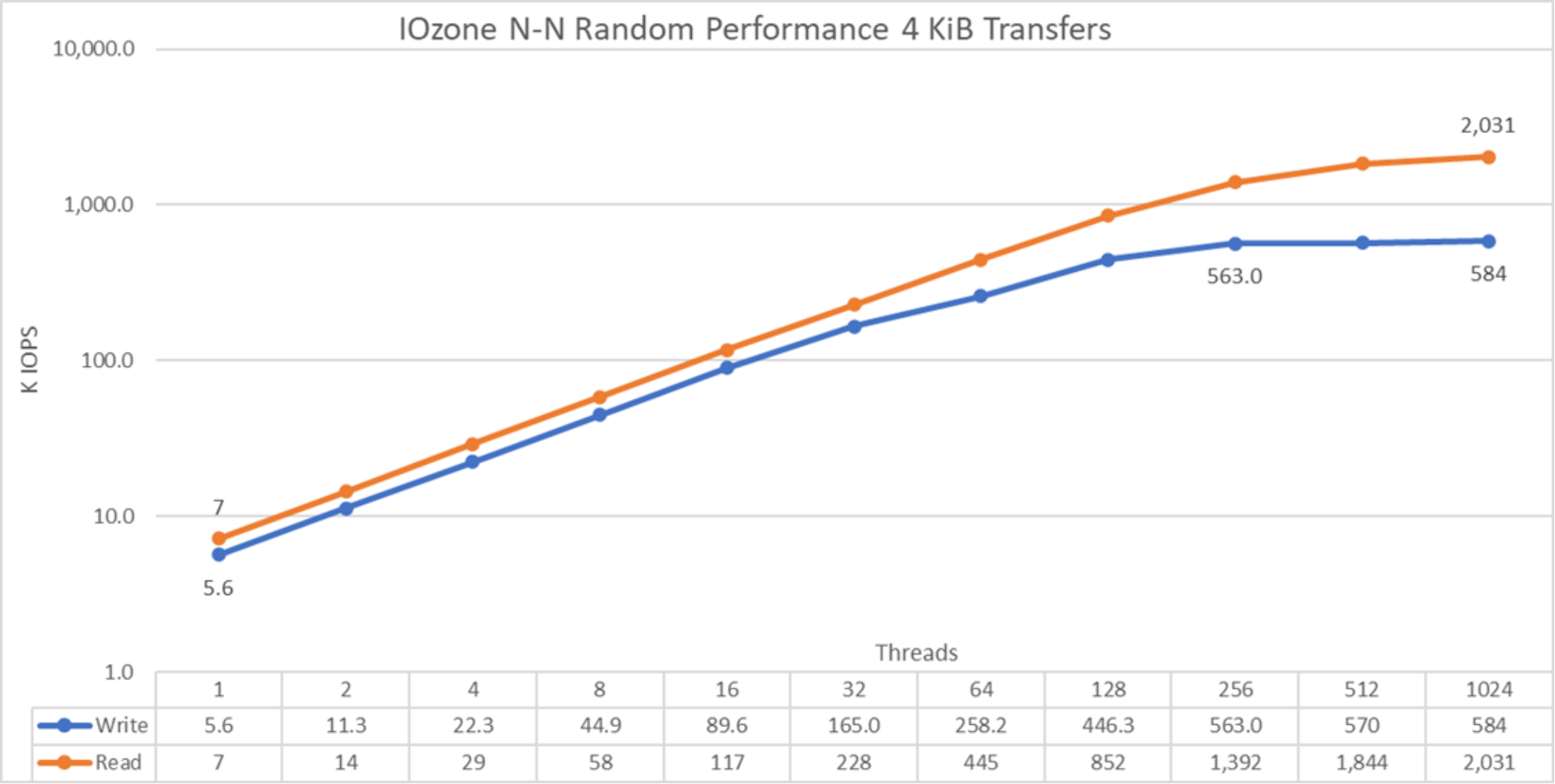
Hình 36. Hiệu suất ngẫu nhiên N đến N
Lưu ý rằng thang đo được chọn là logarit với cơ số 10, để cho phép so sánh các hoạt động có sự khác biệt theo một số bậc độ lớn; mặt khác, một số hoạt động xuất hiện giống như một đường phẳng gần bằng 0 trên biểu đồ bình thường. Biểu đồ logarit với cơ số 2 phù hợp hơn vì số luồng tăng theo lũy thừa của 2. Biểu đồ như vậy trông giống nhau, nhưng mọi người có xu hướng nhận thức và ghi nhớ các số dựa trên lũy thừa của 10 tốt hơn.
Từ kết quả, chúng tôi thấy rằng hiệu suất ghi bắt đầu ở giá trị cao khoảng 5,6K IOPS và tăng lên mức cao nhất là 560K IOPS ở khoảng 256 luồng và tối đa là 584K IOPS ở 1024 luồng. Hiệu suất đọc bắt đầu ở 7K IOPS và tăng hiệu suất theo số lượng máy khách được sử dụng cho đến khi đạt hiệu suất tối đa là 2.031K IOPS ở 1024 luồng có dấu hiệu sắp ổn định. Tuy nhiên, như đã giải thích trước đây, việc sử dụng nhiều luồng hơn trên 16 nút tính toán hiện tại so với số lượng lõi (640) có hạn chế là phát sinh nhiều chuyển đổi ngữ cảnh hơn, điều này có thể hạn chế hiệu suất cao nhất. Một thử nghiệm trong tương lai với nhiều nút tính toán vật lý hơn có thể kiểm tra hiệu suất đọc ngẫu nhiên có thể đạt được với 1024 luồng với Iozone
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...